(秦路)七周成为数据分析师(第七周)——Python
文章目录
-
- 1.Python基础
- 2.Pandas
-
- 2.1 series
-
- 生成
- 用索引读取相应的行
- 2.2 DataFrame
-
- 生成
- 查看形状
- 查看属性和信息
- 查看数据类型
- 查看某列有多少种元素
- 查看某一列各元素出现的次数
- 查看某列各元素的长度
- 用索引读取相应的行和列
- 查看索引范围
- 按条件查找
- 用query按条件查找
- 用iloc和loc查找行
- 提取某列的特定行
- 将所有列倒序排列
- 交换两列位置
- 更换全部列位置
- 删除行
- 删除行
- 将两列合并成一列
- 将数据按行的逆序输出
- 2.3 读取csv文件
-
- 读取csv文件
- 读取时设置显示行列的参数:pd.set_option()
- 修改类型
- query筛选
- 转置
- 按某个字段排序
- 排名
- 查看某个列的唯一值
- 查看重复的行
- 查看为空的有几行:
- 随机添加一列值
- 添加一行数据
- 设置value2列保留两位小数
- 将小数转换为百分数
- 将时间戳转换为datetime类型
- 拆分
- 删除首尾的字符
- 提取每列缺失值的具体行数
- 提取某列不是字符串的行
- 提取列包含字符串('--')的行
- 提取列以'25k'开头的行
- 提取value列中不在value1列出现的数字
- 提取value列和value1列出现频率最高的数字
- 提取value列中可以整除10的数字位置
- 统计某个列的各个值的数量
- 统计各列的数量
- 统计各列的最大值
- 返回某个轴上的累计和
- 查看各列的描述性统计数据
- 将值转换为离散值,划分区间
- 分组group
- 2.3 两表联合
-
- merge,最常用
- concat
- join按索引连接
- 2.4 文本处理
-
- 文本分隔split
- 对某个字段进行统计
- 读取成str格式再对文本进行处理
- 空值的处理
- 2.6 apply函数
-
- agg
- 2.7 透视表pivot_table
- 2.8 数据库
-
- pymysql
- pandas读取数据库
- 3 python练习
- 3.数据可视化
- 4.数据分析案例
- 5.数据分析平台
anaconda:
esc + m 转换为markdown格式
tab:补全
shift+tab:查看函数
1.Python基础
简单函数
list=[i**2 for i in range(1,101) if i%2=0]
dict={"a":1,"b":2}
[v**2 for v in dict.values()]
def func(x):
return x*x
[func(i) for i in range(1,11)]
list(map(func,[1,2,3,4,5]))
匿名函数:
lambda x:x*x
list(map(lambda x:x*x,[1,2,3,4,5]))

统计数字出现几次。另一种用第三方库的方式:
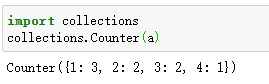
2.Pandas
series相当于数组,dataframe相当于excel表格
2.1 series
生成
s1=pd.Series([1,2,3,4])
s2=pd.Series([1,2,3,4],index=['a','b','c','d']) #可修改索引


用索引读取相应的行

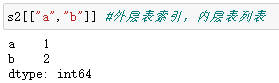
2.2 DataFrame
生成
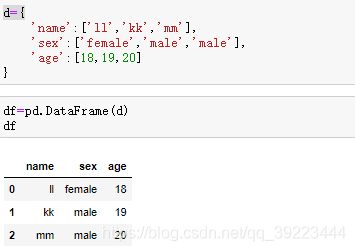
查看形状
df.shape
df.shape[0] or len(df)
查看属性和信息
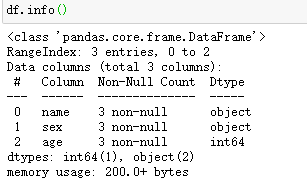
查看数据类型
df.dtypes
查看某列有多少种元素
#方法一:
len(df['name'].unique())
查看某一列各元素出现的次数
df['name'].value_counts()
查看某列各元素的长度
# 方法一:
df['name'].str.len()
# 方法二:
df['name'].map(lambda x: len(x))
用索引读取相应的行和列

