kafka安装部署及集群部署,基本使用和应用
下载安装包
https://www.apache.org/dyn/closer.cgi?path=/kafka/1.1.0/kafka_2.11-1.1.0.tgz
安装过程
1.tar -zxvf 解压安装包
kafka目录介绍
-
/bin 操作 kafka 的可执行脚本
-
/config 配置文件
-
/libs 依赖库目录 /logs 日志数据目录
启动/停止 kafka
-
需要先启动 zookeeper,如果没有搭建 zookeeper 环境,可以直接运行 kafka 内嵌的 zookeeper 启动命令: bin/zookeeper-server-start.sh config/zookeeper.properties &
-
进入 kafka 目录,运行 bin/kafka-server-start.sh {-daemon 后台启动} config/server.properties &
-
进入 kafka 目录,运行 bin/kafka-server-stop.sh config/server.properties
安装集群环境
修改 server.properties 配置
-
修改 server.properties. broker.id=0 / 1
-
修改 server.properties 修改成本机 IP
advertised.listeners=PLAINTEXT://192.168.11.153:9092
当 Kafka broker 启动时,它会在 ZK 上注册自己的 IP 和端口号,客户端就通过这个 IP 和端口号来连接
kafka的基本操作
创建 topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 -
-partitions 1 --topic testReplication-factor: 表示该 topic 需要在不同的 broker 中保存几份,这里设置成 1,表示在两个 broker 中保存两份。
Partitions:分区数
查看 topic
./kafka-topics.sh --list --zookeeper localhost:2181
查看 topic 属性
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
消费消息
./kafka-console-consumer.sh –bootstrap-server localhost:9092 --topic test --from-beginning
发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
Kafka JAVA API 的使用
代码地址: https://github.com/madongyu555666/kafka-demo-1.0
配置信息分析
发送端的可选配置信息分析
acks
配置表示 producer 发送消息到 broker 上以后的确认值。有三个可选项
0:表示 producer 不需要等待 broker 的消息确认。这个选项时延最小但同时风险最大(因为当 server 宕机时,数据将会丢失)。
1:表示 producer 只需要获得 kafka 集群中的 leader 节点确认即可,这个选择时延较小同时确保了 leader 节点确认接收成功。
all(-1):需要 ISR 中所有的 Replica 给予接收确认,速度最慢,安全性最高,但是由于 ISR 可能会缩小到仅包含一个 Replica,所以设置参数为 all 并不能一定避免数据丢失
batch.size
生产者发送多个消息到 broker 上的同一个分区时,为了减少网络请求带来的性能开销,通过批量的方式来提交消息,可以通过这个参数来控制批量提交的字节数大小,默认大小是 16384byte,也就是 16kb,意味着当一批消息大小达到指定的 batch.size 的时候会统一发送。
linger.ms
Producer 默认会把两次发送时间间隔内收集到的所有 Requests 进行一次聚合然后再发送,以此提高吞吐量,而 linger.ms 就是为每次发送到 broker 的请求增加一些 delay,以此来聚合更多的 Message 请求。 这个有点想 TCP 里面的Nagle 算法,在 TCP 协议的传输中,为了减少大量小数据包的发送,采用了Nagle 算法,也就是基于小包的等-停协议。
batch.size 和 linger.ms 这两个参数是 kafka 性能优化的关键参数,很多同学会发现 batch.size 和 linger.ms 这两者的作用是一样的,如果两个都配置了,那么怎么工作的呢?实际上,当二者都配置的时候,只要满足其中一个要 求,就会发送请求到 broker 上。
max.request.size
设置请求的数据的最大字节数,为了防止发生较大的数据包影响到吞吐量,默认值为 1MB。
消费端的可选配置分析
group.id
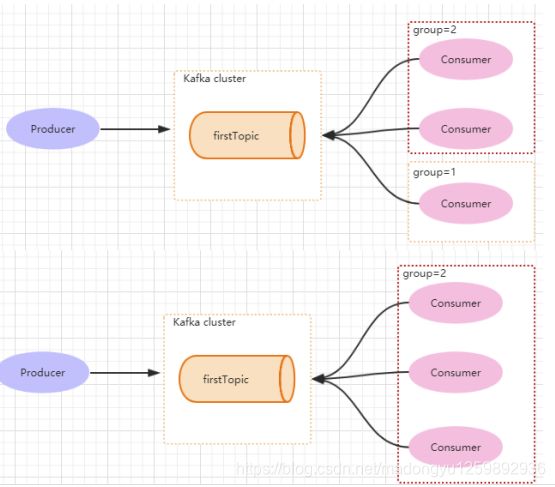
consumer group 是 kafka 提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的 ID,即 group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个 consumer 来消费.如下图所示,分别有三个消费者,属于两个不同的 group,那么对于 firstTopic 这个 topic 来说,这两个组的消费者都能同时消费这个 topic 中的消息,对于此事的架构来说,这个 firstTopic 就类似于 ActiveMQ 中的 topic 概念。如右图所示,如果 3 个消费者都属于同一个group,那么此事 firstTopic 就是一个 Queue 的概念。
enable.auto.commit
消费者消费消息以后自动提交,只有当消息提交以后,该消息才不会被再次接收到,还可以配合 auto.commit.interval.ms 控制自动提交的频率。当然,我们也可以通过 consumer.commitSync()的方式实现手动提交
auto.offset.reset
这个参数是针对新的 groupid 中的消费者而言的,当有新 groupid 的消费者来消费指定的 topic 时,对于该参数的配置,会有不同的语义
auto.offset.reset=latest 情况下,新的消费者将会从其他消费者最后消费的offset 处开始消费 Topic 下的消息
auto.offset.reset= earliest 情况下,新的消费者会从该 topic 最早的消息开始消费
auto.offset.reset=none 情况下,新的消费者加入以后,由于之前不存在offset,则会直接抛出异常。
max.poll.records
此设置限制每次调用 poll 返回的消息数,这样可以更容易的预测每次 poll 间隔要处理的最大值。通过调整此值,可以减少 poll 间隔