Vector of Locally and Adaptively Aggregated Descriptors for Image Feature Representation-可解释性的特征表示
Vector of Locally and Adaptively Aggregated Descriptors for Image Feature Representation
Abstract
- 局部聚合描述子向量(VLAD)在图像表示中得到了广泛的应用。然而,VLAD算法寻求描述子与其所属聚类质心之间的残差向量的代数和,这可以降低特征表示的判别能力。为此,本文提出了一种局部自适应聚合描述子向量(VLAAD)框架,自适应地为每个残差向量分配权重。首先,我们利用每个残差向量的大小计算权重,并将加权后的VLAD块封装到ResNet中,形成端到端的加权NetVLAD方法。为了进一步增强特征的判别能力,我们随后用门控方案取代基于 magnitude-based 的权重计算,实现权重的自动估计。增强版本命名为Gated NetVLAD方法。在CIFAR-10、MNIST Digits、Pittsburgh Google街景和ImageNet-Dog数据集上的实验结果表明,与几种最先进的方法相比,使用VLAAD可以提高分类精度和检索mAP。
- 发表在Pattern Recognition期刊上。该论文提出了一种名为VLAAD(Vector of Locally and Adaptively Aggregated Descriptors)的框架,用于改进图像特征表示的判别能力。传统的图像特征表示方法包括PCA和LDA等浅层特征提取方法,以及SIFT、HoG和LBP等手工设计的特征描述符。然而,这些方法可能无法发现数据的深层语义信息。近年来,深度学习技术的兴起为深层特征提取带来了新的可能性,如使用ResNet和VGGNet等卷积网络进行图像特征提取。
- 本文主要关注的是一种名为VLAD(Vector of Locally Aggregated Descriptors)的图像表示方法。虽然VLAD方法在图像表示中被广泛采用,但其判别能力受到其计算方式的限制。为了提高特征表示的判别能力,本文提出了VLAAD框架,通过自适应地为每个残差向量分配权重,扩大残差和的变化性。该框架包括两种实现方式:一种是基于残差向量的幅度计算权重,将加权的VLAD块插入到ResNet中,称为Weighted NetVLAD;另一种是使用门控机制自动估计每个残差向量的权重,将门控的VLAD块插入到ResNet中,称为Gated NetVLAD。提出了一种改进的图像特征表示方法VLAAD,通过自适应地分配权重来增强特征表示的判别能力。该方法在多个数据集上的实验结果证明了其有效性。这项研究对于图像检索和分类任务具有重要意义,并对深度学习领域的特征提取方法做出了有益的探索。
- 论文地址:Vector of Locally and Adaptively Aggregated Descriptors for Image Feature Representation - ScienceDirect
Introduction
-
特征表示是将数据转化为反映数据本质特征的定量表示。通常,特征表示对数据的判别性或结构性信息进行编码,从而实现下游的机器学习任务,如图像检索和图像识别。因此,特征表示在机器学习任务的整个流程中是不可或缺的一步。
-
最经典的一组特征提取方法是降维。PCA(主成分分析)和LDA(线性判别分析)是经典的线性降维方法,流形学习算法是非线性降维方法,它利用局部邻域数据点之间的分段线性相互关系,将数据的非线性拓扑嵌入到低维特征中。这些方法是肤浅的特征提取方法,这意味着它们可能无法发现数据的深层语义。
-
过去十年见证了深度学习技术的蓬勃发展,这种技术将神经网络应用于深度特征提取。不同的数据模式需要不同类型的网络。对于图像,我们通常使用卷积网络,如ResNet和VGGNet。对于视频,我们经常使用3D卷积。LSTM (Long - Short - Time Memory)网络和text CNN更适合文本。神经网络的瓶颈问题之一是它们基本上是不可解释的。我们不知道输出特征的确切物理含义,也没有明确的原则来设计一个没有跟踪和错误过程的良好网络。
-
