微服务保护-隔离和降级
隔离和降级
限流是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
线程隔离之前讲到过:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
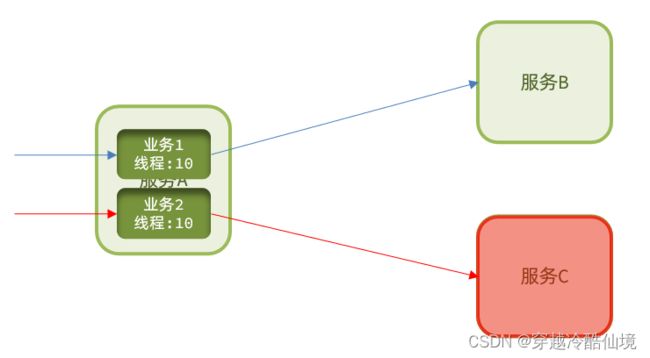
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。

可以看到,不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。需要在调用方 发起远程调用时做线程隔离、或者服务熔断。
而我们的微服务远程调用都是基于Feign来完成的,因此我们需要将Feign与Sentinel整合,在Feign里面实现线程隔离和服务熔断。
FeignClient整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
修改配置,开启sentinel功能
修改OrderService的application.yml文件,开启Feign的Sentinel功能:
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持
编写失败降级逻辑
业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
这里我们演示方式二的失败降级处理。
步骤一:在feing-api项目中定义类,实现FallbackFactory:

代码:
package cn.itcast.feign.clients.fallback;
import cn.itcast.feign.clients.UserClient;
import cn.itcast.feign.pojo.User;
import feign.hystrix.FallbackFactory;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
log.error("查询用户异常", throwable);
return new User();
}
};
}
}
步骤二:在feing-api项目中的DefaultFeignConfiguration类中将UserClientFallbackFactory注册为一个Bean:
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}步骤三:在feing-api项目中的UserClient接口中使用UserClientFallbackFactory:
import cn.itcast.feign.clients.fallback.UserClientFallbackFactory;
import cn.itcast.feign.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}重启后,访问一次订单查询业务,然后查看sentinel控制台,可以看到新的簇点链路:

总结
Sentinel支持的雪崩解决方案:
-
线程隔离(仓壁模式)
-
降级熔断
Feign整合Sentinel的步骤:
-
在application.yml中配置:feign.sentienl.enable=true
-
给FeignClient编写FallbackFactory并注册为Bean
-
将FallbackFactory配置到FeignClient
线程隔离(舱壁模式)
线程隔离的实现方式
线程隔离有两种方式实现:
-
线程池隔离
-
信号量隔离(Sentinel默认采用)
如图:

线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
两者的优缺点: 
sentinel的线程隔离
用法说明:
在添加限流规则时,可以选择两种阈值类型:

-
QPS:就是每秒的请求数,在快速入门中已经演示过
-
线程数:是该资源能使用用的tomcat线程数的最大值。也就是通过限制线程数量,实现线程隔离(舱壁模式)。
案例需求:给 order-service服务中的UserClient的查询用户接口设置流控规则,线程数不能超过 2。然后利用jemeter测试。
1)配置隔离规则
选择feign接口后面的流控按钮:

填写表单:

2)Jmeter测试
选择《阈值类型-线程数<2》:
 一次发生10个请求,有较大概率并发线程数超过2,而超出的请求会走之前定义的失败降级逻辑。
一次发生10个请求,有较大概率并发线程数超过2,而超出的请求会走之前定义的失败降级逻辑。
查看运行结果:

发现虽然结果都是通过了,不过部分请求得到的响应是降级返回的null信息。
总结
线程隔离的两种手段是?
-
信号量隔离
-
线程池隔离
信号量隔离的特点是?
-
基于计数器模式,简单,开销小
线程池隔离的特点是?
-
基于线程池模式,有额外开销,但隔离控制更强
熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
断路器控制熔断和放行是通过状态机来完成的:

状态机包括三个状态:
-
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
-
open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
-
half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
-
请求成功:则切换到closed状态
-
请求失败:则切换到open状态
-
断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
例如:

解读:RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
案例
需求:给 UserClient的查询用户接口设置降级规则,慢调用的RT阈值为50ms,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5
1)设置慢调用
修改user-service中的/user/{id}这个接口的业务。通过休眠模拟一个延迟时间:
 此时,orderId=101的订单,关联的是id为1的用户,调用时长为60ms:
此时,orderId=101的订单,关联的是id为1的用户,调用时长为60ms:
 orderId=102的订单,关联的是id为2的用户,调用时长为非常短;
orderId=102的订单,关联的是id为2的用户,调用时长为非常短;

2)设置熔断规则
下面,给feign接口设置降级规则:  规则:
规则:  超过50ms的请求都会被认为是慢请求
超过50ms的请求都会被认为是慢请求
3)测试
在浏览器访问:http://localhost:8088/order/101,快速刷新5次,可以发现:
 触发了熔断,请求时长缩短至5ms,快速失败了,并且走降级逻辑,返回的null
触发了熔断,请求时长缩短至5ms,快速失败了,并且走降级逻辑,返回的null
在浏览器访问:http://localhost:8088/order/102,竟然也被熔断了: 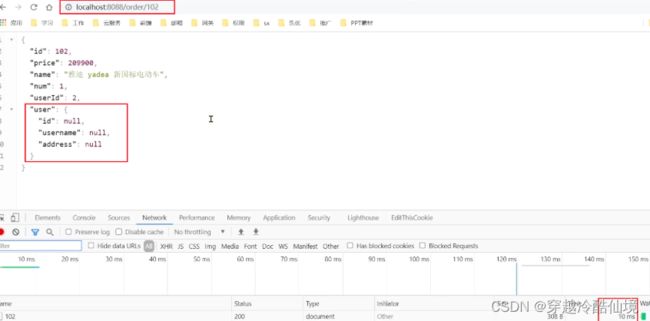
异常比例、异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
例如,一个异常比例设置:

解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断。
一个异常数设置:

解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于2次,则触发熔断。
案例
需求:给 UserClient的查询用户接口设置降级规则,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5s
1)设置异常请求
首先,修改user-service中的/user/{id}这个接口的业务。手动抛出异常,以触发异常比例的熔断:
 也就是说,id 为 2时,就会触发异常
也就是说,id 为 2时,就会触发异常
2)设置熔断规则
下面,给feign接口设置降级规则:
![]()
规则:  在5次请求中,只要异常比例超过0.4,也就是有2次以上的异常,就会触发熔断。
在5次请求中,只要异常比例超过0.4,也就是有2次以上的异常,就会触发熔断。
3)测试
在浏览器快速访问:http://localhost:8088/order/102,快速刷新5次,触发熔断:

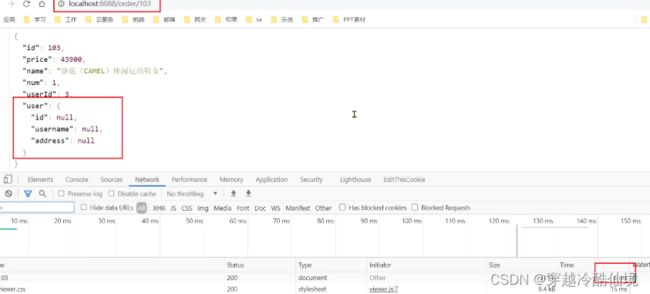
此时,我们去访问本来应该正常的103: