tokenizers总结
简介
tokenize的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。
tokenize有三种粒度:word/subword/char
- word词,是最自然的语言单元。对于英文等自然语言来说,存在着天然的分隔符,比如说空格,或者是一些标点符号,对词的切分相对容易。但是对于一些东亚文字包括中文来说,就需要某种分词算法才行。顺便说一下,Tokenizers库中,基于规则切分部分,采用了spaCy和Moses两个库。如果基于词来做词汇表,由于长尾现象的存在,这个词汇表可能会超大。像Transformer XL库就用到了一个26.7万个单词的词汇表。这需要极大的embedding matrix才能存得下。embedding matrix是用于查找取用token的embedding vector的。这对于内存或者显存都是极大的挑战。常规的词汇表,一般大小不超过5万。
- char/字符, 也就是说,我们的词汇表里只有最基本的字符。而一般来讲,字符的数量是少量有限的。这样做的问题是,由于字符数量太小,我们在为每个字符学习嵌入向量的时候,每个向量就容纳了太多的语义在内,学习起来非常困难。
- subword子词级,它介于字符和单词之间。比如说Transformers可能会被分成Transform和ers两个部分。这个方案平衡了词汇量和语义独立性,是相对较优的方案。它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享token压缩空间。

不同tokenizer策略比较
1. word-level
优点:能够保存较为完整的语义信息
缺点:
- 词汇表会非常大,大的词汇表对应模型需要使用很大的embedding层,这既增加了内存,又增加了时间复杂度。通常,transformer模型的词汇量很少会超过50,000,特别是如果仅使用一种语言进行预训练的话,而transformerxl使用了常规的分词方式,词汇表高达267735;
- word-level级别的分词略显粗糙,无法发现更加细节的语义信息,例如模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
- word-level级别的分词对于拼写错误等情况的鲁棒性不好;
- oov问题不好解决
2. char-level
将word-level的分词方法改成 char-level的分词方法,对于英文来说,就是字母界别的,比如 "China"拆分为"C","h","i","n","a",对于中文来说,"中国"拆分为"中","国",
优点:
- 这可以大大降低embedding部分计算的内存和时间复杂度,以英文为例,英文字母总共就26个,中文常用字也就几千个。
- char-level的文本中蕴含了一些word-level的文本所难以描述的模式,因此一方面出现了可以学习到char-level特征的词向量FastText,另一方面在有监督任务中开始通过浅层CNN,HIghwayNet、RNN等网络引入char-level文本的表示;
缺点:
- 但是这样使得任务的难度大大增加了,毕竟使用字符大大扭曲了词的意义,一个字母或者一个单中文字实际上并没有任何语义意义,单纯使用char-level往往伴随着模型性能的下降;
- 增加了输入的计算压力,原本”I love you“是3个embedding进入后面的cnn、rnn之类的网络结构,而进行char-level拆分之后则变成 8个embedding进入后面的cnn或者rnn之类的网络结构,这样计算起来非常慢;
3. subword-level
为了两全其美,transformer使用了混合了char-level和word-level的分词方式,称之为subword-level的分词方式。subword-level的分词方式遵循的原则是:尽量不分解常用词,而是将不常用词分解为常用的子词,
例如,"annoyingly"可能被认为是一个罕见的单词,并且可以分为"annoying"和"ly"。"annoying"并"ly"作为独立的子词会更频繁地出现,同时,"annoyingly"是由"annoying"和"ly"这两个子词的复合含义构成的复杂含义,这在诸如土耳其语之类的凝集性语言中特别有用,在该语言中,可以通过将子词串在一起来形成(几乎)任意长的复杂词。
subword-level的分词方式使模型相对合理的词汇量(不会太多也不会太少),同时能够学习有意义的与上下文无关的表示形式(另外,subword-level的分词方式通过将模型分解成已知的子词,使模型能够处理以前从未见过的词(oov问题得到了很大程度上的缓解)。
subword-level又分为不同的切法,这里就到huggingface的tokenizers的实现部分了,常规的char-level或者word-level的分词用spacy,nltk之类的工具就可以胜任了。
subword-level分词方法
subword的分词往往包含了两个阶段,一个是encode阶段,形成subword的vocabulary dict,一个是decode阶段,将原始的文本通过subword的vocabulary dict 转化为 token的index然后进入embedding层.
- Byte-Pair Encoding (BPE) / Byte-level BPE
- WordPiece
- Unigram
- SentencePiece
1. Byte-Pair Encoding (BPE)
- 首先,它依赖于一种预分词器pretokenizer来完成初步的切分。pretokenizer可以是简单基于空格的,也可以是基于规则的;
分词之后,统计每个词出现的频次供后续计算使用。例如,我们统计到了5个词的词频
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
建立基础词汇表base vocabulary,包括所有的字符,即:
["b", "g", "h", "n", "p", "s", "u"]
- 根据规则,我们分别考察2-gram,3-gram的基本字符组合,把高频的n-gram组合依次加入到词汇表当中,直到词汇表达到预定大小停止。比如,我们计算出ug/un/hug三种组合出现频次分别为20,16和15,加入到词汇表中。同时,如果当前的subword 只会同pair 一起出现,则同时将vocabulary 中对应subword 删除。
1 2 3 4 5 6 7 8 9 10 11 |
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
# count pair
h + u = 10 + 5 = 15
u + g = 10 + 5 + = 20
...
# merge top k
set k = 1
ug -> vocabulary
base vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
loop until vocabulary match vocab_size |
最终词汇表的大小 = 基础字符词汇表大小 + 合并串的数量,比如像GPT,它的词汇表大小 40478 = 478(基础字符) + 40000(merges)。添加完后,我们词汇表变成:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
持续迭代直到达到人工预设的subword词表大小或下一个最高频的字节对出现频率为1
实际使用中,如果遇到未知字符用
也有可能的问题:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果(相对于unigram来说),最终会导致decode的时候面临含糊不清的问题.

2. Byte-level BPE
BPE以词频top-k数量建立的词典;但是针对字符相对杂乱的日文和字符较丰富的中文,往往他们的罕见词难以表示,就中文来说,字符级别就是到单个中文字。
BPE的一个问题是,如果遇到了unicode,基本字符集可能会很大。一种处理方法是我们以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256。通常词表大小包括256 个基本bytes +
例如,像GPT-2的词汇表大小为50257 = 256 +
BBPE整体和BPE的逻辑类似,不同的是,粒度更细致,BPE最多做到字符级别,但是BBPE是做到byte级别

3. WordPiece
BPE中,统计每一个连续字节对的出现频率,选择最高频者合并成新的subword,而wordpiece则使用了概率相除的方法
wordpiece则是从整个句子的层面出发去确认subword的合并结果,假设有个句子是:
"see you next week"初始拆分为字符之后是
"s","e","e"....... "e","k"
则语言模型概率为:

n表示这个句子拆分成字符之后的长度(继续迭代的话就是拆分成subword的长度了),P(ti)表示"ti"这个字符或者subword在词表中占比的概率值,不过我们只需要计算下面的式子就可以:

可以看到,这里和决策树的分裂过层非常类似,两个两个相邻字符或subword之间进行分裂判断分裂增益是否增大,增大则合并。子词结合的互信息的计算过程和决策树是相似但相反的,决策树是越切分越细,而子词的结合则是越结合越粗
从上面的公式,很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。(最大化训练集数据似然的merge)
以es为例子,用es出现的概率,分别除以 e和s的概率,如果这个计算的结果是所有其它的 token pairs中计算结果最大的,则es合并为新token,其它和bpe没什么区别。因为除法可以通过对数运算转化为加减法,所以有上面的这个公式
4. Unigram
Unigram 不再是通过合并base vocabulary 中的subword 来新增,他选择在初始化时初始化一个非常大的subword set(可以用所有字符的组合加上语料中常见的子字符串或BPE生成),通过计算是否需要将一个subword 切分为多个base subword (remove 这个subword)来减小vocabulary size 直到达到vocab size。
这里有一个假设:句子之间是独立的,subword 与 subword 之间是独立的。对应的句子的语言模型似然值就是其subword 的概率的乘积。目标是保存vocab size 的同时语言模型似然值最大。
![]()
整个求解过程是一个简单的EM 或者说一个迭代过程:
- 0. 建立一个足够大的种子subword vocabulary,可以用字典树构建可以是所有字符的组合,也可以用bpe 构建;
- (期望E)统计vocabulary 中每个subword 的频率,计算其对应概率值;
- (最大化M)根据其概率,使用维特比算法返回其语言模型似然值最大化下的最佳分割方案;
- 计算最佳分割方案下每个新子词的loss,这里的loss 是指将当前subword 从vocabulary 中移除时,对应的语言模型似然值,即
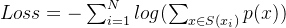
- 丢弃掉loss 前x% 对应的subword;
- 重复2-4阶段,直到vocabulary 达到指定的vocab size。
维特比算法(Viterbi Algorithm):
一种动态规划算法,可以HMM三大问题中的解码问题(给定模型和观测序列,如何找到与此观测序列最匹配的状态序列的问题)进行求解。
该算法包括计算网格图上在时刻t到达各个状态的路径和接收序列之间的相似度,或者说距离。维特比算法考虑的是,去除不可能成为最大似然选择对象的网格图上的路径,即如果有两条路径到达同一个状态,则具有最佳量度的路径被选中,称为幸存路径。

语言模型概率
假设句子S=(t1,t2,...,tn)由n个子词组成,t_i 表示子词,且假设各个子词之间是独立存在的,则句子 S 的语言模型似然值(语言模型概率)等价于所有子词概率的乘积:

假设训练文档中的所有词分别为 x1;x2...xN ,而每个词tokenize的方法是一个集合 S(xi) 。当一个词汇表确定时,每个词tokenize的方法集合 S(xi) 就是确定的,而每种方法对应着一个概率p(x)。如果从词汇表中删除部分词,则某些词的tokenize的种类集合就会变少,log(*)中的求和项就会减少,从而增加整体loss。
Unigram算法每次会从词汇表中挑出使得loss增长最小的10%~20%的词汇来删除。
一般Unigram算法会与SentencePiece算法连用。
5. SentencePiece
SentencePiece 其实并不是一个新的tokenizer 方法,他其实是一个实现了BPE/Unigram tokenizer 的一个集合,不过他有一些创新的地方。
上述方法中有一些问题:
- 都有字,子词或词的概念,然而在很多语言中并没有这样的概念;
- 都默认需要自己进行pre-tokenize,如英语则利用“空格”作为词的分割符,中文则一般选择jieba 进行pre-tokenize,这个过程不同的语言有自己的一套做法,不统一;
- token 格式不统一。以英文为例,表示token 时会有 ##xx, xx/s 这种,表示subword 是否出现在词的首尾,然而中文中是没有这种概念的;
- 解码困难,如BPE解码时需要进行一些标准化,最常见的是去除标点符号。而我们解码后是 [new] [york]两个token,我们并不知道原来的词是 newyork/new york/new-york 中的哪一个.
SentencePiece 的做法:
- 将所有的输入统一转化为unicode字符序列(将token更改为等效的NFKC Unicode), 这意味着不必担心不同的语言,字符或符号,从而将分token的问题和多语言的问题解耦了
- 将空格替换为"_"并且也作为word之一转化为unicode编码(准确的说是utf8编码),。sentecenpiece把标点符号也考虑进来了,比如“,”
References
NLP BERT GPT等模型中 tokenizer 类别说明详解-腾讯云开发者社区-腾讯云
tokenizers小结 - 知乎
tokenizers 总结 | 小蛋子