iceberg总结简介
1.iceberg基本概念
Apache Iceberg 是一种用于大型分析数据集的开放 Table Format(表格式)。专为大型表设计,单表可以处理 PB 级的数据。Iceberg 旨在解决最终一致的云对象存储中的正确性问题,Iceberg 可以在没有分布式 SQL 的情况下读取 PB 级别的表。
Table Format 是数据库系统在实现层面上的一个抽象概念,是数据存储的一种模型,其中定义了表的元数据信息以及数据文件的组织形式、统计信息以及上层引擎读取和写入的相关 API,与其相对应的是 File Format。
Iceberg 介于数据文件之上,计算之下,在数据仓库中的位置如下:
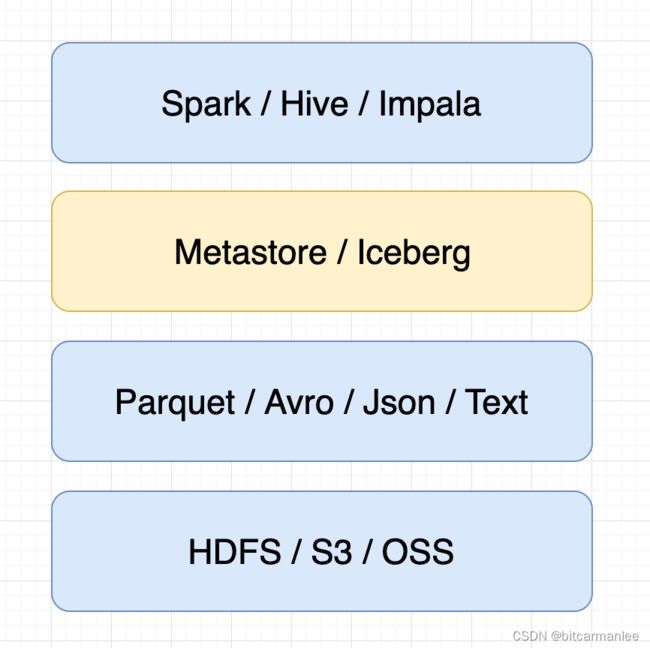
2.iceberg的演化
2.1 Schema 演化
其实我更愿意称之为 Scheme Evolution,而不是表结构演变。更改表结构在 Hive 中更改表结构是一个非常重的操作,代价比较昂贵。比如简单的 rename、修改分区等操作,都需要重新建表重新写数据。但是 Iceberg 支持就地更改 Schema,并可以保证数据准确性。
Iceberg 支持的 Schema 修改操作:
Add:在表或嵌套结构中新增列
Drop:从表或嵌套结构中删除列
Rename:重命名表或嵌套结构中的字段名
Update:修改表或嵌套结构中的字段类型
Reorder:修改表或嵌套结构中的字段顺序
2.2 Partition 演化
更改分区是元数据级别的操作,不会像 Hive 一样有重写数据的操作。当修改 Iceberg 表中的分区规则时,修改之前的数据还是按照以前的分区方式存储,而修改之后的数据才会按照新的规则存储,修改前后的分区元数据是分开存储的,这就意味着在同一个表中允许存在多种分区策略。
比如 2008 年的数据是按照 month 做分区的,但是从 2009 开始用 day 做分区。查询过程中 Iceberg 会自动裁剪文件。

2.3 Sort Order 演化
更改排序规则和更改分区规则类似,修改前后的顺序依然按照各自规则各自存储,互不影响。
3.Iceberg 分区
3.1 Iceberg 中分区的特点
1.Iceberg 选中数据行中的某个字段作为分区,分区信息是记录至文件级别的。而 Hive 中选取的分区字段是以目录的形式出现的,最终的物理数据文件中(如 parquet 文件)是没有存储分区字段,也就是说 Hive 的分区是在目录级别的。
2.Iceberg 提供的隐藏分区可以根据查询条件自动过滤不需要的分区数据,使用者不需要关心表的分区字段,也不需要根据分区字段额外指定查询条件。
3.Iceberg 查询不再依赖于表的物理布局。随着物理和逻辑的分离,Iceberg 表可以随着数据量的变化而随着时间的推移演变分区方案,也就是说一个表中可以同时允许多个分区策略。
4.Iceberg 中针对每个数据文件都有记录了它的元数据信息,以及相关的统计信息。如:最大值、最小值、总行数、为 null 的行数等。
3.2 隐藏分区
隐藏分区,顾名思义就是将分区信息隐藏起来。开发人员只需要建表时指定分区策略,Iceberg 会根据分区策略跟踪该表字段与物理存储的数据文件之间的逻辑关系。使用者在插入和读取的时候不需要关心表的分区布局,不需要像 Hive 那样显示地指定分区字段,只需要关心业务逻辑即可。Iceberg 会在插入数据的时候根据分区策略跟踪新数据的分区信息,并将其记录在元数据中;查询的时候也会根据自动过滤掉不需要扫描的文件。
在 Hive 中使用分区,需要明确指定分区字段,而这些分区字段最终都会以目录的形式出现在文件系统中,其数据文件中不会出现。假设创建以下 Hive 表并插入一条数据:
create table user_log_1 (
imei string,
uuid string
)
partitioned by (udt string comment 'yyyy-MM-dd');
insert into user_log_1 partition (udt='2022-01-01') values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy');
该表中的数据在文件系统中的组织形式是这样的:
user_log_1/
└── udt=2022-01-01
├── _SUCCESS
└── part-00000-1f6ad6a0-3536-42f1-b354-d4ccb34a7939-c000
如果建表语句中指定 year、month、day 三个字段作为分区字段,并插入一条数据:
create table user_log_2 (
imei string,
uuid string
)
partitioned by (year int, month int, day int);
insert into user_log_2 partition (year=2022, month=1, day=1) values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy');
该表中的数据在文件系统中的组织形式是这样的:
user_log_2/
└── year=2022
└── month=1
└── day=1
├── _SUCCESS
└── part-00000-21bbea3f-350d-4b3f-a820-2d846184d9fc-c000
但是如果使用 Iceberg 来建表并插入一条数据:
create table hadoop_catalog.iceberg_db.user_log_iceberg (
imei string,
uuid string,
udt timestamp
)
using iceberg
partitioned by (days(udt));
insert into hadoop_catalog.iceberg_db.user_log_iceberg values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy', cast(1640966400 as timestamp));
查看表 user_log_iceberg 在文件系统中的存储结构:
user_log_iceberg/
├── data
│ └── udt_day=2021-12-31
│ └── 00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet
└── metadata
├── f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro
├── snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro
├── v1.metadata.json
├── v2.metadata.json
└── version-hint.text
其中data目录存储的是数据文件,metadata目录存储的是表的元数据信息,后续会详细介绍。
经过前面几个操作中,我们发现有以下几个不同:
1.在创建表 Iceberg 表的时候并没有像创建 Hive 表那样将分区字段放在partitioned by子句中,而是和其它字段一样放在表名后面的括号中,只是在partitioned by (days(udt))中指定了我们分区策略和udt字段之间的逻辑关系。
2.Iceberg 表中插入数据的 SQL 相比 Hive 的插入 SQL 而言少了partition (year=2022, month=1, day=1)部分,也就是说没有额外去指定分区信息。
3.物理存储方面,Hive 的两个表数据文件part-00000-1f6ad6a0-3536-42f1-b354-d4ccb34a7939-c000和part-00000-21bbea3f-350d-4b3f-a820-2d846184d9fc-c000中没有udt、year、month、day几个分区字段的信息,分区字段体现在了目录中,但是在 Iceberg 表中,所有的字段数据都在00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet文件中,且自动转换了分区策略和字段时间的关系。
4.Hive 表中如果要使用分区键进行查询,开发人员必须先查看该表的建表语句以了解该表的物理存储方式,但使用 Iceberg 表时不需要关心物理存储。
5.假设在使用表user_log_1的时候将查询条件中的条件指定为udt = ‘20220101’(日期格式为 yyyyMMdd),查询不会报错,但是可能会返回一个错误的结果。
在user_log_iceberg表中的分区策略中使用到了days函数,将timestamp中的day作为分区属性,实际上除了将timestamp转换为day,还支持其它转换:
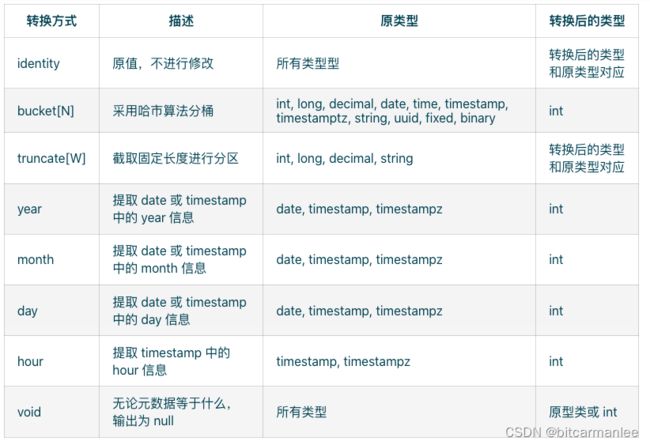
4.Iceberg 文件组织形式
使用以下 SQL 创建名为user_log_iceberg的 Iceberg 表并插入一条数据:
create table hadoop_catalog.iceberg_db.user_log_iceberg (
imei string,
uuid string,
udt timestamp
)
using iceberg
partitioned by (days(udt));
insert into hadoop_catalog.iceberg_db.user_log_iceberg values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy', cast(1640966400 as timestamp));
user_log_iceberg 在文件系统中的存储结构为:
user_log_iceberg/
├── data
│ └── udt_day=2021-12-31
│ └── 00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet
└── metadata
├── f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro
├── snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro
├── v1.metadata.json
├── v2.metadata.json
└── version-hint.text
可以看到该表目录下有两个子文件夹:data 和 metadata。其中 data 就是真正的数据文件目录,metadata 是该表的元数据目录,这里的 metadata 就是替代 Hive 中的 Metastore 服务的。
在了解 Iceberg 元数据管理之前先看几个概念:
Snapshot
Snapshot 就是表在某个时间点的状态,其中包括该时间点所有的数据文件。Iceberg 对表的每次更改都会新增一个 Snapshot。
Metadata File
每新增一个 Snapshot 就会新增一个 Metadata 文件,该文件记录了表的存储位置、Schema 演化信息、分区演化信息以及所有的 Snapshot 以及所有的 Manifest List 信息。
Manifest List
Manifest List 是一个元数据文件,其中记录了所有组成快照的 Manifest 文件信息。
Manifest File
Manifest File 是记录 Iceberg 表快照的众多元数据文件的其中一个。其中的每一行都记录了一个数据文件的分区,列级统计等信息。 一个 Manifest List 文件中可以包含多个 Manifest File 的信息。
Partition Spec
表示字段值和分区值之间的逻辑关系。
Data File
包含表中所有行的文件。
Delete File
对按位置或数据值删除的表行进行编码的文件。

从上图中可以看出 Iceberg 表通过三级关系管理表数据,下面以 Spark 中的 spark.sql.catalog.hadoop_prod.type=hadoop 为例说明。:
最上层中记录了 Iceberg 表当前元数据的版本,对应的是version-hint.text文件,version-hint.text文件中只记录了一个数字表示当前的元数据版本,初始为 1,后续表每变更一次就加 1。
中间层是元数据层。其中 Metadata File 记录了表的存储位置、Schema 演化信息、分区演化信息以及所有的 Snapshot 和 Manifest List 信息,对应的是v1.metadata.json和v2.metadata.json文件,其中v后面的数字和version-hint.text文件中的数字对应,每当新增一个 Snapshot 的时候,version-hint.text中的数字加 1,同时也会新增一个vx.metadata.json文件,比如执行insert into hadoop_catalog.iceberg_db.user_log_iceberg values (‘xxxxxxxxxxxxx’, ‘yyyyyyyyyyyyy’, cast(1640986400 as timestamp))、delete from hadoop_catalog.iceberg_db.user_log_iceberg where udt = cast(1640986400 as timestamp)之后,版本就会变成v4:
