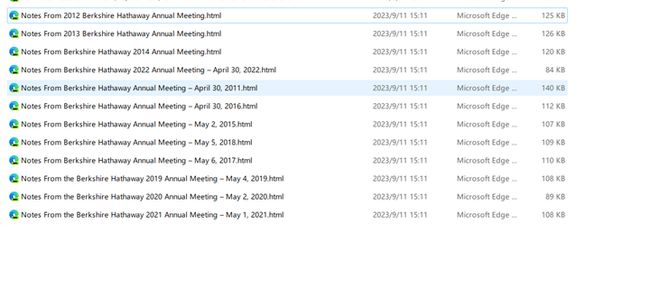
零代码编程:用ChatGPT批量下载网站中的特定网页内容
http://blog.umd.edu/davidkass这个网站上有伯克希尔股东大会的一些文字稿,其标题如下:
Notes From the Berkshire Hathaway 2020 Annual Meeting – May 2, 2020
Notes From the Berkshire Hathaway 2021 Annual Meeting – May 1, 2021
在右边的搜索框输入关键词:Notes From Berkshire Hathaway
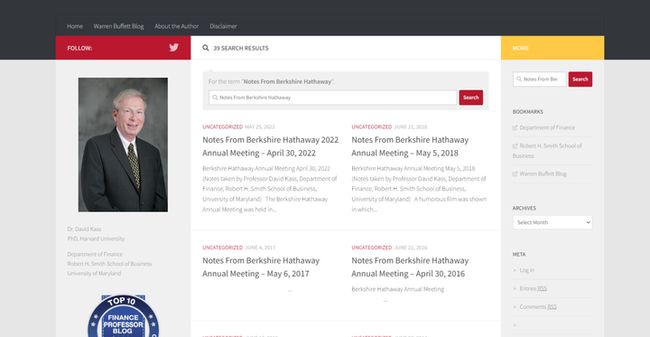
可以看到网站所有的股东大会文字稿,总共两页
第一页网址是:https://blog.umd.edu/davidkass/?s=Notes+From+Berkshire+Hathaway
第二页是:https://blog.umd.edu/davidkass/page/2/?s=Notes+From+Berkshire+Hathaway
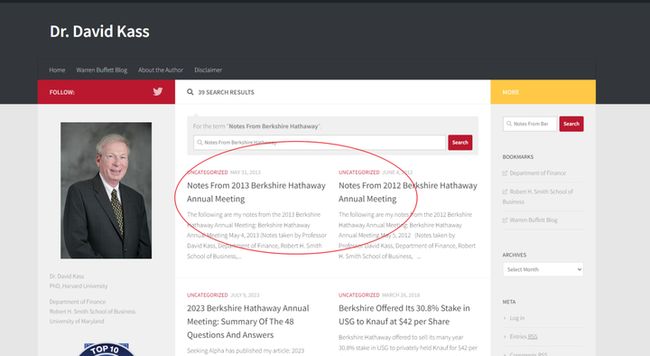
每个网页的元素源代码如下:
Notes From Berkshire Hathaway 2022 Annual Meeting – April 30, 2022
要把这两页中所有的网页内容下载下来,可以在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个批量下载网页的任务,具体步骤如下:
打开网站:
https://blog.umd.edu/davidkass/page/【pagenumber】/?s=Notes+From+Berkshire+Hathaway
其中,pagenumber参数的值是从1到2;
定位所有rel="bookmark"的a元素;
提取a元素的内容作为网页文件名;
提取a元素的href作为网页下载地址:
下载网页内容,保存到电脑E盘;
注意:每一步都要输出相关信息

具体的Python代码如下:
import requests
from bs4 import BeautifulSoup
import os
# 设置保存网页的文件夹路径
output_folder = 'E:/web_pages'
# 确保文件夹存在,如果不存在则创建它
os.makedirs(output_folder, exist_ok=True)
# 循环遍历页码范围(1到2)
for page_number in range(1, 3):
# 构建网页URL
url = f'https://blog.umd.edu/davidkass/page/{page_number}/?s=Notes+From+Berkshire+Hathaway'
# 发送HTTP请求并获取网页内容
response = requests.get(url)
if response.status_code == 200:
print(f'正在下载第 {page_number} 页...')
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 定位所有rel="bookmark"的a元素
bookmark_links = soup.find_all('a', rel='bookmark')
# 循环处理每个a元素
for link in bookmark_links:
# 提取文件名
file_name = link.text.strip()
# 提取下载地址
download_url = link['href']
# 发送HTTP请求并保存网页内容
page_response = requests.get(download_url)
if page_response.status_code == 200:
# 构建保存路径
save_path = os.path.join(output_folder, f'{file_name}.html')
# 保存网页内容到文件
with open(save_path, 'wb') as file:
file.write(page_response.content)
print(f'已下载:{file_name}.html')
else:
print(f'无法访问网页:{url}')
print('任务完成!')
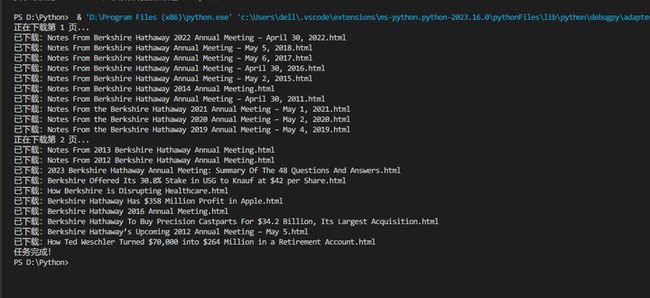
运行程序,全部下载完成: