【JavaEE】多线程(三)
多线程(三)
续上文,多线程(二),我们已经讲了
- 创建线程
Thread的一些重要的属性和方法
那么接下来,我们继续来体会了解多线程吧~
文章目录
- 多线程(三)
-
- 线程启动 start
-
- start与run的区别
- 中断线程 interrupt
-
- 方法一
- 方法二
- 线程等待 join
- 线程状态
- 线程安全
-
- 线程安全问题的原因
- synchronized
线程启动 start

其实在之前的两篇文章中我,我们就见识过线程启动,也就是t.start();,其实也就是start方法。
start方法内部,实际上是调用了系统api,在系统内核创建线程。
而我们随之见识的t.run(); 也就是run方法,它只是单纯的描述了该线程要执行什么内容,是会在start创建好线程之后自动被调用的~
start与run的区别
虽然我们看起来的效果是相似的,实际上本质上的区别就是在于是否是系统内部创建出的新的线程
中断线程 interrupt
所谓中断线程,也就是任一个线程停止运行(销毁),而在Java中,要销毁/终止进程,做法是比较唯一的,就是让run方法早点结束。(不过在C++中,他是有能力直接强行终止一个正在运行的进程的,好暴力的呢,不过就会导致线程活干一半,环境会残留一些数据~)
所以我们还是就Java来看(Java生态多好~)
方法一
可以在代码中手动创建出标志位,来作为run方法执行结束的循环
很多线程,执行时间久,往往就是因为写了一个循环,循环要持续执行,所以要想让run执行结束,就是让循环尽快退出~
见以下代码:
public class Demo8 {
private static boolean isQuit = false;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() ->{
while (!isQuit){
//此处的打印可以替换成任意的逻辑来表示线程的实际工作内容
System.out.println("线程工作中");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程工作完毕");
});
t.start();
Thread.sleep(5000);
isQuit = true;
System.out.println("已过5s 设置 isQuit 为 true");
}
}
这里我们是设了一个成员变量isQuit来作为标志位~
这里我们抛出一个疑问,要是我们将isQuit改成main方法内的局部变量,此时的程序是否还能完成中断操作?
public class Demo8_change {
//private static boolean isQuit = false;
public static void main(String[] args) throws InterruptedException {
boolean isQuit = false;
Thread t = new Thread(() ->{
while (!isQuit){
//此处的打印可以替换成任意的逻辑来表示线程的实际工作内容
System.out.println("线程工作中");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程工作完毕");
});
t.start();
Thread.sleep(5000);
isQuit = true;
//常量变了
System.out.println("已过 5s 设置 isQuit 为 true");
}
}
哈哈,程序报错了
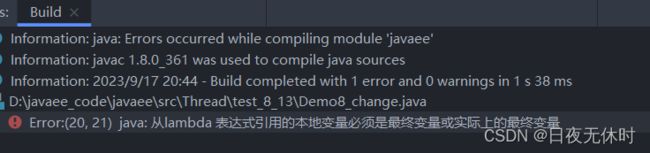
为什么呢?
这其实就是线程和主线程在读取和写入isQuit变量时没有使用同步机制,这也涉及到了lambda表达式中的一个语法规则,变量捕获。
lambda表达式里面的代码,是可以自动捕获到上层作用域涉及到的局部变量的,也就是我们上面代码中的isQuit。所谓的变量捕获,就是让lambda表达式把当前作用域中的变量在lambda内部复制了一份(此时外部是否销毁,无所谓)
而且在Java中,变量捕获语法,还有一个前提:就是必须只能捕获一个final或者实际上是final的值。
boolean isQuit = false;虽然没有使用final,但是却没有实际修改内容,他就是实际上的final~
下面举个例子再了解了解:
public class VariableCaptureExample {
public static void main(String[] args) {
int num = 10; // 外部作用域的局部变量
// 使用Lambda表达式引用外部作用域的变量
Runnable r1 = () -> {
System.out.println(num); // 引用外部作用域的变量
};
r1.run(); // 输出结果为:10
// 使用内部类引用外部作用域的变量
Runnable r2 = new Runnable() {
@Override
public void run() {
System.out.println(num); // 引用外部作用域的变量
}
};
r2.run(); // 输出结果为:10
}
}
在上述示例中,Lambda表达式和内部类都引用了外部作用域中的变量num。当Lambda表达式或内部类被创建时,变量num会被捕获并保存在生成的对象中,以供后续使用。
需要注意的是,被捕获的局部变量应当是有效的(final或事实上的final)。如果在Lambda表达式或内部类中尝试修改被捕获的变量,将会导致编译错误。例如,在上述示例中,如果尝试修改num的值,编译器就会报错。这是因为被捕获的局部变量应当保持不可变,以确保代码的一致性。
当然,此处Java的设定,并不够科学。这里的final的限制,很多时候是个比较麻烦的事情,相比之下,JS这里的设定更合适一些.lambda(不只是lambda)都是可以捕获外部的变量(JS天然就有一个作用域链),可以保证捕获的变量是同一个变量,并且会自动的调整变量的生命周期.
