利用xpath+re获取中医宝典中的中药详情信息
文章目录
-
- 完整代码
- 代码讲解
- 最后结果
完整代码
from lxml import etree
import requests
import re
def spider(name,img_path):
url="http://zhongyibaodian.com/zhongcaoyaotupian/"+name+".html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
page_text=requests.get(url=url,headers=headers)
#如果不加这个会解析出乱码
page_text.encoding="gb23112"
page_text=page_text.text
ex=''
a_list=re.findall(ex,page_text,re.S)
# print(a_list)
for a in a_list:
page_text=page_text.replace(a,"")
page_text=page_text.replace("
","")
page_text=page_text.replace("","")
# print(page_text)
tree=etree.HTML(page_text)
#获取中药名称
title=tree.xpath('//*[@id="divMain"]/div/h1/text()')[0]
# print(title)
#获取中药的详情信息
result=""
content=tree.xpath('//div[@class="spider"]/p[4]/text()')
if content!=[]:
p_list = tree.xpath('//div[@class="spider"]/p/text()')
for p in p_list:
result += p
else:
content=tree.xpath('//div[@class="spider"]/p[3]/text()')
if content==[]:
content=tree.xpath('//div[@class="spider"]/p[2]/text()')
result=content[0]
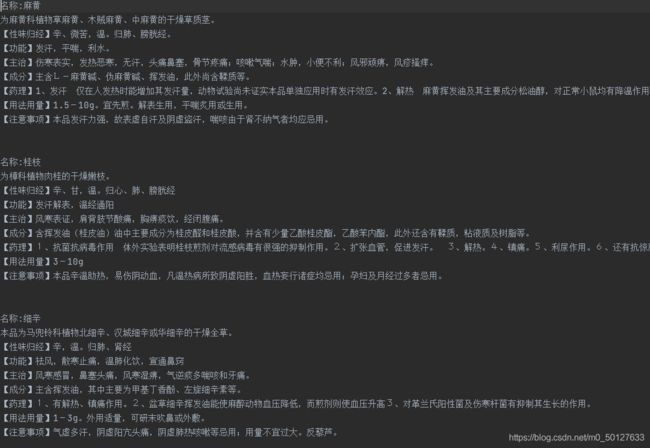
result=result.replace("【","\n【")
# print(result)
with open(img_path,'a') as fp:
fp.write("名称:"+title+'\n'+result+'\n\n\n')
#解表药
##辛温解表药
xinwenjiebiaoyao=['mahuang','guizhi','xixin','jingjie','fangfeng','baizhi','qianghuo','gaoben','xinyi','sugeng','chengliu',
'congbai','husui','shengjiang']
for name in xinwenjiebiaoyao:
spider(name,'../中药信息/解表药/辛温解表药.txt')
print(name+'爬取成功!')
##二、辛凉解表药
xinliangjiebiaoyao=['baohe','niubangzi','chantui','sangye','juhua','yejuhua','shengma','chaihu','gegen','manjingzi','fuping',
'muzei','gehua','dandouchi','dadouhuangjuan','heizha']
for name in xinliangjiebiaoyao:
spider(name,'../中药信息/解表药/辛凉解表药.txt')
print(name+'爬取成功!')
代码讲解
首先我们利用xpath找到这一段。
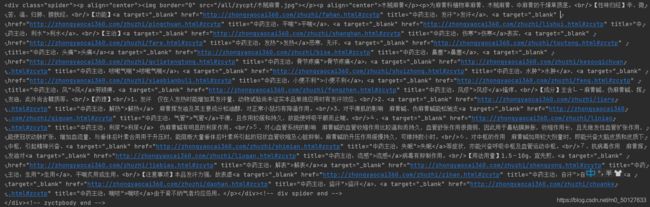
但是我们解析出来是这样的,看到看到a标签中的数据并没有解析出来。

因此我可利用正则表达式将符合条件的a标签去掉,只留下其中的文本内容。
ex=''
a_list=re.findall(ex,page_text,re.S)
for a in a_list:
page_text=page_text.replace(a,"")
page_text=page_text.replace("
","")
page_text=page_text.replace("","")
此时我们在解析出来就是这样

获得的就是只有一个元素的列表

因为此网站的页面设计并不是统一的,因此我们需要判断多种情况,在爬取的时候才不会出现例外
content=tree.xpath('//div[@class="spider"]/p[4]/text()')
if content!=[]:
p_list = tree.xpath('//div[@class="spider"]/p/text()')
for p in p_list:
result += p
else:
content=tree.xpath('//div[@class="spider"]/p[3]/text()')
if content==[]:
content=tree.xpath('//div[@class="spider"]/p[2]/text()')
result=content[0]
最后结果