python中读取文本文件txt
文件创建
f = open(localDirName, 'w')
f.write("something\n")
f.close()
如果文件不存在就是创建,如果文件存在就是打开操作
文件对象创建

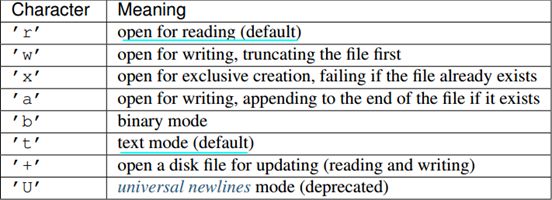

with open('somefile.txt', 'r') as f:
data = f.read()

文件读

以下的函数都是文件对象的成员函数
read()
一次性读取文件的所有内容放在一个大字符串中,即存在内存中
file = open('兼职模特联系方式.txt', 'r') # 创建的这个文件,也是一个可迭代对象
try:
text = file.read() # 结果为str类型
print(type(text))
print(text)
finally:
file.close()readline()
逐行读取文本,结果是一个list
file = open('兼职模特联系方式.txt', 'r')
try:
whileTrue:
text_line = file.readline()
if text_line:
print(type(text_line), text_line)
else:
break
finally:
file.close()readlines()
一次性读取文本的所有内容,结果是一个list
file = open('兼职模特联系方式.txt', 'r')
try:
text_lines = file.readlines()
print(type(text_lines), text_lines)
for line in text_lines:
print(type(line), line)
finally:
file.close()for循环文件对象
最简单、最快速的逐行处理文本的方法
for line in open("test.txt"):
#这里可以进行逻辑处理 csv.DictReader()
with open('names.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row['first_name'], row['last_name'])文件写
write()
f = open("a.txt", 'w')
f.write("写入一行新数据")
f.flush()
f.close()writelines()
f = open('a.txt', 'r')
n = open('b.txt','w+')
n.writelines(f.readlines())
n.close()
f.close()csv.DictWriter()
with open('names.csv', 'w') as csvfile:
fieldnames = ['first_name', 'last_name']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})# 数据
data = [
{'Petal.Length': '1.4', 'Sepal.Length': '5.1', 'Petal.Width': '0.2', 'Sepal.Width': '3.5', 'Species': 'setosa'},
{'Petal.Length': '1.4', 'Sepal.Length': '4.9', 'Petal.Width': '0.2', 'Sepal.Width': '3', 'Species': 'setosa'},
{'Petal.Length': '1.3', 'Sepal.Length': '4.7', 'Petal.Width': '0.2', 'Sepal.Width': '3.2', 'Species': 'setosa'},
{'Petal.Length': '1.5', 'Sepal.Length': '4.6', 'Petal.Width': '0.2', 'Sepal.Width': '3.1', 'Species': 'setosa'}
]
# 表头
header = ['Petal.Length', 'Sepal.Length', 'Petal.Width', 'Sepal.Width', 'Species']
print(len(data))
with open('dst.csv', 'w') as dstfile: # 写入方式选择wb,否则有空行
writer = csv.DictWriter(dstfile, fieldnames=header)
writer.writeheader() # 写入表头
writer.writerows(data) # 批量写入
文件对象的其他操作函数
next()
tell()
seek()
flush()

查找和替换
查找
import re
f = open('/tmp/test.txt')
source = f.read()
f.close()
r = r'hello'
s = len(re.findall(r,source))
替换
for s in f1.readlines():
f2.write(s.replace('hello','hi'))将list或dict保存为文件txt或csv
方法一:
list = ['foo', 'bar']
fl=open('list.txt', 'w')
for i in list:
fl.write(i)
fl.write("\n")
fl.close()
file=open('data.txt','w')
file.write(str(list_data))
file.close()
方法二:
将list或dict转换为Series或DataFrame,再用Series或DataFrame的to_csv()方法
pd.Series(list).to_csv()
pd.Series(dict).to_csv()
方法三:pickle
# dump功能
# dump 将数据通过特殊的形式转换为只有python语言认识的字符串,并写入文件
with open('D:/tmp.pk', 'w') as f:
pickle.dump(data, f)
# load功能
# load 从数据文件中读取数据,并转换为python的数据结构
with open('D:/tmp.pk', 'r') as f:
data = pickle.load(f)多进程写文件
import multiprocessing
print(multiprocessing.current_process().name+”-”+msg)
多进程写文件print
sys.stdout = open(output_pdir/f"print_log.txt", 'w')