方法二
调用 interrupt() 方法来通知
不过要中断进程,方法一显然不太优雅~因为它:
- 需要手动创建变量
- 当线程内部在
sleep的时候,主线程修改变量,新线程内部不能及时响应
见以下例子
// 线程终止 - 优雅的方式
public class Demo9 {
public static void main(String[] args) {
Thread t = new Thread(()->{
//Thread 类内部,有一个现成的标志位,可以用来判定当前的循环是否要结束
while (!Thread.currentThread().isInterrupted()){
System.out.println("线程工作中");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("让 t 线程终止");
t.interrupt();
}
}
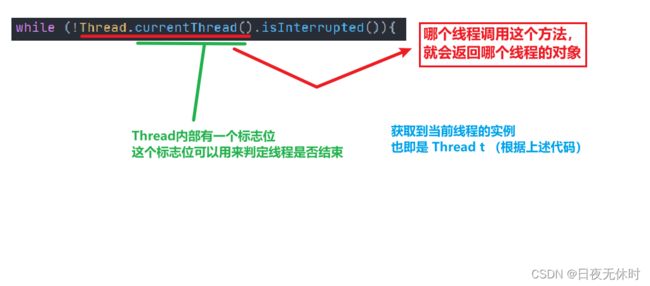
而 t.interrupt();这个操作,就是将上述代码的Thread对象内部的标志位设置为true
同时即使线程内部出现阻塞sleep,也是可以用这个方法唤醒的~
正常来说,sleep会休眠到时间到,才能唤醒,此处给出的interrupt就可以使sleep内部触发一个异常,从而提前被唤醒
而方法一中我们自己手动定义标志位,无法实现这个效果的~
我们看看上述代码的运行效果
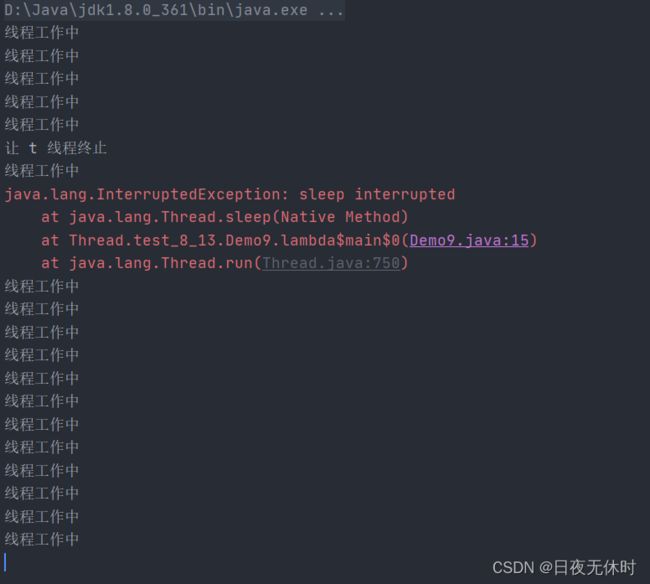
oh,my god~异常确实是报出来了,但是上述的线程t依然在运行,它并没有真的结束。
实际上,这是因为interrupt唤醒线程之后,同时会清除刚才设置的标志位,这样就会导致我们刚才“设置标志位”这样的效果好像没生效一样~
正式一点来说就是:因为线程在执行Thread.sleep()方法时,会抛出InterruptedException异常。当t线程抛出该异常时,catch块中的代码会被执行,并且线程的中断状态会被重置为false。因此,尽管主线程调用了t.interrupt()方法,但此时线程的中断状态为false,所以t线程可以继续正常运行。
实际上这样的设定也是有它的道理所在:
这样的设计是为了给线程处理中断的机会,通过捕获InterruptedException异常,线程可以在收到中断信号时进行必要的清理工作,并使用自定义逻辑来决定是否立即停止线程。
也就是让我们有更多的操作空间,而可操作空间的前提就是通过“异常”方式唤醒的。
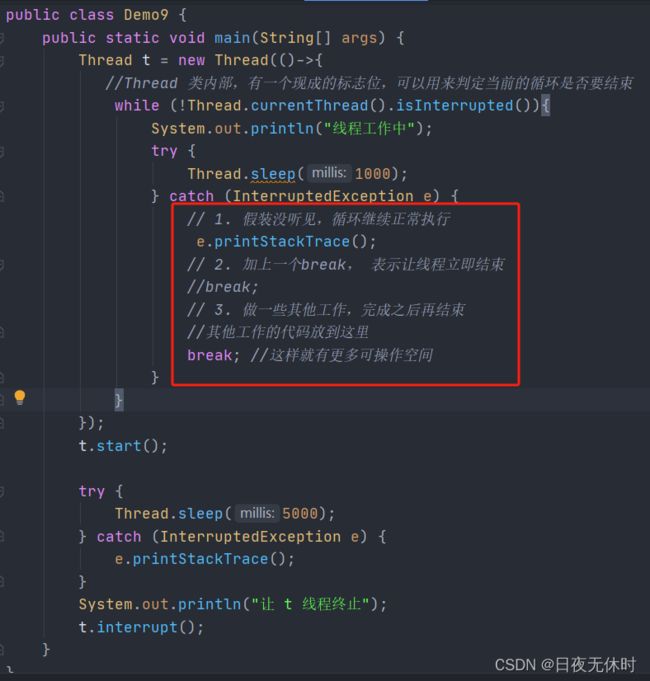
因此如果希望t线程在收到中断信号后立即终止,我们可以在catch块中使用break;语句来跳出循环,以实现快速结束线程。
线程等待 join
让一个线程等待,等待另一个线程执行结束,再继续执行,本质上就是控制线程结束的顺序~
join就是实现线程等待的效果,在主线程中调用t.join();此时就是主线程等待t线程先结束。
join的工作过程:
- 如果