user_log_iceberg/
├── data
│ └── udt_day=2021-12-31
│ ├── 00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet
│ └── 00000-0-88d582ef-605e-4e51-ba98-953ee3dd4c02-00001.parquet
└── metadata
├── b3b1643b-56a2-471e-a4ec-0f87f1efcd80-m0.avro
├── ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro
├── f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro
├── snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro
├── snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro
├── snap-8046643380197343006-1-b3b1643b-56a2-471e-a4ec-0f87f1efcd80.avro
├── v1.metadata.json
├── v2.metadata.json
├── v3.metadata.json
├── v4.metadata.json
└── version-hint.text
查看v4.metadata.json中的内容如下:
{
"format-version": 1,
"table-uuid": "c69c9f46-b9d8-40cf-99da-85f55cb7bffc",
"location": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg",
"last-updated-ms": 1647772606874,
"last-column-id": 3,
"schema": {
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "imei",
"required": false,
"type": "string"
},
{
"id": 2,
"name": "uuid",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "udt",
"required": false,
"type": "timestamptz"
}
]
},
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "imei",
"required": false,
"type": "string"
},
{
"id": 2,
"name": "uuid",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "udt",
"required": false,
"type": "timestamptz"
}
]
}
],
"partition-spec": [
{
"name": "udt_day",
"transform": "day",
"source-id": 3,
"field-id": 1000
}
],
"default-spec-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": [
{
"name": "udt_day",
"transform": "day",
"source-id": 3,
"field-id": 1000
}
]
}
],
"last-partition-id": 1000,
"default-sort-order-id": 0,
"sort-orders": [
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "PowerYang"
},
"current-snapshot-id": 4140724156423386600,
"snapshots": [
{
"snapshot-id": 6744647507914919000,
"timestamp-ms": 1647758232673,
"summary": {
"operation": "append",
"spark.app.id": "local-1647757937137",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1032",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1032",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro",
"schema-id": 0
},
{
"snapshot-id": 8046643380197343000,
"parent-snapshot-id": 6744647507914919000,
"timestamp-ms": 1647772293740,
"summary": {
"operation": "append",
"spark.app.id": "local-1647770527459",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1032",
"changed-partition-count": "1",
"total-records": "2",
"total-files-size": "2064",
"total-data-files": "2",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-8046643380197343006-1-b3b1643b-56a2-471e-a4ec-0f87f1efcd80.avro",
"schema-id": 0
},
{
"snapshot-id": 4140724156423386600,
"parent-snapshot-id": 8046643380197343000,
"timestamp-ms": 1647772606874,
"summary": {
"operation": "delete",
"spark.app.id": "local-1647770527459",
"deleted-data-files": "1",
