Hive 三种连接方式(CLI、HiveServer2/beeline(常用)、Web UI)及基本命令使用入门
Hive 三种连接方式(CLI、HiveServer2/beeline(常用)、Web UI)及基本命令使用入门
- 1、Hive 使用方式,即三种连接方式
-
- 1.1、CLI
- 1.2、HiveServer2/beeline(常用)
- 1.3、Web UI
- 2、Hive 基本使用(入门)
- 3、学习内容
1、Hive 使用方式,即三种连接方式
1.1、CLI
配置 hive 环境变量后,直接输入命令 hive:
[hadoop@hadoop02 ~]$ hive
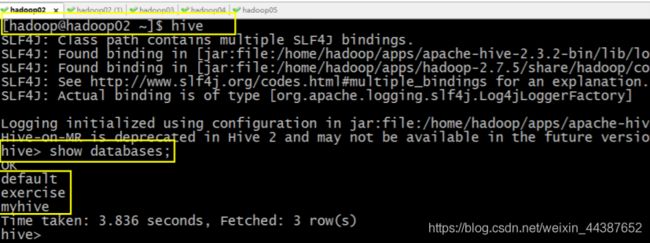
启动成功的话如上图所示,接下来便可以做 hive 相关操作。
补充:
(1)上面的 hive 命令相当于在启动的时候执行:hive --service cli;
(2)使用 hive --help,可以查看 hive 命令可以启动那些服务;
(3)通过 hive --service serviceName --help 可以查看某个具体命令的使用方式。
1.2、HiveServer2/beeline(常用)
在现在使用的最新的 hive-2.3.3 版本中:都需要对 hadoop 集群做如下改变,否则无法使用:
(1)修改 hadoop 集群的 hdfs-site.xml 配置文件:加入一条配置信息,表示启用 webhdfs:
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
(2)修改 hadoop 集群的 core-site.xml 配置文件:加入两条配置信息,表示设置 hadoop 的代理用户:
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属。
以上操作做好了之后,请继续做如下两步:
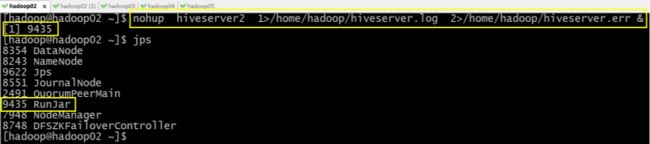
(3)先启动 hiveserver2 服务,启动方式,(假如是在 hadoop02 上):
启动为前台:
hiveserver2
启动为后台①:
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者②:
nohup hiveserver2 1>/dev/null 2>/dev/null &
或者③:
nohup hiveserver2 >/dev/null 2>&1 &
以上 ①②③ 三个命令是等价的,第一个表示记录日志,第二个和第三个表示不记录日志。
**
①②③命令中的 1 和 2 的意义分别是:
1:表示标准日志输出;
2:表示错误日志输出。
如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做:
nohup.xxx
**
PS:
nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。
nohup 就是不挂起的意思(no hang up)。该命令的一般形式为:
nohup command &
(4)然后启动 beeline 客户端去连接:
执行命令:
beeline -u jdbc:hive2://hadoop02:10000 -n hadoop
或者,相当于上个命令连接后使用命令:use database_name;:
beeline -u jdbc:hive2://hadoop02:10000/数据库名 -n hadoop
-u : 指定元数据库的链接信息
-n : 指定用户名和密码
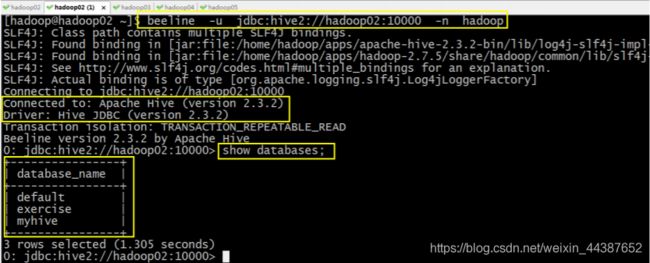
(5)另外还有一种方式也可以去连接:先执行
beeline
然后按图所示输入:
!connect jdbc:hive2://hadoop02:10000
按回车,然后输入用户名,密码,这个用户名就是安装 hadoop 集群的用户名
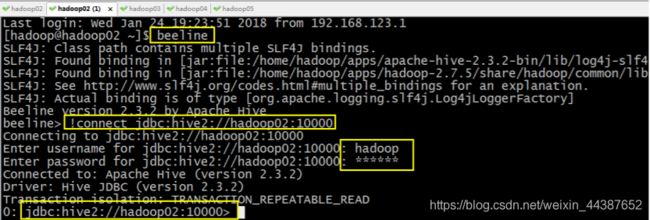
接下来便可以做 hive 操作。
1.3、Web UI
(1)在 hive-site-xml 中添加 hive 配置。
<property>
<name>hive.server2.webui.hostname>
<value>hadoop02value>
property>
<property>
<name>hive.server2.webui.portname>
<value>10002value>
property>
(2)启动 hive:
nohup hive --service metastore &
nohup hive --service hiveserver2 &
(3)在浏览器访问 http://hadoop02:10002。
至此大功告成。
2、Hive 基本使用(入门)
(1)创建库:
create database if not exists mydb;
(2)查看库:
show databases;
(3)切换数据库:
use mydb;
(4)创建表:
create table if not exists t_user(id string, name string);
或
create table t_user(id string, name string)
row format delimited fields terminated by ',';
(5)查看表列表:
show tables;
(6)批量插入数据:
insert into table t_user values ('1','huangbo'), ('2','xuzheng'), ('3','wangbaoqiang');
(7)查询数据:
select * from t_user;
(8)导入数据:
a) 导入 HDFS 数据:
load data inpath '/user.txt' into table t_user;
b) 导入本地数据:
load data local inpath '/home/hadoop/user.txt' into table t_user;
user.txt 的数据为:
4,liudehua
5,wuyanzu
6,liangchaowei
(9)再次查询数据:
select * from t_user;
小技能补充:
(1) 进入到用户的主目录,使用命令 cat /home/hadoop/.hivehistory 可以查看到 hive 执行的历史命令;
(2)执行查询时若想显示表头信息时,请执行命令:
Hive> set hive.cli.print.header=true;
(3)hive 的执行日志的存储目录在 j a v a . i o . t m p d i r / {java.io.tmpdir}/ java.io.tmpdir/{user.name}/hive.log中,假如使用 hadoop 用户操作的 hive,那么日志文件的存储路径为:/temp/hadoop/hive.log
3、学习内容
上节学习内容:Hive 初始环境搭建
下节学习内容:Hive 基本操作(一)DDL操作