Redis数据结构六之跳跃表
本文首发于公众号:Hunter后端
原文链接:Redis数据结构六之跳跃表
跳跃表结构是有序集合的底层实现之一,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
当有序集合包含的元素数量较多,又或者有序集合中的元素的成员是比较长的字符串时,Redis 就会使用跳跃表来作为有序集合的底层实现。
以下是本篇笔记目录:
- 跳跃表及跳跃表节点结构
- 跳跃表属性
- 跳跃表节点属性
- 跳跃表节点层(level)的生成
- 跳跃表的查询过程
1、跳跃表及跳跃表节点结构
接下来介绍一下跳跃表和跳跃表节点结构。
跳跃表结构:
typedef struct zskiplist{
// 表头节点和表尾节点
struct skiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
跳跃表结构中包含指向表头和表尾的指针,以及 length 字段表示表中节点的数量,level 字段则是表示所有跳跃表节点中最大的节点层数,层数的概念在跳跃表节点结构中再详细说明。
跳跃表节点结构:
typedef struct zskiplistNode{
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level [];
} zskiplistNode;
我们可以将跳跃表理解成链表,不过链表上的每个节点都有指向前面一个节点的指针和多个指向后面某些节点的指针,指向后面的指针以数组的形式存在。
接下来我们以一张图来示意一下跳跃表及其节点之间的关系。
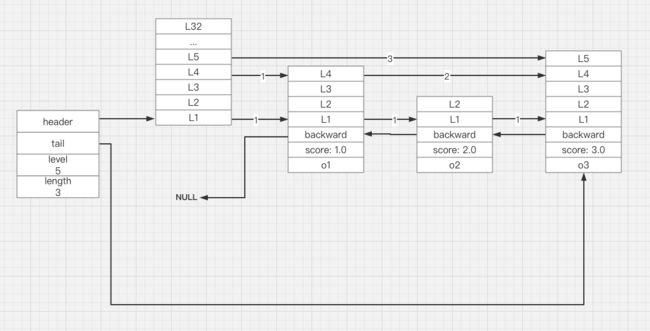
2、跳跃表结构
在上面的伪代码示例和上图结构中,可以看到一个跳跃表结构如下几个属性:
a) header
header 是跳跃表的头节点指针,可以快速定位跳跃表的头节点
b) tail
tail 是跳跃表的尾部节点指针,可以快速定位跳跃表的尾部节点
c) level
level 表示的是跳跃表节点中层数最高的数值,比如在图中第三个跳跃表节点的层数最高,数值是 5,所以跳跃表的这个值是 5。
d) length
length 属性表示的是跳跃表节点的个数,也就是跳跃表的长度。
3、跳跃表节点结构
跳跃表节点的各个属性如下:
a) obj
节点的成员对象,见图中的,o1,o2,o3,是一个指针,指向一个字符串对象,字符串对象保存着一个 SDS 值,就是有序集合中存储的数值。
b) score
有序集合用来进行排序的分值,有序集合通过这个属性用来对集合的元素进行排序,保存的是 double 类型的浮点数,在跳跃表中,所有节点按照分值从小到大来排序。
c) backward
后退指针,跳跃表的每个节点通过这个属性指向前一个节点,用于从表尾向表头方向访问节点。
图中展示了如何从表尾向跳跃表的头节点遍历的过程:通过 tail 指针指向跳跃表的尾部节点,然后通过 backward 后退指针逐个往前遍历,直到第一个节点的 backward 为 NULL 表示遍历结束。
d) skiplistLevel
skiplistLevel 是跳跃表节点的层,层数介于 1 到 32 之间,每个层的都包含两个属性,前进指针和跨度。
前进指针:forward,指向同一层级的下一个跳跃表节点
跨度:span,用于记录到同层级的下一个节点之间的距离,比如第一个节点的第四层级,下一个节点的第四层级是第三个节点,因此,o1 的第四层级的的跨度是 2。
4、跳跃表节点层(level)介绍
前面介绍跳跃表节点的层属性是一个数组,包含多个指向下一个同一层级的指针,而每个节点层的大小则是根据幂次定律(power law) 来生成的。
在创建一个跳跃表节点的时候,程序都会根据幂次定律随机生成一个介于 1 到 32 之间的值作为 level 数组的大小,这个规则是越大的数出现的概率越小,它有一种计算方式,层数每加 1,出现的概率都是前一个数字的 0.25。
比如 level = 1 的概率是 0.75,那么 level = 2 的概率是 0.75 * 0.25,level = 3 的概率则是 0.75 * 0.25 * 0.25,直到最高层数
所以每个跳跃表节点的层数都是随机的,跟这个节点在跳跃表的前后位置无关。
5、跳跃表的查询过程
以上面的图为例,比如我们想查询 score 为 2.0 的 o2 节点,那么查询的过程是这样的:
- 首先根据头节点的最高一层节点,在图中是 L5,L5 指向的是 o3 节点,o3 节点的分值比目标分值 2.0 大,舍弃
- 头节点往下降一层,到 L4,L4 指向下个节点 o1,o1的 score 比 2.0 小,跳到 o1 节点,继续查询
- o1 节点的 L4 指向的下一节点是 o3,o3 的 score 比 2.0 大,舍弃,o1 的 L4 继续下降一层
- o1 节点的 L3 节点指向的 o3 还是不符合条件,继续下降一层
- o1 节点的 L2 节点指向的 o2 节点,其分值满足条件,而从 o1 到 o2 的跨度为 1 + 1 = 2