搭建Hadoop2.6.0+Eclipse开发调试环境
上一篇在win7虚拟机下搭建了hadoop2.6.0伪分布式环境。为了开发调试方便,本文介绍在eclipse下搭建开发环境,连接和提交任务到hadoop集群。
1. 环境
Eclipse版本Luna 4.4.1
安装插件hadoop-eclipse-plugin-2.6.0.jar,下载后放到eclipse/plugins目录即可。
2. 配置插件
2.1 配置hadoop主目录
解压缩hadoop-2.6.0.tar.gz到C:\Downloads\hadoop-2.6.0,在eclipse的Windows->Preferences的Hadoop Map/Reduce中设置安装目录。

2.2 配置插件
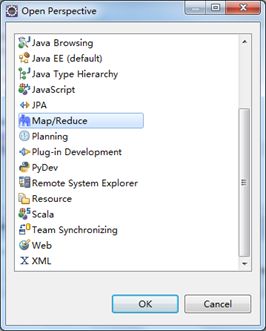
打开Windows->Open Perspective中的Map/Reduce,在此perspective下进行hadoop程序开发。
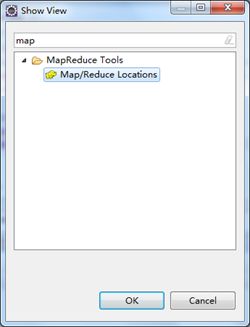
打开Windows->Show View中的Map/Reduce Locations,如下图右键选择New Hadoop location…新建hadoop连接。
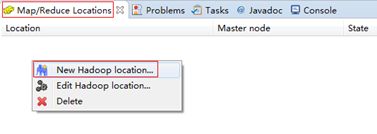
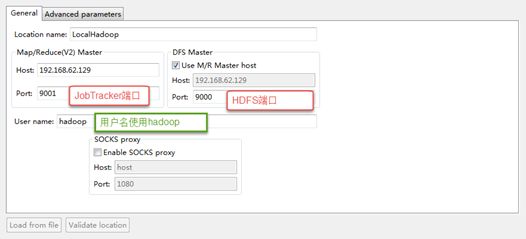
确认完成以后如下,eclipse会连接hadoop集群。

如果连接成功,在project explorer的DFS Locations下会展现hdfs集群中的文件。
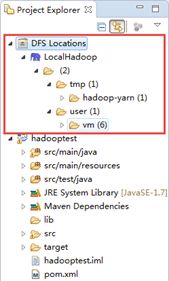
3. 开发hadoop程序
3.1 程序开发
开发一个Sort示例,对输入整数进行排序。输入文件格式是每行一个整数。


1 package com.ccb; 2 3 /** 4 * Created by hp on 2015-7-20. 5 */ 6 7 import java.io.IOException; 8 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.IntWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 20 public class Sort { 21 22 // 每行记录是一个整数。将Text文本转换为IntWritable类型,作为map的key 23 public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> { 24 private static IntWritable data = new IntWritable(); 25 26 // 实现map函数 27 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 28 String line = value.toString(); 29 data.set(Integer.parseInt(line)); 30 context.write(data, new IntWritable(1)); 31 } 32 } 33 34 // reduce之前hadoop框架会进行shuffle和排序,因此直接输出key即可。 35 public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, Text> { 36 37 //实现reduce函数 38 public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 39 for (IntWritable v : values) { 40 context.write(key, new Text("")); 41 } 42 } 43 } 44 45 public static void main(String[] args) throws Exception { 46 Configuration conf = new Configuration(); 47 48 // 指定JobTracker地址 49 conf.set("mapred.job.tracker", "192.168.62.129:9001"); 50 if (args.length != 2) { 51 System.err.println("Usage: Data Sort <in> <out>"); 52 System.exit(2); 53 } 54 System.out.println(args[0]); 55 System.out.println(args[1]); 56 57 Job job = Job.getInstance(conf, "Data Sort"); 58 job.setJarByClass(Sort.class); 59 60 //设置Map和Reduce处理类 61 job.setMapperClass(Map.class); 62 job.setReducerClass(Reduce.class); 63 64 //设置输出类型 65 job.setOutputKeyClass(IntWritable.class); 66 job.setOutputValueClass(IntWritable.class); 67 68 //设置输入和输出目录 69 FileInputFormat.addInputPath(job, new Path(args[0])); 70 FileOutputFormat.setOutputPath(job, new Path(args[1])); 71 System.exit(job.waitForCompletion(true) ? 0 : 1); 72 } 73 }
3.2 配置文件
把log4j.properties和hadoop集群中的core-site.xml加入到classpath中。我的示例工程是maven组织,因此放到src/main/resources目录。
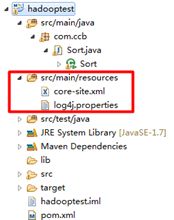
程序执行时会从core-site.xml中获取hdfs地址。
3.3 程序执行
右键选择Run As -> Run Configurations…,在参数中填好输入输出目录,执行Run即可。
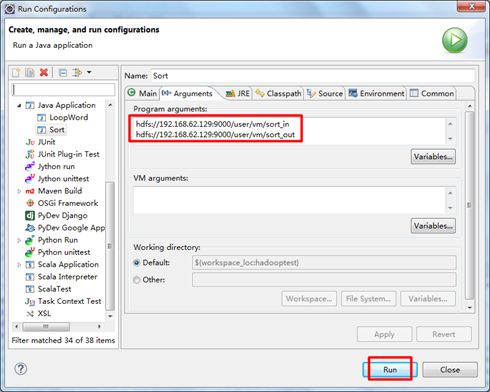
执行日志:
1 hdfs://192.168.62.129:9000/user/vm/sort_in 2 hdfs://192.168.62.129:9000/user/vm/sort_out 3 15/07/27 16:21:36 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 4 15/07/27 16:21:36 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 5 15/07/27 16:21:36 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 6 15/07/27 16:21:36 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String). 7 15/07/27 16:21:36 INFO input.FileInputFormat: Total input paths to process : 3 8 15/07/27 16:21:36 INFO mapreduce.JobSubmitter: number of splits:3 9 15/07/27 16:21:36 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address 10 15/07/27 16:21:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1592166400_0001 11 15/07/27 16:21:37 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 12 15/07/27 16:21:37 INFO mapreduce.Job: Running job: job_local1592166400_0001 13 15/07/27 16:21:37 INFO mapred.LocalJobRunner: OutputCommitter set in config null 14 15/07/27 16:21:37 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 15 15/07/27 16:21:37 INFO mapred.LocalJobRunner: Waiting for map tasks 16 15/07/27 16:21:37 INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000000_0 17 15/07/27 16:21:37 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 18 15/07/27 16:21:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4c90dbc4 19 15/07/27 16:21:37 INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file1:0+25 20 15/07/27 16:21:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 21 15/07/27 16:21:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 22 15/07/27 16:21:37 INFO mapred.MapTask: soft limit at 83886080 23 15/07/27 16:21:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 24 15/07/27 16:21:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 25 15/07/27 16:21:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 26 15/07/27 16:21:38 INFO mapred.LocalJobRunner: 27 15/07/27 16:21:38 INFO mapred.MapTask: Starting flush of map output 28 15/07/27 16:21:38 INFO mapred.MapTask: Spilling map output 29 15/07/27 16:21:38 INFO mapred.MapTask: bufstart = 0; bufend = 56; bufvoid = 104857600 30 15/07/27 16:21:38 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214372(104857488); length = 25/6553600 31 15/07/27 16:21:38 INFO mapred.MapTask: Finished spill 0 32 15/07/27 16:21:38 INFO mapred.Task: Task:attempt_local1592166400_0001_m_000000_0 is done. And is in the process of committing 33 15/07/27 16:21:38 INFO mapred.LocalJobRunner: map 34 15/07/27 16:21:38 INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000000_0' done. 35 15/07/27 16:21:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000000_0 36 15/07/27 16:21:38 INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000001_0 37 15/07/27 16:21:38 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 38 15/07/27 16:21:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@69e4d7d 39 15/07/27 16:21:38 INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file2:0+15 40 15/07/27 16:21:38 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 41 15/07/27 16:21:38 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 42 15/07/27 16:21:38 INFO mapred.MapTask: soft limit at 83886080 43 15/07/27 16:21:38 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 44 15/07/27 16:21:38 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 45 15/07/27 16:21:38 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 46 15/07/27 16:21:38 INFO mapred.LocalJobRunner: 47 15/07/27 16:21:38 INFO mapred.MapTask: Starting flush of map output 48 15/07/27 16:21:38 INFO mapred.MapTask: Spilling map output 49 15/07/27 16:21:38 INFO mapred.MapTask: bufstart = 0; bufend = 32; bufvoid = 104857600 50 15/07/27 16:21:38 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600 51 15/07/27 16:21:38 INFO mapred.MapTask: Finished spill 0 52 15/07/27 16:21:38 INFO mapred.Task: Task:attempt_local1592166400_0001_m_000001_0 is done. And is in the process of committing 53 15/07/27 16:21:38 INFO mapred.LocalJobRunner: map 54 15/07/27 16:21:38 INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000001_0' done. 55 15/07/27 16:21:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000001_0 56 15/07/27 16:21:38 INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000002_0 57 15/07/27 16:21:38 INFO mapreduce.Job: Job job_local1592166400_0001 running in uber mode : false 58 