【C++】泛型编程 | 函数模板 | 类模板
一、泛型编程
泛型编程是啥?
编写一种一般化的、可通用的算法出来,是代码复用的一种手段。
类似写一个模板出来,不同的情况,我们都可以往这个模板上去套。
举个例子:
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 1, b = 2;
Swap(a, b);
cout << a << b<这是一个交换函数。如果很多不同类型的数据需要交换,咋办?
函数重载?
函数重载的确可以解决,但是每多一种数据,都要实现对应的重载函数。实在太麻烦了。
我们想要的是:有一个一般化的模板,不管是什么类型,往这个模板函数上套用就行。这就是泛型编程的思想。
当用上泛型编程:
template
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
char a = 'a', b = 'b';
Swap(a, b);
cout << a << b< 结果:

接下来我们具体介绍如何使用泛型编程。
二、函数模板
泛型编程思想下得到的函数,就像是过了模具得到的。这些“模具”,被称作函数模板。
函数模板不是一个函数,而是一个模板。
函数模板的参数是一个模板,可以包含多个类型,返回值也是一个模板,可以包含多个类型。
格式
template
返回值类型 函数名(参数列表){} 注:
1.typename是用来定义模板参数关键字,也可以使用class。
2.tyname后面的类型名可以自己定,我们常常取为T(type)、Ty、K、V等,一般是大写字母or单词首字母大写。
运用起来:
template
void Swap( T& left, T& right)
{
T temp = left;
left = right;
right = temp;
} 或
template
…… 原理
❓Q:这俩调用的是同一个Swap函数吗?
char a = 'a', b = 'b';
Swap(a, b);
int c = 1, d = 2;
Swap(c, d);不是的!在函数栈帧里,要给形参开空间。这俩形参的类型不一样,自然不会是同一块空间。
不信我们看看汇编代码:

可见,调用的是两个不同的函数。
实际上,编译器会根据传入的实参类型来推演,把函数模板中的 T 换成相应类型,从而生成对应的函数。
如:当用double类型使用函数模板时,编译器会通过推演,将T替换成double,然后产生一份专门处理double类型的代码。
如果是int,那通过推演、替换,生成一份处理int的代码。
所以,在使用函数模板时,编译常常会慢上一点,因为它正在后台默默处理这些工作。
如图:

函数模板的实例化
什么叫”函数模板的实例化“?
是指:在调用函数模板时,根据传递的实参推导出函数模板的具体实现,生成一个特定类型的函数。
模板参数实例化分为:隐式实例化 和 显式实例化。
隐式实例化
隐式实例化,就是不指定类型,让编译器 自己去推演 模板参数的类型。
例:
template
T Add(const T& a, const T& b)
return a + b;
}
int main()
{
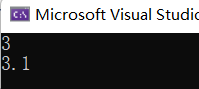
cout << Add(1, 2) << endl;
cout << Add(1.1, 2.0) << endl;
return 0;
} 
这里补充一个点(可跳过不看):
当Add的实参是数字时,那一定要加const修饰形参。如果实参是变量,const就不是一定要加。
这样写会报错:
templateT Add( T& a, T& b) //不加const会报错 return a + b; } int main() { cout << Add(1, 2) << endl; //当实参是数字 cout << Add(1.1, 2.0) << endl; return 0; }
这是因为:编译器会做一个强校验,当实参是数字时,它本身就是不能被修改的,此时必须加const才能通过编译。
如果这样写,加const就只是锦上添花,不是必须要的:
templateT Add( T& a, T& b) //不加const也能通过编译 { return a + b; } int main() { int a = 1, b = 2; cout << Add(a, b) << endl; //当实参是变量 return 0; }
然而,下面这种情况却编译不通过:
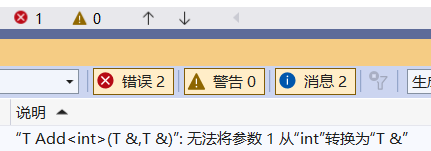
cout << Add(1.1, 2) << endl; 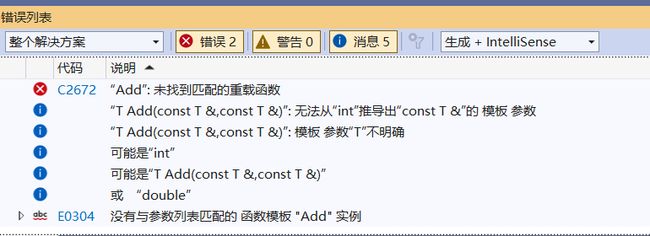
这是因为:编译器根据实参1.1将 T推为double,根据实参2又将 T推为int,这样T就不知道自己到底是int还是double,矛盾了。
此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
用强制转换的方式:
template
T Add(const T& a, const T& b)
{
return a + b;
}
int main()
{
cout << Add(1, (int)2.1) << endl;
cout << Add((double)1, 2.1) << endl;
return 0;
} 
用显示实例化的方式:
cout << Add(1, 2.1) << endl; //指定实例化成int类型
cout << Add(1, 2.1) << endl; //指定实例化成double类型 显式实例化
显示实例化,就是显示地指定函数模板的实参,从而生成一个特定类型的函数。
格式:在函数名后的<>中指定模板参数的实际类型。
函数名 <类型> (参数列表);如:
int main(void)
{
int a = 10;
double b = 20.1;
// 显式实例化
Add(a, b);
return 0;
} 如果类型不匹配,如b是bouble类型,但实例化类型指定为int,此时 编译器会尝试进行隐式类型转换。
如果转换失败 编译器将会报错。
模板参数的匹配原则
➡️1.一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。
int Add(int a, int b)
{
return a + b;
}
template
T Add(const T& a, const T& b)
{
return a + b;
}
int main()
{
cout << Add(1,2) << endl; //调用非模板函数
cout << Add(1,2) << endl; //调用 模板显示实例化出的函数
return 0;
} 来看看怎么调用的:

❓为什么两者调用的函数不同呢?
当已经有现成的,专门处理int的函数Add存在时,Add(1,2)会优先调用现成的,这样效率更高,省去了模板实例化的时间。
而下面的Add
(1,2),则指定了编译器去显示实例化模板,生成int类型的Add函数。
➡️2.对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数。
如果模板可以产生一个具有更好匹配的函数, 那么将选择模板。
例:
int Add(int a, int b)
{
return a + b;
}
template
T1 Add(const T1& a, const T2& b)
{
return a + b;
}
int main()
{
cout << Add(1,2) << endl;
cout << Add(1,2.0) << endl; //模板会隐式实例化,使T1为int,T2为double,更匹配
return 0;
} 来看看怎么调用的:

三、类模板
其实相比函数模板,后面用到 类模板的场景要更多。
为什么需要类模板
在没有类模板的时代,我们用typedef。typedef的问题有哪些呢?
typedef int STDateType;
class Stack
{
private:
STDateType* _a;
int _top;
int _capacity;
};
int main()
{
Stack s1; //s1是int类型
Stack s2; //s2是char类型
return 0;
}如上,如果我们想要s1是int而s2是char,咋整?
解决办法:将int重命名为STDateType1,char重命名为STDateType2:
typedef int STDateType1;
typedef char STDateType2;
class Stack
{
private:
STDateType1* _a;
int _top;
int _capacity;
};
class Stack
{
private:
STDateType2* _a;
int _top;
int _capacity;
};
int main()
{
Stack s1; //s1是int类型
Stack s2; //s2是char类型
return 0;
}两段Stack代码重复度极高,可见这个办法很多余。这暴露了typedef所不能解决的问题。
这种场景下,就需要用到类模板了。
类模板
格式:
template
class 类模板名
{
// 类内成员定义
}; 实例化:
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可。
// Vector类名,Vector才是类型
Vector s1;
Vector s2; 注意,类模板名字不是真正的类,而实例化的结果才是真正的类。
例:
Stack s1; //s1是int类型
Stack s2; //s2是char类型 这种场景下,编译器会根据
所以说,即使用了模板,T为 int和char时,依旧是两种不同的类,只不过不由我们手动实现,而是交给编译器去做了。
补充说明:
模板不支持分离编译,不能把声明写在.h文件,定义写在.cpp文件中。如果非要分离的话,模板是支持写在同一个文件里的。
可以把声明留在类里,定义写在类外(同一个文件里)。
用下面的例子展示下 声明与定义分离的写法:
class Stack { public: void Push(const T& x); //声明写在类里 private: T* _a; int _top; int _capacity; }; //定义在类外 // 注意:类模板中函数放在类外进行定义时,需要加模板参数列表 templatevoid Stack ::Push(const T& x) { if (_top == _capacity) { …… } _a[_top] = x; _top++; } 当然,都写在类里面也是可以的。
应用类模板
回到刚刚的那种场景,我们用类模板处理一下:
template
class Stack
{
public:
Stack(int capacity = 4)
:_a(nullptr)
, _top(0)
, _capacity(0)
{
if (capacity > 0)
{
_a = new T[capacity];
_capacity = capacity;
_top = 0;
}
}
private:
T* _a; //用模板,不同的类型都可以套
int _top;
int _capacity;
};
int main()
{
Stack s1; //s1是int类型
Stack s2; //s2是char类型
return 0;
}