查看索引范围
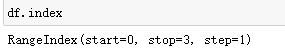
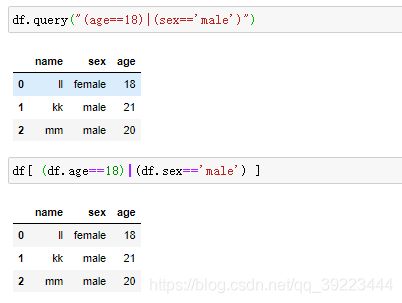
按条件查找

用query按条件查找
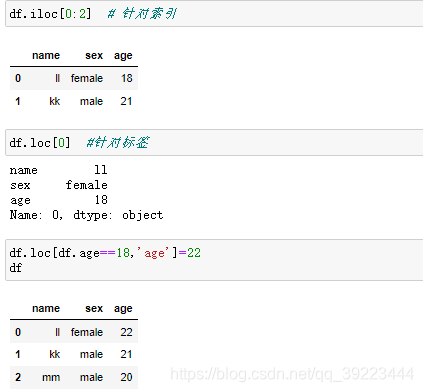
用iloc和loc查找行
提取某列的特定行
# 方法一:
df.iloc[[1,10,15], 0]
# 方法二:
df['createTime'][[1,10,15]]
# 方法三:
df['createTime'].take([1,10,15])
将所有列倒序排列
#方法一:
df.iloc[:, ::-1]
#方法二
df.iloc[:, [-1,-2,-3,-4]]
交换两列位置
temp = df['name']
df.drop(labels=['name'], axis=1, inplace=True)
df.insert(1, 'name', temp)
df
更换全部列位置
order = df.columns[[0, 3, 1, 2]] # 或者order = ['xx', 'xx',...] 具体列名
df = df[order]
删除行
# 法一:
del df['id']
# 法二:
df['id'] = range(1,11)
df.drop('id',axis=1, inplace=True) #columns=['xxx']
删除行
index = df[df['grammer'] == 'css'].index[0]
df.drop(labels=[index], inplace=True)
将两列合并成一列
df['new_col'] = df['sex'] + df['age'].map(str) # score为int类型,需转换为字符串类型;
将数据按行的逆序输出
df.iloc[::-1, :]
# [::-1]表示步长为-1, 从后往前倒序输出
2.3 读取csv文件

csv需为utf-8格式,否则无法解析。
![]()
gbk格式,需设置编码格式。
df.head()前五条
df.tail()最后五条
读取csv文件
tsv = pd.read_csv('chipotle.tsv', sep = '\t')
tsv.head()
读取时设置显示行列的参数:pd.set_option()
# 显示列
pd.set_option('display.max_columns', None)
pd.set_option('display.max_columns', 5) #最多显示5列
# 显示行
pd.set_option('display.max_rows', None)
pd.set_option('display.max_rows', 10)#最多显示10行
显示小数位数
pd.set_option('display.float_format',lambda x: '%.2f'%x) #两位
# 显示宽度
pd.set_option('display.width', 100)
# 设置小数点后的位数
pd.set_option('precision', 1)
# 是否换行显示
pd.set_option('expand_frame_repr', False)
# True就是可以换行显示。设置成False的时候不允许换行
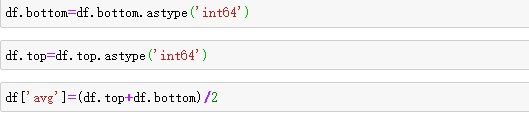
修改类型
query筛选
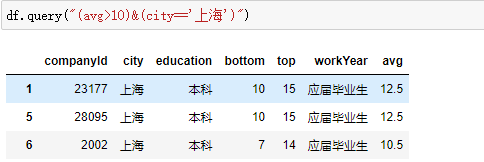
转置