15/07/27 16:21:38 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 59 15/07/27 16:21:38 INFO mapreduce.Job: map 100% reduce 0% 60 15/07/27 16:21:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4e931efa 61 15/07/27 16:21:38 INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file3:0+8 62 15/07/27 16:21:39 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 63 15/07/27 16:21:39 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 64 15/07/27 16:21:39 INFO mapred.MapTask: soft limit at 83886080 65 15/07/27 16:21:39 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 66 15/07/27 16:21:39 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 67 15/07/27 16:21:39 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 68 15/07/27 16:21:39 INFO mapred.LocalJobRunner: 69 15/07/27 16:21:39 INFO mapred.MapTask: Starting flush of map output 70 15/07/27 16:21:39 INFO mapred.MapTask: Spilling map output 71 15/07/27 16:21:39 INFO mapred.MapTask: bufstart = 0; bufend = 24; bufvoid = 104857600 72 15/07/27 16:21:39 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214388(104857552); length = 9/6553600 73 15/07/27 16:21:39 INFO mapred.MapTask: Finished spill 0 74 15/07/27 16:21:39 INFO mapred.Task: Task:attempt_local1592166400_0001_m_000002_0 is done. And is in the process of committing 75 15/07/27 16:21:39 INFO mapred.LocalJobRunner: map 76 15/07/27 16:21:39 INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000002_0' done. 77 15/07/27 16:21:39 INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000002_0 78 15/07/27 16:21:39 INFO mapred.LocalJobRunner: map task executor complete. 79 15/07/27 16:21:39 INFO mapred.LocalJobRunner: Waiting for reduce tasks 80 15/07/27 16:21:39 INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_r_000000_0 81 15/07/27 16:21:39 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 82 15/07/27 16:21:39 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@49250068 83 15/07/27 16:21:39 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@2129404b 84 15/07/27 16:21:39 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=652528832, maxSingleShuffleLimit=163132208, mergeThreshold=430669056, ioSortFactor=10, memToMemMergeOutputsThreshold=10 85 15/07/27 16:21:39 INFO reduce.EventFetcher: attempt_local1592166400_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 86 15/07/27 16:21:40 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1592166400_0001_m_000002_0 decomp: 32 len: 36 to MEMORY 87 15/07/27 16:21:40 INFO reduce.InMemoryMapOutput: Read 32 bytes from map-output for attempt_local1592166400_0001_m_000002_0 88 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 32, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->32 89 15/07/27 16:21:40 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1592166400_0001_m_000000_0 decomp: 72 len: 76 to MEMORY 90 15/07/27 16:21:40 INFO reduce.InMemoryMapOutput: Read 72 bytes from map-output for attempt_local1592166400_0001_m_000000_0 91 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 72, inMemoryMapOutputs.size() -> 2, commitMemory -> 32, usedMemory ->104 92 15/07/27 16:21:40 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1592166400_0001_m_000001_0 decomp: 42 len: 46 to MEMORY 93 15/07/27 16:21:40 INFO reduce.InMemoryMapOutput: Read 42 bytes from map-output for attempt_local1592166400_0001_m_000001_0 94 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 42, inMemoryMapOutputs.size() -> 3, commitMemory -> 104, usedMemory ->146 95 15/07/27 16:21:40 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 96 15/07/27 16:21:40 INFO mapred.LocalJobRunner: 3 / 3 copied. 