通义千问杀疯了!首发Qwen-VL-Chat模型的A卡本地部署教程

阿里云最新开源的通义千问视觉语言模型:Qwen-VL
Qwen-VL 是一款支持中英文等多种语言的视觉语言(Vision Language,VL)模型,相较于此前的 VL 模型,其除了具备基本的图文识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。Qwen-VL 以 Qwen-7B 为基座语言模型,在模型架构上引入视觉编码器,使得模型支持视觉信号输入,该模型支持的图像输入分辨率为 448,此前开源的 LVLM 模型通常仅支持 224 分辨率。
量化 (Quantization)
据官方在评测基准 TouchStone 上的测试结果:量化 (Quantization)为Int4后,基本没有性能损失:
| Quantization | ZH. | EN |
|---|---|---|
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
推理速度 (Inference Speed)
输入一张图片(即258个token)的条件下BF16和Int4的模型生成1792 (2048-258) 和 7934 (8192-258) 个token的平均速度:
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|---|---|---|
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
快速部署,只需5步
本教程使用Qwen-VL-Chat的量化模型:【Qwen-VL-Chat-Int4】
本地环境:Ubuntu22.04.2 LTS + AMD® Radeon RX6700 XT(其他型号A卡也是可以玩的,不过需确保有12GB或更大显存)
1. 下载模型和配置文件
# 将这个HF仓库里的全部文件下载
git lfs install
git clone https://huggingface.co/4bit/Qwen-VL-Chat-Int4
2. 安装A卡的ROCm环境(如果你之前已安装,可跳过这一步)
在我这篇AI画图的文章里有详细的ROCm安装步骤: ROCm运行Stable Diffusion画图
3. 创建venv环境并安装A卡ROCm版Pytorch、optimum等依赖库
3.1 创建名为Qwen的venv环境
cd Qwen-VL-Chat-Int4
python3 -m venv Qwen
## 激活Qwen
. Qwen/bin/activate
## 安装torch torchvision torchaudio
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.4.2
3.2 用vim打开requirements.txt文件,将以下内容全覆盖进去
transformers==4.32.0
accelerate==0.23.0
tiktoken
einops
transformers_stream_generator==0.0.4
gradio
scipy
pillow
tensorboard
matplotlib
3.3 安装基本依赖库:
pip install -r ./requirements.txt
4. 安装A卡版本auto-gptq
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/rocm542/
pip install -q optimum
5. 运行测试
5.1 创建web_run.py文件,将以下内容复制进去
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple web interactive chat demo based on gradio."""
from argparse import ArgumentParser
from pathlib import Path
import copy
import gradio as gr
import os
import re
import secrets
import tempfile
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
DEFAULT_CKPT_PATH = 'Qwen/Qwen-VL-Chat'
BOX_TAG_PATTERN = r"([\s\S]*?) "
PUNCTUATION = "!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏."
def _get_args():
parser = ArgumentParser()
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
parser.add_argument("--share", action="store_true", default=False,
help="Create a publicly shareable link for the interface.")
parser.add_argument("--inbrowser", action="store_true", default=False,
help="Automatically launch the interface in a new tab on the default browser.")
parser.add_argument("--server-port", type=int, default=8000,
help="Demo server port.")
parser.add_argument("--server-name", type=str, default="127.0.0.1",
help="Demo server name.")
args = parser.parse_args()
return args
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "cuda"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
).eval()
model.generation_config = GenerationConfig.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
return model, tokenizer
def _parse_text(text):
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split("`")
if count % 2 == 1:
lines[i] = f'{items[-1]}
">'
else:
lines[i] = f"
" + line text = "".join(lines) return text def _launch_demo(args, model, tokenizer): uploaded_file_dir = os.environ.get("GRADIO_TEMP_DIR") or str( Path(tempfile.gettempdir()) / "gradio" ) def predict(_chatbot, task_history): chat_query = _chatbot[-1][0] query = task_history[-1][0] print("User: " + _parse_text(query)) history_cp = copy.deepcopy(task_history) full_response = "" history_filter = [] pic_idx = 1 pre = "" for i, (q, a) in enumerate(history_cp): if isinstance(q, (tuple, list)): q = f'Picture {pic_idx}:
![]()
"""
) gr.Markdown("""5.2 启动~
python web_run.py -c .
点击开始体验:
http://127.0.0.1:8000
对话和图片识别演示
人物识别:
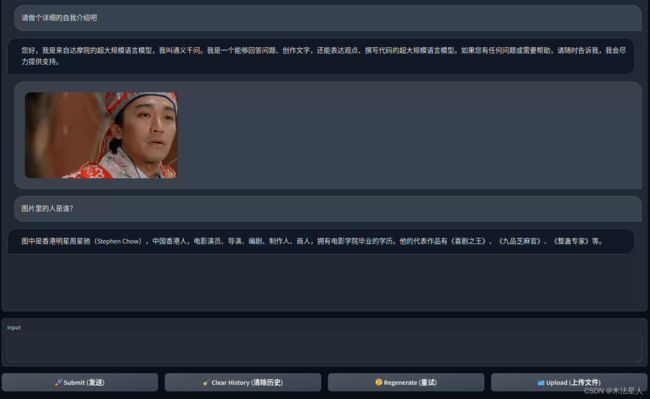 图形标注:
图形标注:

Q&A:N卡有12GB显存,可以跑吗?
可以,除了前置条件N卡驱动和CUDA以外,安装N卡的auto-gptq即可运行
N卡:
对于安装了CUDA 11.8的用户:
pip install auto-gptq[triton] --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/