【深度学习】卷积神经网络(LeNet)【文章重新修改中】
卷积神经网络 LeNet
- 前言
- LeNet 模型
- 代码实现
-
- MINST
-
- 代码分块解析
-
- 1 构建 LeNet 网络结构
- 2 加载数据集
- 3 初始化模型和优化器
- 4 训练模型
- 5 训练完成
- 完整代码
- Fashion-MINST
-
- 代码分块解析
-
- 1 构建 LeNet 网络结构
- 2 初始化模型参数
- 3 加载数据集
- 4 定义损失函数和优化器
- 5 训练模型
- 完整代码
- 参考与更多阅读材料
前言
全连接神经网络,也称多层感知机, M L P MLP MLP,是深度学习最基本的神经网络之一。它包含输入层,多个隐藏层和输出层,每一层都与前一层的每个神经元相连接。尽管全连接神经网络具有一定的表达能力,其并不是解决所有问题的最佳工具。
e . g . e.g. e.g. 假设我们有一张 1000 ∗ 1000 1000 * 1000 1000∗1000 像素的彩色照片,假设全连接层输出个数为 256 256 256,那么该层权重参数的形状是 3000000 ∗ 256 3 000 000 * 256 3000000∗256,即会占用 3 G B 3GB 3GB 的内存或显存。会导致复杂的模型与过高的存储开销。
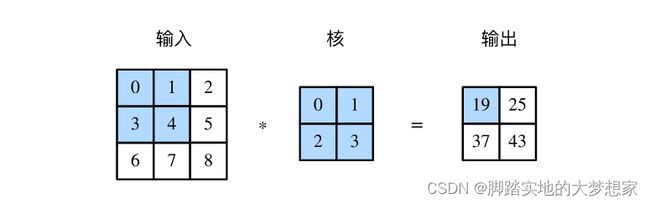
卷积层试图解决这个问题。卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。而卷积神经网络,就是包含卷积层的网络。
LeNet 作为早期用来识别手写数字图像的卷积神经网络,名称来源于 Yann LeCun。其展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当时最先进的结果。
LeNet 模型

LeNet 模型分为卷积层块和全连接层块两个部分;
卷积层块里的基本单位是卷积层后接最大池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的最大池化层则是用来降低卷积层对位置的敏感性。卷积层,由这两个基本单位重复堆叠构成。
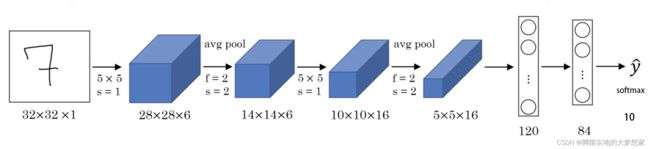
具体来说,在每个卷积层块中,每个卷积层都使用 5 ∗ 5 5*5 5∗5 的窗口,并在输出上使用 s i g m o i d sigmoid sigmoid 激活函数;第一个卷积层输出通道数为 6 6 6,第二个卷积层输出通道数增加到 16 16 16。卷积层块的两个最大池化层的窗口形状均为 2 ∗ 2 2*2 2∗2,且步幅为 2 2 2。
代码实现
MINST

代码分块解析
1 构建 LeNet 网络结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 1个输入通道,6个输出通道,卷积核大小为5x5
self.pool = nn.MaxPool2d(2, 2) # 最大池化层,2x2窗口
self.conv2 = nn.Conv2d(6, 16, 5) # 6个输入通道,16个输出通道,卷积核大小为5x5
self.fc1 = nn.Linear(16*4*4, 120) # 全连接层1
self.fc2 = nn.Linear(120, 84) # 全连接层2
self.fc3 = nn.Linear(84, 10) # 输出层,10个类别
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16*4*4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
x = torch.softmax(x, dim=1)
return x
- 代码解释
super(LeNet, self).__init__() 是 python 中用于调用父类(或超类)的构造函数的一种方式。在上述定义中,用于在子类 LeNet 的构造函数中调用父类 nn.model 的构造函数。
具体来说:
super(LeNet, self)使用了super()函数创建了一个与子类LeNet相关联的super对象。这个super对象可以用来访问父类的方法和属性。.__init__()调用super对象的构造函数,即调用父类nn.model的构造函数。确保子类super继承父类nn.model的所有属性和方法。
总之,super(LeNet, self).__init__() 目的是在子类 LeNet 的构造函数中初始化父类 nn.model。这是面向对象编程中用于构建继承层次结构中的子类。
- 代码解释
forward(self, x) 是神经网络中定义前向传播的方法。这个方法定义了一个张量 x,按照 LeNet 网络的结构将其传递给不同层,最终计算出网络的输出。
具体来说:
x = self.pool(torch.relu(self.conv1(x)))首先,输入x经过第一个卷积层self.conv1(x),然后使用 ReLU 激活函数进行激活,接着使用self.pool进行最大池化操作;x = self.pool(torch.relu(self.conv2(x)))然后,将前一步的输出再次经过第二个卷积层self.conv2,然后使用 ReLU 激活函数进行激活,接着使用self.pool进行最大池化操作;x = x.view(-1, 16*5*5)在进入到全连接层前,需要将池化层的输出展平为一维向量,通过view函数实现方法:
e . g . e.g. e.g. 如果x的形状是 [ 64 , 16 , 5 , 5 ] [64, 16, 5, 5] [64,16,5,5](其中 batch_size 是 64,num_channels 是16,height 和 width 都是 5 ),那么x.view(-1, 16 * 5 * 5)将会将x的形状调整为 [ 64 , 16 ∗ 5 ∗ 5 ] [64, 16 * 5 * 5] [64,16∗5∗5],也就是 [ 64 , 400 ] [64, 400] [64,400],作为全连接层的输入。x = torch.relu(self.fc1(x))将展平后的数据传递给第一个全连接层self.fc1,然后使用 ReLU 函数进行激活;x = torch.relu(self.fc2(x))将第一个全连接层的输出传递给第二个全连接层self.fc2,然后使用 ReLU 函数进行激活;x = self.fc3(x)x = torch.softmax(x, dim=1)最后将第二个全连接层的输出传递给输出层self.fc3,使用 softmax 获得概率分布;Softmax 将网络的原始输出值转化为 0 到 1 之间的概率值,以表示每个类别的预测概率。
2 加载数据集
# 数据标准化处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 加载数据集
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# 创建数据加载器 Loader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
- 代码解释
transforms.ToTensor() 将图像从 PIL 图像对象转换为 PyTorch 张量,深度学习模型使用张量作为输入;
- 代码解释
transforms.Normalize((0.5,), (0.5,)) 对图像进行归一化操作。
参数 (0.5,) 与 (0.5,) 表示均值和标准差,将图像像素值从 0 到 255 缩放到 -1 到 1 之间,以加速模型的训练过程。对于 MINST 数据集来说,因为只有一个通道(灰度图像),因此只有一个均值和一个标准差。
3 初始化模型和优化器
# 实例化网络对象
net = LeNet()
# 损失函数使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 优化器,使用随机梯度下降
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
- 代码解释
CrossEntropyLoss() 交叉熵损失函数:通常用于多类别分类任务,例如图像分类。
- 代码解释
optim.SGD 即使用随机梯度下降作为优化器,SGD(Stochastic Gradient Descend)
net.parameters() 代表优化器会将神经网络中所有可学习参数不断更新权重;
lr 即 learning rate 学习率,控制优化器每次权重更新的步长;
momentum=0.9 动量,关于动量的概念将在后期单独出一期博文解析,读者在这里可以得知的是动量是一种加速优化过程的技巧,有助于跳出局部最小值。
4 训练模型
for epoch in range(10): # 遍历数据集 10 次
running_loss = 0.0 # 损失值
for i, data in enumerate(trainloader, 0):
# 每个批次中,数据data包含了输入inputs和相应的标签labels
inputs, labels = data
# zero_grad 方法将优化器中的梯度清零,计算新的梯度
optimizer.zero_grad()
# 将输入数据传递给神经网络 net 进行前向传播,计算模型的输出 outputs
outputs = net(inputs)
# 计算模型的输出与真实标签之间的损失
loss = criterion(outputs, labels)
# 根据损失值计算梯度,使用反向传播算法
loss.backward()
# 使用优化器 optimizer 更新网络的参数,减小损失值
optimizer.step()
# 将损失值累积到 running_loss 中
running_loss += loss.item()
if i % 200 == 199: # 每 200 批次打印一次损失
# {i + 1:5d} 是一种字符串格式化的语法,用于将整数 i + 1 格式化为宽度为5的右对齐整数。
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
5 训练完成
print('Finished Training')
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 定义LeNet模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 1个输入通道,6个输出通道,卷积核大小为5x5
self.pool = nn.MaxPool2d(2, 2) # 最大池化层,2x2窗口
self.conv2 = nn.Conv2d(6, 16, 5) # 6个输入通道,16个输出通道,卷积核大小为5x5
self.fc1 = nn.Linear(16*4*4, 120) # 全连接层1
self.fc2 = nn.Linear(120, 84) # 全连接层2
self.fc3 = nn.Linear(84, 10) # 输出层,10个类别
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16*4*4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
x = torch.softmax(x, dim=1)
return x
# 加载数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 初始化模型和优化器
net = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(10): # 遍历数据集10次
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199: # 每200批次打印一次损失
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
print('Finished Training')
Fashion-MINST

代码分块解析
1 构建 LeNet 网络结构
net = nn.Sequential()
net.add(
nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Dense(120, activation='sigmoid'),
nn.Dense(84, activation='sigmoid'),
nn.Dense(10)
)
使用 nn.Sequential() 创建 LeNet 模型,包括卷积层、池化层和全连接层,其中激活函数为 sigmoid。
2 初始化模型参数
ctx = d2l.try_gpu()
# force_reinit在初始化之前强制重新初始化模型参数
# init.Xavier有助于避免梯度消失和梯度爆炸,提高模型的收敛速度
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
3 加载数据集
# 加载Fashion-MNIST数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)
4 定义损失函数和优化器
# 定义损失函数和优化器
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.9})
使用交叉熵损失函数来计算损失,使用梯度随机下降优化器 sgd 进行模型参数的优化。
5 训练模型
# 训练模型
num_epochs = 10
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
完整代码
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
# 定义LeNet模型
net = nn.Sequential()
net.add(
nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Dense(120, activation='sigmoid'),
nn.Dense(84, activation='sigmoid'),
nn.Dense(10)
)
# 初始化模型参数
ctx = d2l.try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
# 加载Fashion-MNIST数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)
# 定义损失函数和优化器
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.9})
# 训练模型
num_epochs = 10
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
参考与更多阅读材料
- https://www.analyticsvidhya.com/blog/2021/03/the-architecture-of-lenet-5/
- https://zhuanlan.zhihu.com/p/459616884