图异常检测-Graph Anomaly Detection via Multi-Scale Contrastive Learning Networks with Augmented View
目录
摘要
Introduction
图异常检测早期的工作
Graph Constrastive Learning
Graph Augmentation
Problem Defnition
Method
Graph Augmentation
Graph Contrastive Network
Experiments
Experiment Settings
Model Parameters
Result and Analysis
Ablation Study
Sensitivity Analysis
摘要
图异常检测(GAD)是基于图的机器学习中的一项重要任务,已被广泛应用于许多实际应用中。GAD 的主要目标是从图数据集中捕获异常节点,这些节点明显偏离大多数节点。
最近的方法关注 GAD 的各种规模的对比策略,即节点-子图对比和节点-节点对比。然而,这些方法忽视了子图-子图对比信息,即正常和异常子图对在 GAD 中的嵌入和结构方面表现不同,从而导致任务性能未达到最佳。
在本文中,我们首次提出了具有子图-子图对比的多视图多尺度对比学习框架,以实现上述想法。具体来说,我们将原始输入图视为第一视图,并通过边的修改来生成第二视图。在最大化子图对相似度的指导下,所提出的子图-子图对比有助于提高子图嵌入的鲁棒性,尽管结构会发生变化。
此外,引入的子图-子图对比与广泛采用的节点-子图对比和节点-节点对比能很好地相互配合,共同提高 GAD 性能。
此外,我们还进行了充分的实验来研究不同图增强方法对检测性能的影响。综合实验结果很好地证明了我们的方法与最先进方法相比的优越性,以及多视图子图对对比策略在 GAD 任务中的有效性。源代码发布于 https://github.com/FelixDJC/GRADATE。
Introduction
在过去几年中,基于图的机器学习引起了极大关注(Wu 等 2020 年;Liu 等 2022 年c)。 作为图学习中的一项代表性任务,图异常检测(Graph Anomaly Detection)旨在从大多数节点中发现异常,正成为研究人员越来越关注的应用(Ma 等人,2021 年)。由于其在预防有害事件方面的重要价值,GAD 已被广泛应用于许多领域,如错误信息检测(Wu 等人,2019 年)、金融欺诈检测(Huang 等人,2018 年)、网络入侵检测(Garcia-Teodoro等人,2009 年)等。
与其他异常检测领域的数据不同(Cheng 等 2021a,b;Hu 等 2022),图数据包括节点特征和图结构。这两类信息的不匹配会产生两种典型的异常节点,即特征异常和结构异常(Liu 等,2021 年)。前者指的是在特征方面与邻近节点不同的节点,后者指的是一组不相似但连接紧密的节点。
为了检测这两类异常,以往的许多方法都付出了巨大努力,并取得了令人瞩目的成果。LOF (Breunig 等人,2000 年)通过比较节点与其上下文节点的特征,获取节点的异常信息。SCAN(Xu 等人,2007 年)通过网络结构完成 GAD 任务。通过利用这两类信息,ANOMALOUS(Peng 等人,2018 年)基于 CUR 分解和残差分析检测异常。(Muller 等人 2013 年;Perozzi 等人 ¨ 2014 年)进行特征子空间选择,并在子空间中发现异常节点。上述方法依赖于特定的领域知识,无法挖掘图数据集中的深层非线性信息。这使得它们难以进一步提高检测性能。
得益于强大的图信息获取能力,图卷积网络(GCN)(Kipf 和 Welling,2017 年)最近在许多图数据任务中取得了优异的性能。它很自然地被应用于检测图中的异常。开创性工作 DOMINANT(Ding 等人,2019 年)首次引入 GCN 来完成这项任务。具体来说,DOMINANT 将重组后的特征矩阵和邻接矩阵与原始输入矩阵进行比较。变化较大的节点成为异常点的概率较高。虽然这种方法性能良好,实施简单,但一些异常信息会被忽略。GCN 通过聚合邻域信息生成节点表征,这将使异常信息更加难以区分(Tang 等,2022 年)。基于对比学习范式,CoLA(Liu 等人,2021 年)通过计算节点与其邻域之间的关系来检测异常。这种方法挖掘节点周围的局部特征和结构信息。 与此同时,它掩盖了目标节点的特征,从而减轻了表示平均的影响。与此不同的是,ANEMONE(金等人,2021a)在对比网络中加入了节点-节点对比,重点关注节点级的异常信息。
然而,现有的工作忽略了对子图信息的进一步利用,并且没有直接优化其嵌入以进行图异常检测。 (Jiao 等人,2020 年;Hafdi 等人,2022 年;Han 等人,2022 年)已经证明,子图表示学习有利于基于图的机器学习任务。它将极大地促进挖掘各个子图的局部特征和结构信息。对于GAD,更具代表性和内在的子图嵌入可以帮助计算节点及其邻域之间更可靠的关系,这是对比策略中的关键步骤。
为了解决这个问题,我们通过多尺度对比学习网络提出了一个新的图形异常检测框架,并添加了新添加的子图-子图对比和 Augmented 视图(称为 GRADATE)。具体来说,我们将原始输入图视为第一视图,并采用边修改作为图增广技术来生成第二视图。在每个视图中,子图都是通过随机游走进行采样的。然后,我们构建一个具有节点-子图、节点-节点和子图-子图对比的多视图对比网络。前两个对比可以从每个视图捕获子图级和节点级异常信息。子图-子图对比度是在两个视图之间定义的,并挖掘更多的局部异常信息进行检测。这样,节点-子图对比度将明显增强。之后,我们结合各种异常信息并计算每个节点的异常分数。最后,我们探索并分析了不同图增强对 GAD 中子图表示学习的影响。我们的主要贡献如下:
我们在第一个实践中引入了与 GAD 的子图-子图对比,并提出了一种具有增强视图的多尺度对比学习网络框架。
我们研究了不同的图增强对任务的子图表示学习的影响。
对六个基准数据集进行的大量实验证明了基于边缘修改的子图-子图对比策略在图异常检测方面的有效性以及GRADATE 与最先进方法相比的优越性。
图异常检测早期的工作
(Li et al. 2017;Perozzi and Akoglu 2016;Peng et al. 2018)通常采用非深度范式,从节点特征和网络结构中检测异常信息。然而,如果不挖掘更深入的信息,他们就无法不断提高自己的表现。近年来,神经网络的兴起(Tu et al. 2021, 2022;Liang et al. 2022;Liu et al. 2022c)增强了模型挖掘深层非线性信息的能力。基于重建的方法 DOMINANT (Ding et al. 2019) 通过计算 GCN 之后的特征和结构矩阵的变化来获得节点异常分数。 AAGNN (Zhou et al. 2021) 在图异常检测中应用了 oneclass SVM。 HCM(Huang et al. 2021)将节点及其一阶邻居的跳数估计视为其异常分数。 CoLA (Liu et al. 2021) 首先引入对比学习范式 (Yang et al. 2022b,a) 来检测图中的节点异常。后来的方法(Jin et al. 2021a;Zheng et al. 2021;Zhang, Wang, and Chen 2022;Duan et al. 2022)在CoLA的基础上做了进一步的改进.
Graph Constrastive Learning
对比学习是无监督学习中最重要的范式之一。图对比学习在没有昂贵标签的情况下挖掘下游任务的监督信息,并取得了巨大的成就(Liu et al. 2022a)。
根据负样本使用策略,现有作品可以分为基于负样本和无负样本两个子类别。对于第一种类型,DGI(Velickovic et al. 2019)最大化节点和图之间的互信息以获得有用的监督信息。 SUBG-CON (Jiao et al. 2020) 和 GraphCL (Hafdi et al. 2022) 形成节点子图对比,以学习更好的节点表示。对于第二种类型,BGRL(Thhakoor et al. 2021)应用暹罗网络从两个视图中获取丰富的信息。 (Liu et al. 2022b,d,e) 利用了 Barlow Twins (Zbontar et al. 2021) 的优势,它设计了一个特殊的损失函数来避免表示崩溃。
Graph Augmentation
图增强产生了图数据集的合理变化(Ding et al. 2022)。它扩展了数据集并提高了模型的泛化能力,而无需昂贵的标签(Zhao et al. 2022)。大多数方法侧重于图中节点或边的操作。 (Wang et al. 2021;Feng et al. 2020;You et al. 2020)注意修改节点特征。 RoSA(Zhu et al. 2022)使用带有重启的随机游走作为图增强来学习节点的鲁棒表示。 (Klicpera、Weißenberger 和 Gunnemann 2019;Zhao 等人 2021)通过添加或删除边来调整邻接矩阵。
Problem Defnition
在下一节中,我们将图异常检测任务形式化。对于给定的无向图G=(V,E)
Method
在本节中,我们介绍建议的框架 GRADATE。它由两个主要模块组成。
在图增强模块中,我们将原始图视为第一个视图,并通过边缘修改生成第二个视图。
在图对比网络模块中,我们首先从节点和子图的特征比较中获得异常信息,将其视为节点-子图对比。
对于每个视图,子图通过随机游走进行采样,并与目标节点形成对。然后我们构建节点间对比来捕获节点级异常。
新添加的子图-子图对比直接优化了两个视图之间 GAD 的子图嵌入。
在此过程中,节点-子图对比的性能将得到提升。
之后,我们采用集成损失函数来训练这三个对比。最后,我们综合各种异常信息并计算每个节点的异常得分。
Graph Augmentation
图增强对于自监督学习范式至关重要。它可以帮助模型挖掘图更深层的语义信息。在本文中,我们利用边缘修改来创建第二个视图。然后我们通过随机游走对子图进行采样。节点和子图将形成图对比网络的输入。
边缘修改。
边缘修改 (EM) 通过扰动图形边缘来构建第二个视图。受(Jin et al. 2021b)的启发,我们不仅删除邻接矩阵中的边,还同时添加相同数量的边。在实践中,我们首先设置一个固定比例P,以从邻接矩阵中均匀随机地删除PM/2 边。然后将PM/2 边均匀且随机地添加到矩阵中。通过这种方式,我们尝试在不破坏图的属性的情况下学习子图的鲁棒表示。消融研究部分将进一步讨论用于生成第二视图的图增强方法。
随机游走。
对于目标节点,一种有效的异常检测方法是测量它与其邻域之间的特征距离(Liu et al. 2021)。因此,我们采用重新启动随机游走(RWR)(Qiu et al. 2020)来对节点周围的子图进行采样。特征相似度越低,表明目标节点的异常程度越高。
Graph Contrastive Network
对比学习范式已被证明对 GAD 有效(Liu et al. 2021)。我们构建了一个多视图图对比网络,它包括三部分,即节点子图、节点-节点和子图-子图对比。前两个对比在每个视图中定义,并将通过两个视图的信息融合得到加强。节点子图对比主要用于捕获节点邻域的异常信息。第二个对比可以更好地检测节点级异常谎言。与此同时,子图-子图对比在两种视图之间起作用。它将直接优化 GAD 的子图嵌入,这显着有利于节点-子图对比.
节点子图对比。目标节点vi与其所在的子图形成正对,并与另一个节点vj所在的随机子图形成负对。我们首先采用 GCN 层,将子图中节点的特征映射到嵌入空间。值得注意的是,子图中目标节点的特征被屏蔽,即设置为0。子图隐藏层表示可以定义为:

然后,通过 Readout 函数计算子图的最终表示 zi 。具体来说,我们利用平均函数来实现 Readout:

相应地,我们利用 MLP 将目标节点特征转换到与子图相同的嵌入空间。节点隐藏层表示为:
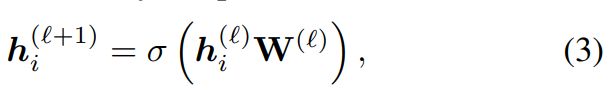
在每个视图中,目标节点的异常程度与子图的相似度![]() 和节点嵌入相关。我们采用双线性模型来衡量这种关系:
和节点嵌入相关。我们采用双线性模型来衡量这种关系:
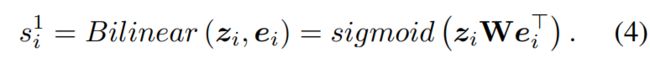
一般来说,目标节点和子图表示在正对中趋于相似,即![]() = 1。因此,我们采用二元交叉熵(BCE)损失(Velickovic 等人,2019 年)来训练对比度。
= 1。因此,我们采用二元交叉熵(BCE)损失(Velickovic 等人,2019 年)来训练对比度。
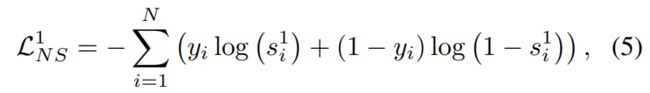
其中 yi 在正数对中等于 1,在负数对中等于 0。
我们还可以从另一个视图中得到相似度 ![]() 和 BCE 损失
和 BCE 损失 ![]() 。值得一提的是,两个视图下的两个网络使用相同的架构,共享参数。因此,最终的节点子图对比度损失
。值得一提的是,两个视图下的两个网络使用相同的架构,共享参数。因此,最终的节点子图对比度损失
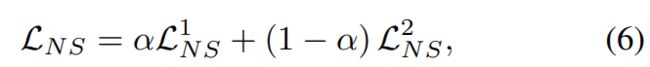
其中,α∈(0,1)是一个权衡参数,用于平衡两个 vi 之间的重要性。
节点-节点对比。节点-节点对比可以有效发现节点级的异常。同样,目标节点特征将被屏蔽。而它的表示是从子图中的其他节点聚合而来的。在每个视图中,经过 MLP 后,它与同一节点形成正对,经过 MLP 后,它与另一节点形成负对。我们利用新的 GCN 来获得子图的表示。
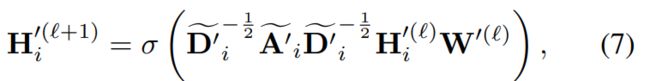
与此同时,我们使用 MLP 将节点特征映射到相同的隐藏空间:

与节点-子图对比类似,我们采用双线性模型来评估 ui 和 eˆi 之间的关系 ![]() 。 那么节点-节点对比损失函数可以定义为
。 那么节点-节点对比损失函数可以定义为
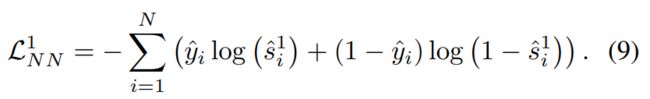
同样,也可以计算另一个视图的相似度![]() 和损失 L 2 NN。因此,最后的节点-节点对比度损失函数
和损失 L 2 NN。因此,最后的节点-节点对比度损失函数
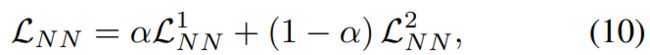
其中,视图平衡参数 α 与节点子图对比度损失共享。
子图-子图对比。子图-子图对比是在两个视图之间定义的。其目的是为 GAD 学习更具代表性和内在性的子图嵌入,从而帮助节点-子图对比判别节点及其邻域的关系。在实践中,我们直接在节点-子图对比的联合损失下优化子图表示。
子图与扰动子图形成正对,其中相同的目标节点 vi 位于另一个视图中。与常见的图对比方法(You et al. 2020)不同,它与另一个节点 vj 位于两个视图中的两个子图形成负对。节点 vj 与节点子图对比中与 vi 形成负对的子图相同。受(Oord、Li 和 Vinyals 2018)的启发,我们采用损失函数来优化.
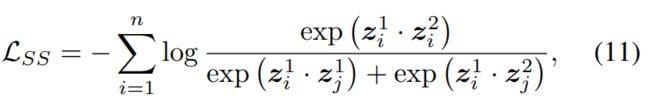
损失函数。为了综合三种对比的优点,我们优化联合损失函数:

异常分数计算。在节点-子图和节点节点对比中,正常节点与其正对中的子图或节点相似,而与其负对中的子图或节点不相似。相反,异常节点与正对和负对中的节点或子图都不相似。当然,我们定义目标节点的异常分数如下:

