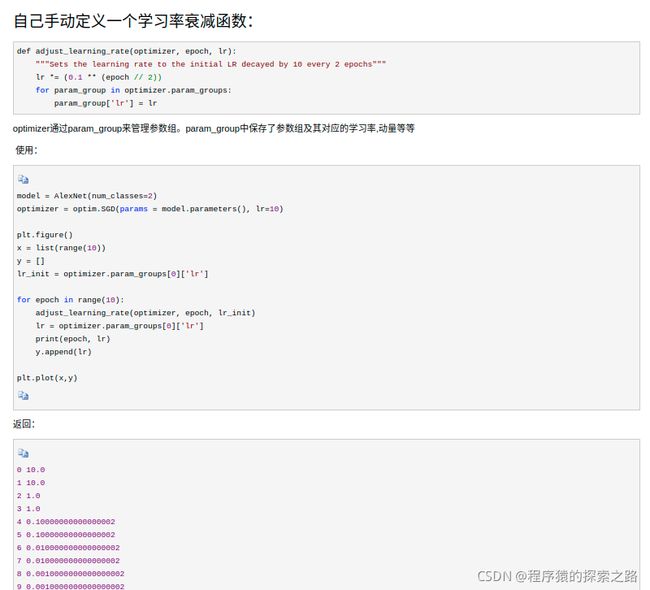
【笔记】pytorch 中学习率调整函数(手动定义一个学习率衰减函数) : torch.optim.lr_scheduler ...
eg:
注1:

注2:
 注3:
注3:
![]()
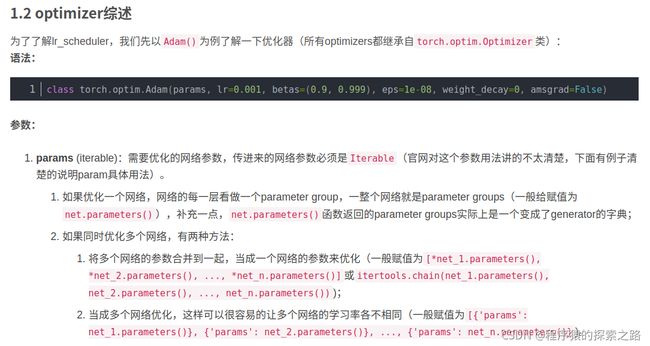
正文:


![]()
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
net_2 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
print("******************optimizer_1*********************")
print("optimizer_1.defaults:", optimizer_1.defaults)
print("optimizer_1.param_groups长度:", len(optimizer_1.param_groups))
print("optimizer_1.param_groups一个元素包含的键:", optimizer_1.param_groups[0].keys())
print()
optimizer_2 = torch.optim.Adam([*net_1.parameters(), *net_2.parameters()], lr = initial_lr)
# optimizer_2 = torch.opotim.Adam(itertools.chain(net_1.parameters(), net_2.parameters())) # 和上一行作用相同
print("******************optimizer_2*********************")
print("optimizer_2.defaults:", optimizer_2.defaults)
print("optimizer_2.param_groups长度:", len(optimizer_2.param_groups))
print("optimizer_2.param_groups一个元素包含的键:", optimizer_2.param_groups[0].keys())
print()
optimizer_3 = torch.optim.Adam([{"params": net_1.parameters()}, {"params": net_2.parameters()}], lr = initial_lr)
print("******************optimizer_3*********************")
print("optimizer_3.defaults:", optimizer_3.defaults)
print("optimizer_3.param_groups长度:", len(optimizer_3.param_groups))
print("optimizer_3.param_groups一个元素包含的键:", optimizer_3.param_groups[0].keys())
输出为:
******************optimizer_1*********************
optimizer_1.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_1.param_groups长度: 1
optimizer_1.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_2*********************
optimizer_2.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_2.param_groups长度: 1
optimizer_2.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_3*********************
optimizer_3.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_3.param_groups长度: 2
optimizer_3.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
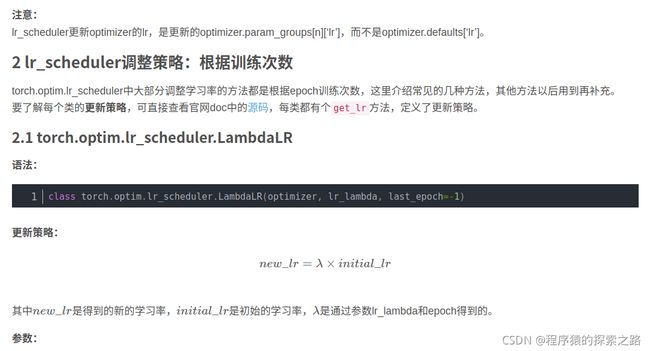
2.1 torch.optim.lr_scheduler.LambdaLR