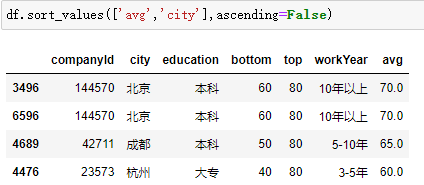
按某个字段排序
![]()

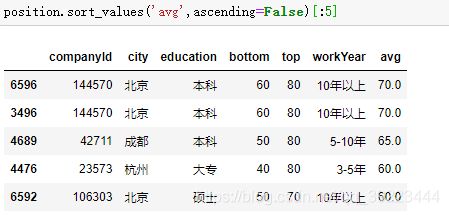
按索引排序
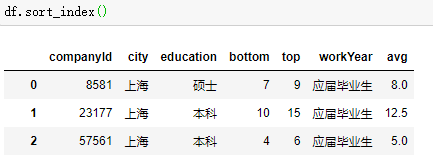
排名
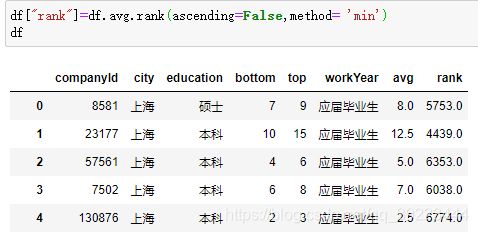
按avg排名,method指按如果有相同的值按最小进行排名。
查看某个列的唯一值

查看重复的行
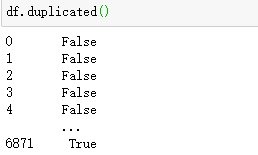
显示重复的行:
![]()
查看某几列是否重复
position.duplicated(subset = ['city','education'])
查看为空的有几行:
随机添加一列值
import random
df['value'] = [random.randint(1,100) for i in range(len(df))]
df.head()
添加一行数据
# 方法一:字典
df2 = pd.DataFrame({
'createTime':['2020-03-16 10:48:36'],
'education':['硕士'],
'salary':['20k-40k'],
'value':[43.0]
})
df = df.append(df2, ignore_index=True)
df.tail()
# 方法二:loc
df.loc[len(df)] = ['2020-03-16 11:20:41', '硕士', '25k-45k', 29.0]
df.tail()
设置value2列保留两位小数
# 随机生成一列0.01到1之间的浮点数
df['value2'] = [random.uniform(0.01, 1) for i in range(len(df))] # 注:uniform产生1到100之间的随机浮点数,区间可以不是整数
# 方法一:round()函数
df['value2'].round(2)
# 方法二:map + lambda
df['value2'].map(lambda x : ('%.2f') % x)
# 方法三:map + lambda + format
df['value2'] = df['value2'].map(lambda x : format(x, '.2f'))
df.head()
将小数转换为百分数
#由于value2上一步转换为小数时,会自动将浮点类型变为object类型,
df['value2'] = df['value2'].astype('float')
# 方法一:style + 格式化处理
df.style.format({'value2' : '{0:.2%}'.format})
# 方法二:自定义函数+格式化处理
df['value2'] = df['value2'].map(lambda x : format(x, '.2%'))
df.head()
将时间戳转换为datetime类型
# 采用Timestamp.to_pydatetime()函数将给定的时间戳转换为本地python datetime对象; strftime()用来格式化datetime 对象
# 将createTime(第一列)列时间转换为月-日:
for i in range(len(df)):
df.iloc[i,0] = df.iloc[i,0].to_pydatetime().strftime("%m-%d")
拆分
df['salary'].str.split('-')
删除首尾的字符
df['salary'].str.strip()
提取每列缺失值的具体行数
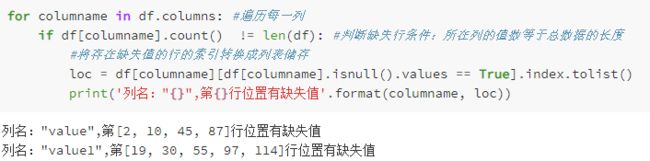
提取某列不是字符串的行

提取列包含字符串(’–’)的行
# 方法一:isin()
df[df['salary'].isin(['--'])]
# 方法二:contains()
df[df["salary"].str.contains("--")]
提取列以’25k’开头的行
# 方法一:match函数
df[df['salary'].str.match('25k')]
# 方法二:startswith函数
df[df['salary'].str.startswith('25k')]
提取value列中不在value1列出现的数字
df['value'][~df['value'].isin(df['value1'])] #~取反
提取value列和value1列出现频率最高的数字
# 先将两列使用append()按行合并,再用计数函数:
temp = df['value'].append(df['value1'])
temp.value_counts(ascending=False)#不加index,返回的是一个Series
temp.value_counts(ascending=False).index[:5] #返回一个数组
提取value列中可以整除10的数字位置
#方法一:
df[df['value'] % 10 == 0].index
#方法二:np.argwhere
np.argwhere(np.array(df['value'] % 10 == 0))
统计某个列的各个值的数量

统计各列的数量

统计各列的最大值
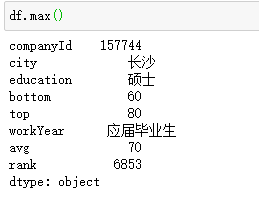
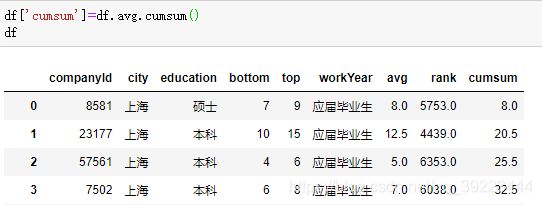
返回某个轴上的累计和
默认axis=0,列的累加和
df.avg.cumsum(axis=None, skipna=True, *args, **kwargs)
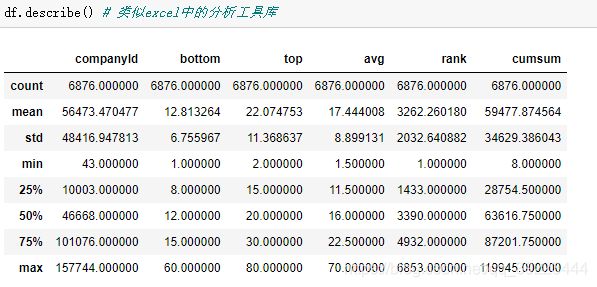
查看各列的描述性统计数据
df.describe(percentiles=None, include=None, exclude=None) -> ~FrameOrSeries

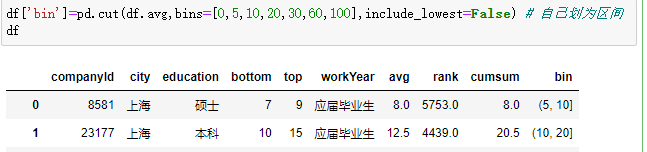
将值转换为离散值,划分区间
等分


分位数划分
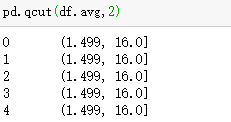
分组group
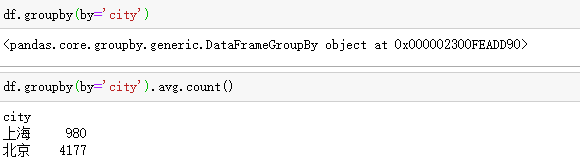 只分组显示属性,加入具体列之后就可以计算其统计数据
只分组显示属性,加入具体列之后就可以计算其统计数据

可以加入列名,指定某个字段查看:

用loc查看某个字段的所有值,是以dataframe形式呈现

将某些字段设置为索引

将列变为索引并排序
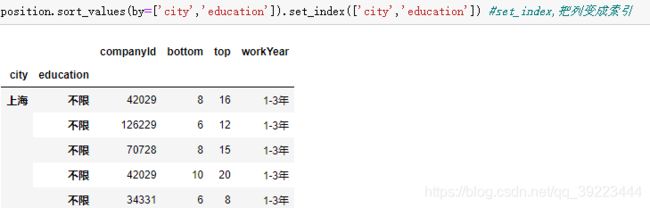

可以多个分组标签:


k是分类标签,v是其他数据

2.3 两表联合
merge,最常用



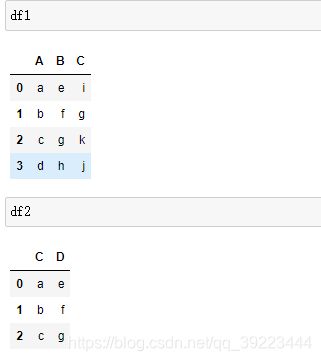
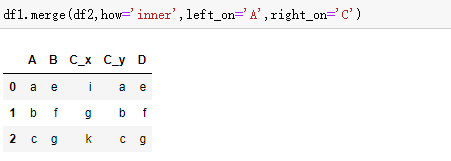
concat
沿着特定轴将两表连接起来
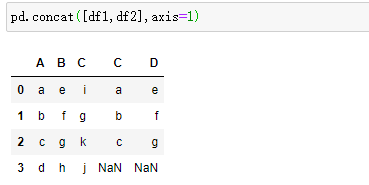
join按索引连接
列名不能重复,重复会出错
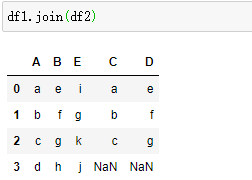
重复时需给出后缀是什么,merge会自动给出

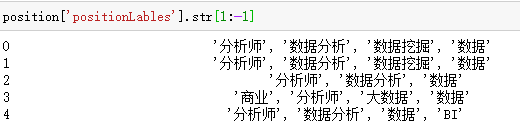
2.4 文本处理
文本分隔split

对某个字段进行统计
因为格式shidataframe,所以对其中的文本进行出席需要调用str。

查找某个字段在哪个位置

读取成str格式再对文本进行处理



空值的处理
将满足条件的值转化为空值:
![]()
将空值填充为1:
![]()
将空值为0的行删除:
![]()
![]()
2.6 apply函数
在series上调用函数
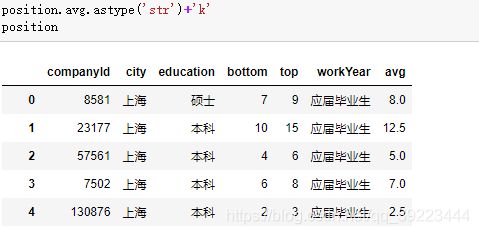
使用匿名函数对值进行处理
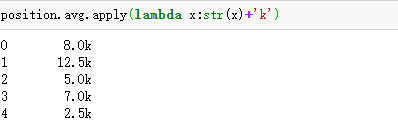
调用函数:

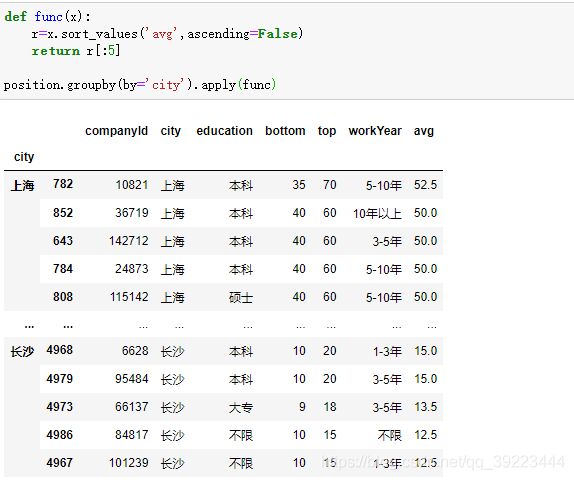
计算每个城市平均工资的前五名

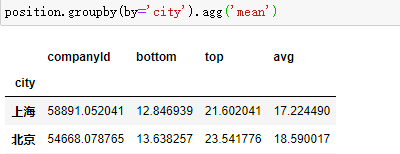
agg

2.7 透视表pivot_table
创建一个电子表格式数据透视表


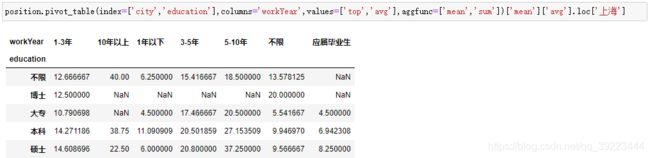
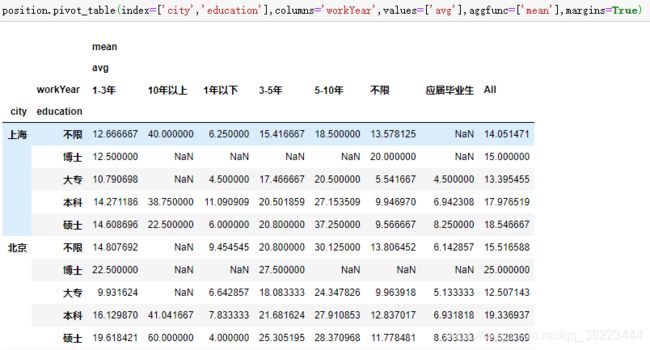

2.8 数据库
pymysql

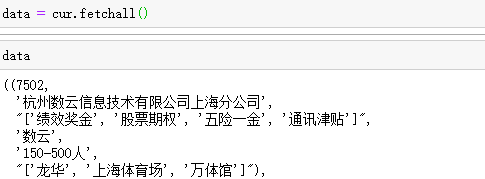
读取data里每行的数据

pandas读取数据库
读取到的是dataframe格式,要结合sqlalchemyku读取
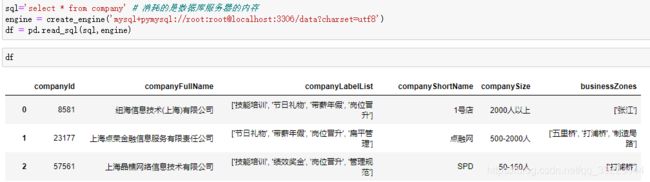
定义函数读取:
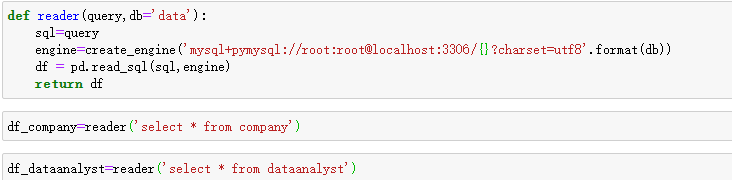
读取部分数据存储
存入数据库
![]()
if_exists:如果数据表已经存在,fail(默认)表示写入失败,append表示插入
index:表示要不要把索引插入
写入后没有格式,不满足数据库存储形式,最好是先在数据库中把字段和列名写入,然后再用代码把数据写入数据库。
del result['city']
如果pandas 操作的要插入的数据少,可以直接插入,数据库会给没有的值赋空,如果超出则会报错。
3 python练习
3.数据可视化
4.数据分析案例
5.数据分析平台
参考链接:【秦路】七周成为数据分析师《第七周:Python》