与深度学习获得的特征相比,手工制作的特征描述符被刻意设计来反映局部图像区域的外观差异。图像表示中常用的描述因子有SIFT、HoG和LBP。这些手工制作的特征描述符是自解释的,它们在计算机视觉和机器学习领域仍然发挥着重要作用。局部特征描述符的典型应用是构建全局图像特征表示,如BoW (Bag- of- words)、VLAD (Vector of local Aggregated descriptors)和fisher Vector。在这些方法中,VLAD在计算效率和表示能力之间取得了很好的平衡,并被构建在深度神经网络中,实现了深层次的特征表示。
-
然而,VLAD的一个容易被忽视的弱点是,它的判别能力被它的计算方式所削弱。为了计算VLAD特征表示,我们需要对所有图像的局部特征描述子进行聚类,并计算特征描述子与其所属聚类质心之间的残差向量的代数和。从代数和的角度来看,在给定两幅图像的情况下,即使每幅图像的残差向量的大小和方向不同,其代数和也很可能是相同的。为此,我们提出了一个VLAAD (Vector of local and adaptive Aggregated Descriptors)框架,自适应地为每个残差向量分配权重,从而扩大残差和的多样性。该框架的实现有两个方面。首先,我们提出基于残差向量的大小来计算权重,并通过在ResNet中插入一个加权的VLAD块来实现该加权方案。我们将该方法命名为加权NetVLAD,随后通过将加权VLAD块替换为采用门控方案的门控VLAD块来增强该方法,该门控VLAD块采用门控方案来自动估计每个残差向量的权重。这个方法被命名为门控NetVLAD。值得强调的是我们方法的几个方面:
-
我们最初提出了一个VLAAD框架,该框架自适应地为每个残差向量分配一个权值,以扩大和的变化,从而增强特征表示的判别能力。
-
我们分别通过手工和自动权重计算实现了VLAD框架,并将权重方案封装到分别插入ResNet的加权VLAD和门控VLAD块中,形成加权NetVLAD和门控NetVLAD。
-
我们在CIFAR-10、MNIST Digits、Pittsburgh Google街景和ImageNet-Dog数据集上进行了一组实验,图像分类和检索的结果证明了该方法相对于现有模型的优越性。
-
Related Works
Shallow Feature Extraction
-
传统的特征提取方法遵循的是一层管道,因此我们将其归纳为浅层方法。早期的方法是计算线性变换矩阵,将数据转换为低维表示。PCA利用数据协方差矩阵的特征向量构造矩阵,使得特征表示具有较大的变异。LDA的目标是最小化类内距离,同时最大化特征表示之间的类间距离。
-
非线性降维方法可以了解隐藏在高维观测值背后的数据的内在结构。由于内在结构可以用一个低维流形来表示,这些方法被称为流形学习。例如,LLE表明,低维man- fold保留了数据点之间的线性依赖关系。特征空间中的数据点可以由其具有与原始数据点重构相同权重的相邻数据点进行线性重构。另一种代表性的流形方法是LTSA (Local tan- agent space alignment)。
-
浅层特征提取在图像检索中起着非常重要的作用。近年来,多采用线性方法作为对深层特征进行降维的后处理工具。在[ Image classification base on PCA of multi-view deep representation]中,PCA被用于降低从RGB和深度图像中学习到的深层多模态特征的维数。相比之下,基于流形的方法发现了数据的内在拓扑结构,因此可以提取更适合信息检索的特征。Pedronette等人通过建立在描述数据之间更有效的相似关系的超图上的流形排序方法进行了多媒体内容检索。
Deep-level Feature Extraction
-
虽然浅层方法过去是成功的,但它们可能无法胜任从大量数据中提取特征。深层特征提取方法可以很好地解决这一问题。在这些方法中,cnn(卷积神经网络)是最受欢迎的一种。cnn最初被提出用于图像特征提取,常见的cnn有AlexNet、ResNet和VGGNet。由于cnn的性能,它被扩展到适应具有上下文依赖的时间数据,如视频和文本,这些数据通常由LSTM (Long - Short - Time memory)处理。Three-stream CNN 利用特征图、光流和全局累积运动特征来实现动作识别。3D卷积网络利用三维卷积核从视频中提取时间特征映射用于视频分类。[Improving text classification with weighted word embeddings via a multi-channel TextCNN model]使用不同大小的一维卷积核对词向量进行卷积以提取文本表示。
-