然后我们综合融合两个视图和三个对比的异常信息。异常分数可以进一步表示为:
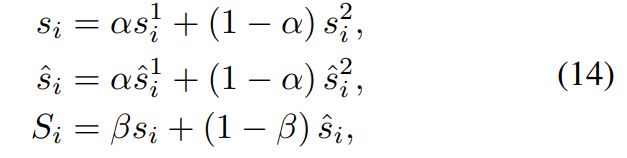
仅使用一次随机游走的一次检测无法捕获足够的语义信息。多轮检测对于计算每个节点的异常分数至关重要。受(Jin et al. 2021a)的启发,我们通过多轮检测结果的平均值和标准差计算最终异常分数:

其中 R 是异常检测轮数。总的来说,GRADATE的整体流程如算法1所示。

Experiments
我们在六个图基准数据集上进行了广泛的实验,以验证 GRADARE 的优异性能。结果还证实了子图对比和边缘修改对于 GAD 的有效性。
Experiment Settings
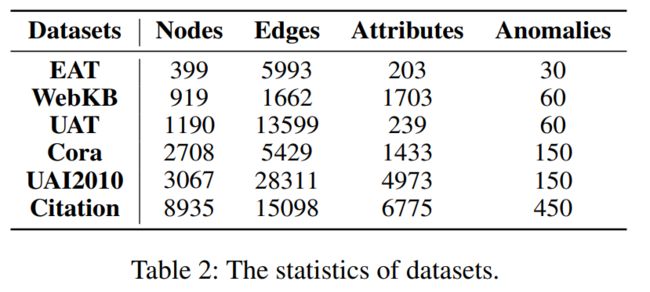
实验设置详情如下: (1)数据集。所提出的方法在六个基准数据集上进行了评估,详细信息如表 2 所示。
数据集包括 Citation (Yuan et al. 2021)、Cora (Sen et al. 2008)、WebKB (Craven et al. 1998)、UAI2010 (Wang等人,2018)、UAT 和 EAT(Mrabah 等人,2022)。
(2)异常注入。在 DOMINANT 之后,我们将相同数量的特征和结构异常注入到之前没有异常节点的原始数据集中。每个数据集的异常总数显示在表2的最后一列中。
(3)基线。对于 GAD 任务,我们与八种众所周知的基线方法进行比较。表 3 的第一列总结了它们。前两个模型是非深度算法,其余模型基于图神经网络。遵循 CoLA,在运行 ANOMALOUS 之前,所有数据集的节点特征都通过 PCA 减少到 30。
(4)公制。我们采用广泛使用的异常检测指标 AUC 来评估上述方法。
Model Parameters
在节点-子图和子图-子图对比中,两个 GCN 模型都有一层并使用 ReLU 作为激活函数。网络中子图的大小设置为4。节点和子图特征都映射到隐藏空间中的64维。此外,我们还进行了 400 轮模型训练和 256 轮异常得分计算。
Result and Analysis
在本小节中,我们通过将 GRADATE 与八种基线方法进行比较来评估 GRADATE 的异常检测性能。图 2 显示了九个模型的 ROC 曲线。同时,表3给出了图2对应的AUC值的对比结果。对于结果,我们有以下结论:

(图 2:六个基准数据集的 ROC 曲线。曲线下面积越大,异常检测性能越好。黑色虚线是“随机线”,表示随机猜测下的性能)
我们可以直观地发现 GRADATE 在这六个数据集上优于竞争对手。具体而言,GRADATE 在 EAT、WebKB、UAT、Cora、UAI2010 和 Citation 上的 AUC 分别实现了 2.54%、0.62%、3.64%、0.45%、5.31% 和 0.43% 的显着增长。如图 2 所示,GRADATE 的曲线下区域明显大于竞争对手。
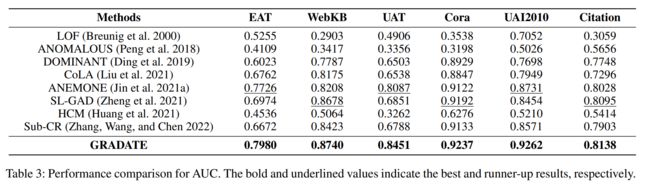
我们观察到大多数基于神经网络的方法优于浅层方法、LOF 和 ANOMALOUS。浅层方法在处理图数据的高维特征方面具有固有的局限性。
在深度方法中,基于对比学习的方法,CoLA、ANEMONE、SL-GAD、Sub-CR 和 GRADATE 效果较好。这表明基于对比学习的模式可以通过挖掘图的特征和结构信息来有效地检测异常。通过新添加的子图-子图对比和多视图学习策略,GRADATE 取得了最佳性能。
Ablation Study
各种规模的对比策略。为了验证所提出的子图-子图对比的有效性,我们进行了消融研究实验。为了方便起见,NS、NS+SS、NS+NN 和 NS+NN+SS 表示仅使用节点-子图对比(CoLA)、使用节点-子图和子图-子图对比、使用节点-子图和节点-节点对比( ANEMONE),并分别使用上述三个对比(GRADATE)。如表 4 所示,添加子图-子图对比度可以通过提高节点-子图对比度来增强检测性能。使用所有三种对比将获得最佳性能。