t线程正在运行中,此时调用join的线程就会阻塞,一直阻塞到t线程执行结束为止 - 如果
t线程已经执行结束了,此时调用join线程,就直接返回,不会涉及到阻塞~
public class Demo10 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 5; i++) {
System.out.println(" t 线程工作中");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
//让主线程来等待 t 线程执行结束
//一旦调用 join,主线程就会触发阻塞, 此时 t 线程就会趁机完成后续的工作
//一旦阻塞到 t 执行完毕了,join才会解除阻塞,继续执行
System.out.println("join 开始等待");
t.join(1000);//最好是有时间等待,不要死等
System.out.println("join 等待结束");
}
}
/*
join 开始等待
t 线程工作中
t 线程工作中
join 等待结束
t 线程工作中
t 线程工作中
t 线程工作中
/*
这里举个例子:
有一天我约女神出来,19:00在学校门口碰头~~
-
如果我先到了,发现女神还没来,就要阻塞等待,等到女神来了之后,我俩就可以一起去了.
-
女神先到了.当我来到校门口的时候,虽然时间还不到
19:00,但是我看到女神已经在了.此时我俩直接出发去就可以了.就不需要等待 -
我来了之后,等了很久,女神还没出现,我仍然继续等.…
join默认是"死等",“不死不休”)
一般来说,等待操作都是带有一个"超时时间”
sleep有一定的调度开销
//证明sleep(1000)实际上并不精确
public class Demo11 {
public static void main(String[] args) throws InterruptedException {
/*
System.out.println("开始: " + System.currentTimeMillis());
Thread.sleep(1000);
System.out.println("结束: " + System.currentTimeMillis());
*/
long beg = System.currentTimeMillis();
Thread.sleep(1000);
long end = System.currentTimeMillis();
System.out.println("时间:" + (end - beg) + "ms");
}
}
//时间:1009ms
系统会按照1000ms这个时间来控制让线程休眠
但是当1000ms时间到了之后,系统会唤醒这个线程(阻塞 -> 就绪)
但是不是说这个线程就成了就绪状态,就能够立即回到cpu上运行,(因为这中间会有一个“调度”的开销)
对于windows和Linux这些系统来说,调度开销是很大的,可能会达到ms级别
线程状态
进程的状态,最核心的,一个是就绪状态,阻塞状态.(对于线程同样适用)
以线程为单位进行调度的.