97 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: finalMerge called with 3 in-memory map-outputs and 0 on-disk map-outputs 98 15/07/27 16:21:40 INFO mapred.Merger: Merging 3 sorted segments 99 15/07/27 16:21:40 INFO mapred.Merger: Down to the last merge-pass, with 3 segments left of total size: 128 bytes 100 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: Merged 3 segments, 146 bytes to disk to satisfy reduce memory limit 101 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: Merging 1 files, 146 bytes from disk 102 15/07/27 16:21:40 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 103 15/07/27 16:21:40 INFO mapred.Merger: Merging 1 sorted segments 104 15/07/27 16:21:40 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 136 bytes 105 15/07/27 16:21:40 INFO mapred.LocalJobRunner: 3 / 3 copied. 106 15/07/27 16:21:40 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 107 15/07/27 16:21:40 INFO mapred.Task: Task:attempt_local1592166400_0001_r_000000_0 is done. And is in the process of committing 108 15/07/27 16:21:40 INFO mapred.LocalJobRunner: 3 / 3 copied. 109 15/07/27 16:21:40 INFO mapred.Task: Task attempt_local1592166400_0001_r_000000_0 is allowed to commit now 110 15/07/27 16:21:40 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1592166400_0001_r_000000_0' to hdfs://192.168.62.129:9000/user/vm/sort_out/_temporary/0/task_local1592166400_0001_r_000000 111 15/07/27 16:21:40 INFO mapred.LocalJobRunner: reduce > reduce 112 15/07/27 16:21:40 INFO mapred.Task: Task 'attempt_local1592166400_0001_r_000000_0' done. 113 15/07/27 16:21:40 INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_r_000000_0 114 15/07/27 16:21:40 INFO mapred.LocalJobRunner: reduce task executor complete. 115 15/07/27 16:21:40 INFO mapreduce.Job: map 100% reduce 100% 116 15/07/27 16:21:41 INFO mapreduce.Job: Job job_local1592166400_0001 completed successfully 117 15/07/27 16:21:41 INFO mapreduce.Job: Counters: 38 118 File System Counters 119 FILE: Number of bytes read=3834 120 FILE: Number of bytes written=1017600 121 FILE: Number of read operations=0 122 FILE: Number of large read operations=0 123 FILE: Number of write operations=0 124 HDFS: Number of bytes read=161 125 HDFS: Number of bytes written=62 126 HDFS: Number of read operations=41 127 HDFS: Number of large read operations=0 128 HDFS: Number of write operations=10 129 Map-Reduce Framework 130 Map input records=14 131 Map output records=14 132 Map output bytes=112 133 Map output materialized bytes=158 134 Input split bytes=339 135 Combine input records=0 136 Combine output records=0 137 Reduce input groups=13 138 Reduce shuffle bytes=158 139 Reduce input records=14 140 Reduce output records=14 141 Spilled Records=28 142 Shuffled Maps =3 143 Failed Shuffles=0 144 Merged Map outputs=3 145 GC time elapsed (ms)=10 146 CPU time spent (ms)=0 147 Physical memory (bytes) snapshot=0 148 Virtual memory (bytes) snapshot=0 149 Total committed heap usage (bytes)=1420296192 150 Shuffle Errors 151 BAD_ID=0 152 CONNECTION=0 153 IO_ERROR=0 154 WRONG_LENGTH=0 155 WRONG_MAP=0 156 WRONG_REDUCE=0 157 File Input Format Counters 158 Bytes Read=48 159 File Output Format Counters 160 Bytes Written=62
4. 可能出现的问题
4.1 权限问题,无法访问HDFS
修改集群hdfs-site.xml配置,关闭hadoop集群的权限校验。
| <property> <name>dfs.permissions</name> <value>false</value> </property> |
4.2 出现NullPointerException异常
在环境变量中配置%HADOOP_HOME%为C:\Download\hadoop-2.6.0\
下载winutils.exe和hadoop.dll到C:\Download\hadoop-2.6.0\bin
注意:网上很多资料说的是下载hadoop-common-2.2.0-bin-master.zip,但很多不支持hadoop2.6.0版本。需要下载支持hadoop2.6.0版本的程序。
4.3 程序执行失败
需要执行Run on Hadoop,而不是Java Application。