图增强策略。同时,我们采用四种不同的图增强来形成第二个视图并探讨它们对性能的影响。高斯噪声特征(GNF)是指节点特征受到高斯噪声的随机扰动。特征掩码(FM)表示节点特征的随机部分被掩码。图扩散(GD)利用由扩散模型生成的图扩散矩阵(Hassani 和 Khasahmadi 2020;Klicpera、Weißenberger 和 Gunnemann 2019)。 ¡ GNF 和 FM 是节点特征的扰动。 GD 和边缘修改(EM)是广泛使用的图边缘图增强方法。如表 5 所示,EM 在所有数据集上均取得了最佳性能。进一步分析,节点特征的扰动可能会扰乱正常节点的特征。这会损害节点与其邻域之间的比较,而这是 GAD 对比学习的基础。这可能会导致一些正常节点被错误分类为异常并导致性能下降。此外,GD是一种基于结构的图增广方法。然而,其主要目的是捕获全球信息。因此,EM比GD更兼容子图-子图对比,可以提高节点-子图对比来挖掘节点的局部邻域信息。

Sensitivity Analysis
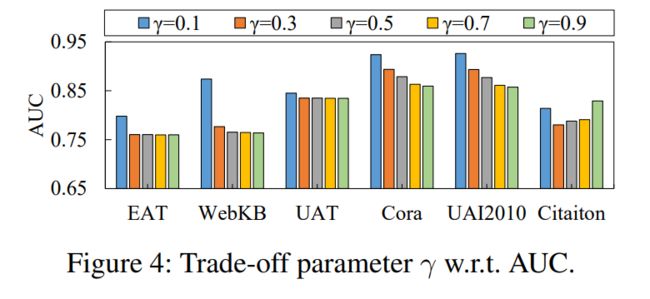
平衡参数α、β和γ。我们讨论损失函数中的三个重要的平衡参数。如图3所示,超参数α和β有效提高了EAT和UAI2010的检测性能。在其他数据集上也可以观察到类似的现象。实际上,我们在 EAT、WebKB、UAT、Cora、UAI2010 和 Citation 上将 α 设置为 0.9、0.1、0.7、0.9、0.7 和 0.5。同时,我们将β设为0.3、0.7、0.1、0.3、0.5和0.5。

图 4 说明了当 γ 从 0.1 变化到 0.9 时 GRADATE 的性能变化。从图中,我们观察到,通过在所有基准测试中将 γ 设置为 0.1,GRADATE 往往表现良好。
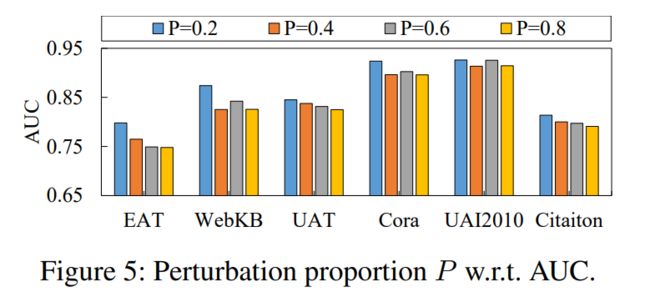
边缘修改比例 P。我们还研究了不同参数化边缘修改的影响。图5显示,在UAT、UAI2010和Citation上,检测性能因修改比例P而受到相对较小的波动。综合而言,我们在所有数据集上固定设置 P = 0.2。