import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000

补充:
cycleGAN中使用torch.optim.lr_scheduler.LambdaLR实现了前niter个epoch用initial_lr为学习率,之后的niter_decay个epoch线性衰减lr,直到最后一个epoch衰减为0。详情参考:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py 的第52~55行。
2.2 torch.optim.lr_scheduler.StepLR
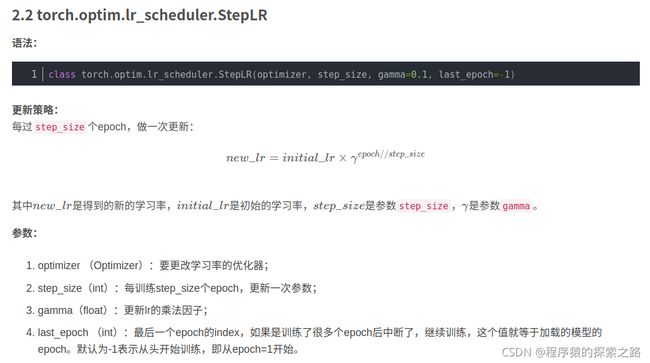 下面举例说明:
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = StepLR(optimizer_1, step_size=3, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
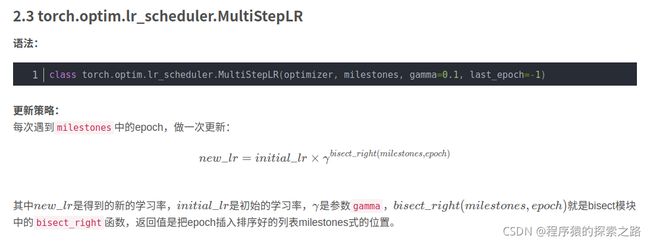
2.3 torch.optim.lr_scheduler.MultiStepLR

import torch
import torch.nn as nn
from torch.optim.lr_scheduler import MultiStepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = MultiStepLR(optimizer_1, milestones=[3, 7], gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出为:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000


import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ExponentialLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ExponentialLR(optimizer_1, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.010000
第3个epoch的学习率:0.001000
第4个epoch的学习率:0.000100
第5个epoch的学习率:0.000010
第6个epoch的学习率:0.000001
第7个epoch的学习率:0.000000
第8个epoch的学习率:0.000000
第9个epoch的学习率:0.000000
第10个epoch的学习率:0.000000
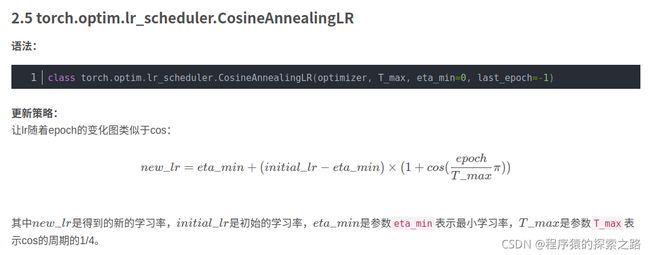

import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR
import itertools
import matplotlib.pyplot as plt
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = CosineAnnealingLR(optimizer_1, T_max=20)
print("初始化的学习率:", optimizer_1.defaults['lr'])
lr_list = [] # 把使用过的lr都保存下来,之后画出它的变化
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lr_list.append(optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
# 画出lr的变化
plt.plot(list(range(1, 101)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()

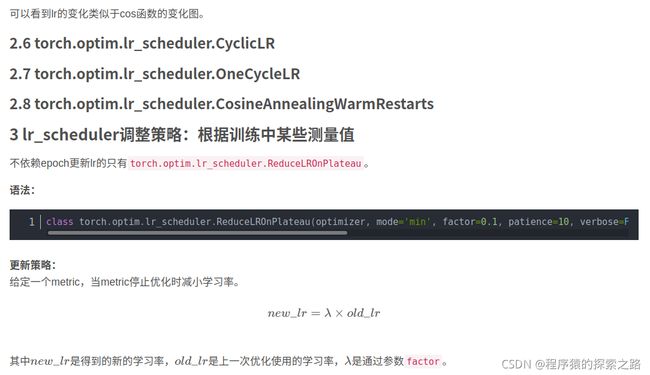
 下面举例说明:
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateau
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ReduceLROnPlateau(optimizer_1, mode='min', factor=0.1, patience=2)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 15):
# train
test = 2
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step(test)
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.100000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000
第11个epoch的学习率:0.000100
第12个epoch的学习率:0.000100
第13个epoch的学习率:0.000100
第14个epoch的学习率:0.000010
附:
pytorch中的学习率调整函数 - 慢行厚积 - 博客园