"deleted-records": "1",
"removed-files-size": "1032",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1032",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro",
"schema-id": 0
}
],
"snapshot-log": [
{
"timestamp-ms": 1647758232673,
"snapshot-id": 6744647507914919000
},
{
"timestamp-ms": 1647772293740,
"snapshot-id": 8046643380197343000
},
{
"timestamp-ms": 1647772606874,
"snapshot-id": 4140724156423386600
}
],
"metadata-log": [
{
"timestamp-ms": 1647757946953,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v1.metadata.json"
},
{
"timestamp-ms": 1647758232673,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v2.metadata.json"
},
{
"timestamp-ms": 1647772293740,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v3.metadata.json"
}
]
}
可以看到snapshots属性中记录了多个 Snapshot 信息,每个 Snapshot 中包含了 snapshot-id、parent-snapshot-id、manifest-list 等信息。通过最外层的 current-snapshot-id 可以定位到当前 Snapshot 以及 manifest-list 文件为/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro。使用java -jar avro-tools-1.11.0.jar tojson snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro > manifest_list.json将该文件转换成 json 格式,查看其内容:
({
"manifest_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro",
"manifest_length": 6127,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 4140724156423386841
},
"added_data_files_count": {
"int": 0
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 1
},
"partitions": {
"array": [
{
"contains_null": false,
"contains_nan": {
"boolean": false
},
"lower_bound": {
"bytes": "0J\u0000\u0000"
},
"upper_bound": {
"bytes": "0J\u0000\u0000"
}
}
]
},
"added_rows_count": {
"long": 0
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 1
}
},
{
"manifest_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro",
"manifest_length": 6128,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 6744647507914918603
},
"added_data_files_count": {
"int": 1
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
"partitions": {
"array": [
{
"contains_null": false,
"contains_nan": {
"boolean": false
},
"lower_bound": {
"bytes": "0J\u0000\u0000"
},
"upper_bound": {
"bytes": "0J\u0000\u0000"
}
}
]
},
"added_rows_count": {
"long": 1
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
})
里面包含了两条 json 数据,分别对应了个 Manifest 文件信息,除了 Manifest 文件的路径之外还有一些统计信息。使用java -jar avro-tools-1.11.0.jar tojson f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro > manifest_1.json和java -jar avro-tools-1.11.0.jar tojson ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro > manifest_2.json将两个 Manifest 文件转为 json 格式,观察其内容:
{
"status": 1,
"snapshot_id": {
"long": 6744647507914918603
},
"data_file": {
"file_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/data/udt_day=2021-12-31/00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet",
"file_format": "PARQUET",
"partition": {
"udt_day": {
"int": 18992
}
},
"record_count": 1,
"file_size_in_bytes": 1032,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [
{
"key": 1,
"value": 48
},
{
"key": 2,
"value": 48
},
{
"key": 3,
"value": 51
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000@\\CsÔ\u0005\u0000"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000@\\CsÔ\u0005\u0000"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
}
{
"status": 2,
"snapshot_id": {
"long": 4140724156423386841
},
"data_file": {
"file_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/data/udt_day=2021-12-31/00000-0-88d582ef-605e-4e51-ba98-953ee3dd4c02-00001.parquet",
"file_format": "PARQUET",
"partition": {
"udt_day": {
"int": 18992
}
},
"record_count": 1,
"file_size_in_bytes": 1032,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [
{
"key": 1,
"value": 48
},
{
"key": 2,
"value": 48
},
{
"key": 3,
"value": 51
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000\btëwÔ\u0005\u0000"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000\btëwÔ\u0005\u0000"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
}
可以看到,每个 Manifest 文件中的每一行都对应一个 data 目录下的数据文件,除了记录数据文件的路径之外,还记录了该数据文件对应的文件格式、分区信息、以及尽可能详细地记录了各个字段的统计信息、排序信息等。Manifest 文件中的 status,表示此次操作的类型,1 表示 add,2 表示 delete。
可以发现 Iceberg 中对数据文件的管理是文件级别,分区管理、字段统计也是到文件级别,而不是目录级别,这也是为什么 Iceberg 扫描要比 Hive 快的原因。在扫描计划里,查询谓词会自动转换为分区数据的谓词,并首先应用于过滤数据文件。接下来,使用列级值计数、空计数、下限和上限来消除无法匹配查询谓词的文件,在某些情况下可以提升数十倍效率。
但是由于 Iceberg 用 json 文件存储 Metadata,表的每次更改都会新增一个 Metadata 文件,以保证操作的原子性。历史 Metadata 文件不会删除,所以像流式作业就需要定期清理 Metadata 文件,因为频繁的提交会导致堆积大量的 Metadata。可以通过配置write.metadata.delete-after-commit.enabled和write.metadata.previous-versions-max属性实现自动清理元数据。
5.Iceberg Spark DDL
Iceberg Spark DDL 操作和原生的 Spark SQL 操作区别不大,主要包含create table、replace table、drop table、alter table操作,但是几项比较特殊的:
所有的操作前面都需要拼接catalog_name,如:
select * from hadoop_catalog.test_db.student;
建表时要增加using iceberg子句,如:
create table hadoop_catalog.test_db.student (
id bigint,
name string,
age int,
udt timestamp
)
using iceberg;
指定分区时可以使用隐藏分区函数,如:
create table hadoop_catalog.test_db.student (
id bigint,
name string,
age int,
udt timestamp
)
using iceberg
partitioned by (days(udt)); -- 可以指定多个分区规则,逗号隔开
Iceberg Spark SQL 中支持的隐藏分区转换函数有:
years(ts):按年分区
months(ts):按月分区
days(ts) 或 date(ts):按天分区
hours(ts) 或 date_hour(ts):按小时分区
bucket(N, col):按散列值 mod N 个桶进行分区
truncate(L, col):按固定长度分区。String 类型会按照指定的长度分区,如果是 Integer 或 Long 类型会按照固定步长分区,如:truncate(10, i)会生成 0,10,20,30…
6.Iceberg Spark DQL
如果要使用 Iceberg,强烈建议使用 Spark3 的版本,因为自从 Spark3 开始,Iceberg 支持了一些新特性,其中就包括使用 SQL 查询语句。
使用方式和传统的 Spark SQL 没有区别,可以在spark-sql窗口使用,也可以在代码中通过saprk.sql()的方式使用。
语法和原生的 Spark SQL 基本无异,但是 Iceberg 支持 SQL 中查看表的历史记录、快照、数据文件、元数据文件等信息,使用方式就是在from的表名后面再加上一些其它属性。
6.1 History
查询表的历史记录:
select * from hadoop_catalog.iceberg_db.user_log_iceberg.history;
输出:
+--------------------+-------------------+-------------------+-------------------+
| made_current_at| snapshot_id| parent_id|is_current_ancestor|
+--------------------+-------------------+-------------------+-------------------+