在Java中,又给线程赋予了一些其他的状态
NEW:安排了工作,还未开始行动,Thread对象有了,start方法还没调用TERMINATED:工作完成了,Thread对象还在,内核中的进程已经没了RUNNABLE:可工作的.又可以分成正在工作中和即将开始工作,就绪状态(线程已经在cpu上执行了/线程正在排队等待上cpu执行)TIMED_WAITING:这几个都表示排队等着其他事情,阻塞,由于sleep这种固定时间的方式产生的阻塞WAITING:这几个都表示排队等着其他事情,由于wait这种不固定时间的方式产生的阻塞BLOCKED:这几个都表示排队等着其他事情,由于所竞争导致的阻塞
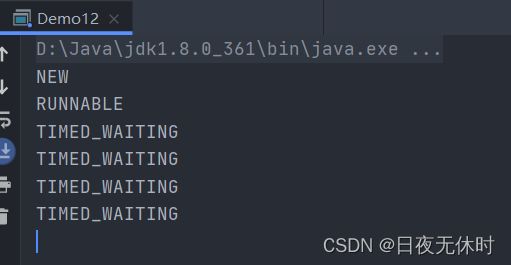
public class Demo12 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 在调用 start 之前获取状态, 此时就是 NEW 状态
System.out.println(t.getState());
t.start();
for (int i = 0; i < 5; i++) {
System.out.println(t.getState());
Thread.sleep(1000);
}
t.join();
// 在线程执行之后,获取线程的状态,此时是 TERMINATED 状态
System.out.println(t.getState());
}
}

线程安全
所谓的线程安全,就是说有些代码在单个线程环境中执行,是完全正确的,但是如果是相同的代码,让其在多个线程的环境中去同时执行,此时就会出现bug,这也就是线程安全问题~
下面给出示例代码:
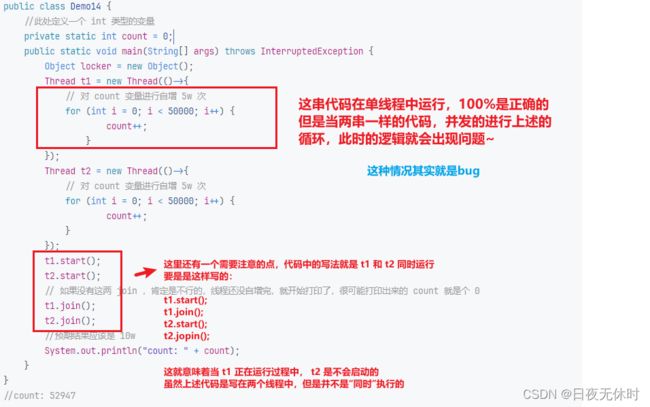
public class Demo14 {
//此处定义一个 int 类型的变量
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
// 对 count 变量进行自增 5w 次
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2 = new Thread(()->{
// 对 count 变量进行自增 5w 次
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
// 如果没有这两 join ,肯定是不行的,线程还没自增完,就开始打印了,很可能打印出来的 count 就是个 0
t1.join();
t2.join();
//预期结果应该是 10w
System.out.println("count: " + count);
}
}
//count: 52947
以上的代码就是非常典型的线程安全问题~
所以在解决这个bug'前,我们要知道count++的本质~
count++的本质上是分三步操作的,站在cpu的角度上,count++是由cpu通过三个指令来实现的:
load:把数据从内存读取到cpu寄存器中add:把寄存器中的数据进行+1save:把寄存器中的数据,保存到内存中
如果是多个线程执行上述代码,由于线程之间的调度顺序,是"随机”的,就会导致在有些调度顺序下,上述的逻辑就会出现问题.
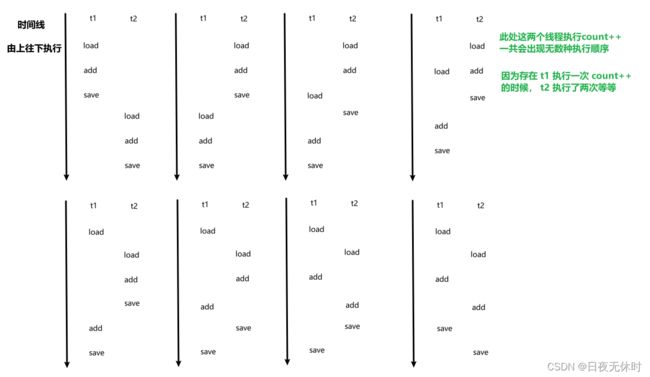
结合上述讨论,就意识到了,在多线程程序中,最困难的一点:
线程的随机调度,使两个线程执行逻辑的先后顺序,存在诸多可能.
我们必须要保证在所有可能的情况下,代码都是正确的!!
在解决这个问题之前,我们得知道产生线程安全问题的原因是什么:
线程安全问题的原因
-
操作系统中,线程的调度顺序是随机的(抢占性执行),这也就是万恶之源
-
两个线程,针对同一个变量进行修改(有些情况我们是可以通过修改代码结构来规避上述问题,但是也有很多情况是调整不了的)
-
修改操作,不是原子的
此处给的
count++就属于是非原子操作(先读,再修改)类似的,如果在一段逻辑中,需要根据一定的条件来决定是否修改,也是存在类似问题
(假设
count++是原子的,也就是说有一个cpu指令可以一次完成上述的count++三步操作) -
内存可见性问题
-
指令重排序问题
那么知道了原因,我们就有相对应的解决方法了~
我们的思路就是:
- 通过修改代码结构来规避上述问题,虽然也有很多情况是调整不了的
- 想办法让
count++的三步走变成原子性的
那么这里我们就选择:加锁!!!!!!!!!
最常用的方法就是synchronized关键字
synchronized
synchronized是Java中的关键字,用于实现线程的同步。它可以应用于方法或代码块上。
所以synchronized在使用的时候,我们需要搭配一个代码块{}
这样子进入{就会加锁,出}就会解锁
在已经加锁的状态中,另一个线程尝试同样加这个锁,就会产生“锁冲突/锁竞争”,后一个线程就会阻塞等待,一直等到前一个线程解锁为止~
所以这里我们给出修改后的代码:
public class Demo13 {
//此处定义一个 int 类型的变量
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Object locker = new Object();
Thread t1 = new Thread(()->{
// 对 count 变量进行自增 5w 次
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
Thread t2 = new Thread(()->{
// 对 count 变量进行自增 5w 次
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
// t1.start();
// t2.start();
// 如果没有这两 join ,肯定是不行的,线程还没自增完,就开始打印了,很可能打印出来的 count 就是个 0
// t1.join();
// t2.join();
//改进:>
t1.start();
t1.join();
t2.start();
t2.join();
System.out.println("count: " + count);
//100000
//在原来的代码中,t1.start()和t2.start()的顺序是固定的,不论t1和t2线程的逻辑如何,主线程会立即启动两个新线程,然后等待它们执行完毕。这种方式适用于两个线程之间没有依赖关系的情况。
//因此,改变t1.start()和t2.start()的调用顺序以及使用join()方法,可以控制线程的执行顺序和依赖关系,满足具体的业务需求。
}
}
//count: 100000
如果两个线程是在针对同一个对象加锁,就会有锁竞争
如果不是针对同一个对象加锁,就不会有锁竞争,仍然是并发执行!
我们举个例子:
把锁当作一个小妹妹,你去表白,成功了,妹子到手了,也相当于你给妹子加锁了,这时候别的男的他想要你的小妞,他就得阻塞等待,等你们分手了,他才能接盘(排除妹子绿你的情况哈~)
但是那个男的去追别的女生,就不会受你的影响(除非你这人遍地撒花~)
如图:

至此,多线程(三)暂时讲到这里,这里暂时synchronized开了个头,接下来会继续更新,敬请期待~