|2022-03-20 14:37:...|6744647507914918603| null| true|
|2022-03-20 18:31:...|8046643380197343006|6744647507914918603| true|
|2022-03-20 18:36:...|4140724156423386841|8046643380197343006| true|
+--------------------+-------------------+-------------------+-------------------+
6.2 Snapshots
查询表的有效快照:
select * from hadoop_catalog.iceberg_db.user_log_iceberg.snapshots;
输出:
+--------------------+-------------------+-------------------+---------+--------------------+--------------------+
| committed_at| snapshot_id| parent_id|operation| manifest_list| summary|
+--------------------+-------------------+-------------------+---------+--------------------+--------------------+
|2022-03-20 14:37:...|6744647507914918603| null| append|/opt/module/spark...|{spark.app.id -> ...|
|2022-03-20 18:31:...|8046643380197343006|6744647507914918603| append|/opt/module/spark...|{spark.app.id -> ...|
|2022-03-20 18:36:...|4140724156423386841|8046643380197343006| delete|/opt/module/spark...|{spark.app.id -> ...|
+--------------------+-------------------+-------------------+---------+--------------------+--------------------+
6.3 Files
查询表的数据文件和每个文件的元数据:
select * from hadoop_catalog.iceberg_db.user_log_iceberg.files;
输出:
+-------+--------------------+-----------+-------+------------+------------+------------------+--------------------+--------------------+--------------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
|content| file_path|file_format|spec_id| partition|record_count|file_size_in_bytes| column_sizes| value_counts| null_value_counts|nan_value_counts| lower_bounds| upper_bounds|key_metadata|split_offsets|equality_ids|sort_order_id|
+-------+--------------------+-----------+-------+------------+------------+------------------+--------------------+--------------------+--------------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
| 0|/opt/module/spark...| PARQUET| 0|{2021-12-31}| 1| 1032|{1 -> 48, 2 -> 48...|{1 -> 1, 2 -> 1, ...|{1 -> 0, 2 -> 0, ...| {}|{1 -> xxxxxxxxxxx...|{1 -> xxxxxxxxxxx...| null| [4]| null| 0|
+-------+--------------------+-----------+-------+------------+------------+------------------+--------------------+--------------------+-------------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
6.4 Manifests
查询表的 metadata 信息:
select * from hadoop_catalog.iceberg_db.user_log_iceberg.manifests;
输出:
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+--------------------+
| path|length|partition_spec_id| added_snapshot_id|added_data_files_count|existing_data_files_count|deleted_data_files_count| partition_summaries|
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+--------------------+
|/opt/module/spark...| 6127| 0|4140724156423386841| 0| 0| 1|[{false, false, 2...|
|/opt/module/spark...| 6128| 0|6744647507914918603| 1| 0| 0|[{false, false, 2...|
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+--------------------+
原文链接:https://www.sqlboy.tech/pages/891603/