卷积核的接受域被限制在一个很小的区域,这意味着CNN可能无法发现数据的结构特征。为了捕捉这种关系,注意机制经常被嵌入到cnn中。将通道关注与图卷积神经网络相结合,学习不同通道对动作识别的贡献。
-
将深度神经网络与注意机制相结合用于图像检索已有大量研究。Wei等提出了一种双流方法,其中主流侧重于提取判别性的视觉特征,辅助流旨在将特征提取重定向到通过注意机制估计的显著图像内容。Yang等采用关注机制自适应地设计查询与候选图像之间的匹配阈值,实现了动态匹配核。注意机制在深度特征提取和图像检索中的应用仍处于研究阶段,值得关注。
Handcrafted Feature Extraction
-
尽管深度学习方法具有良好的性能,但它们无法理清中间特征表示,这可能会阻碍深度神经网络的进一步发展。相比之下,手工方法不仅目标明确,而且服从明确的计算程序,因此具有可解释性。
-
手工方法的核心是设计反映局部图像区域外观差异的局部特征描述符。SIFT方法对当前特征位置周围的16个局部patch分别计算一个8向梯度直方图,从而得到该位置的128维特征描述符。由于SIFT特征的高维性,使得SIFT特征匹配的计算量非常大。将几何信息纳入哈希函数的构造中,用于快速SIFT特征匹配。HoG描述符是一个类似于图像单元的梯度直方图。将多个单元的描述符连接起来形成图像块的特征,图像的特征表示是重叠的图像块在特征级的连接。HoG描述符还具有较高的特征维数。将HoG描述符输入到自编码器中,并对自编码器的中层特征进行空间金字塔池化,实现有效的场景分类。LBP描述符将每个像素与其周围像素进行比较,并用二进制数量化它们之间的关系,形成一个维数等于周围像素数的特征向量。进一步扩展LBP生成基于四个梯度描述子的梯度LBP,并训练映射模型获得低维特征,提高了纹理分类的性能。
-
局部特征描述符通常用于构造全局图像特征表示,以反映这些局部特征描述符的统计特征分布。为此,应首先将局部描述子聚类成若干组。经典的BoW特征用直方图表示,直方图中的每个 bin 计算属于特定组的描述符的数量。汉明嵌入将特征描述子线性变换为低维向量,并利用属于同一组的所有向量为每维求一个中值。这些中值随后用于将局部描述符转换为二进制向量。VLAD将每一组的质心和属于该组的局部描述符之间的残差向量进行聚合,然后将每一组的和进行串接,形成特征表示。Fisher vector将高斯混合模型拟合到局部描述符上,计算似然函数对模型参数的偏导数,然后将这些导数串联起来,得到特征表示。
-
手工特征提取在图像检索中非常流行。提出了一种分层BoW模型来计算每个特征的排名,以提高检索性能。NetVLAD从特征图中分离局部描述符,并在网络优化过程中估计聚类质心和残差向量的分布。
Vector of Locally and Adaptively Aggregated Descriptors
Motivation
-
BoW方法将局部描述符分组到多个簇中,对每个簇中的描述符个数进行计数,形成特征直方图,每个bin代表一个簇的描述符个数。计算方案如图 (a)所示。
-

-
BoW特征向量、fisher特征向量和VLAD特征向量的计算方案。(a) BoW特征向量(b) fisher特征向量© VLAD特征向量
-
-
BoW只记录了描述符的一阶分布统计量,因此是次优的。Fisher向量法首先从数据中估计高斯混合模型,然后计算似然函数对每个高斯模型的参数(权值、均值和方差)的偏导数。图像的fisher向量表示是通过对这些偏导数进行归一化和矢量化来建立的。设X为样本数据, λ = w i , μ i , σ i , ( i = 1 , … K ) λ = {w_i, μ_i, σ_i}, (i = 1,…K) λ=wi,μi,σi,(i=1,…K) 为每个高斯模型的参数,则每个高斯模型对应的fisher向量的项可表示为:
-
[ f w i − 1 2 ∂ L ( X ∣ λ ) ∂ w i , f μ i d − 1 2 ∂ L ( X ∣ λ ) ∂ μ i d , f δ i d − 1 2 ∂ L ( X ∣ λ ) ∂ δ i d , ] [f^{-\frac12}_{w_i}\frac{\partial L(X|\lambda)}{\partial w_i}, f^{-\frac12}_{\mu_i^d}\frac{\partial L(X|\lambda)}{\partial \mu_i^d}, f^{-\frac12}_{\delta_i^d}\frac{\partial L(X|\lambda)}{\partial \delta_i^d},] [fwi−21∂wi∂L(X∣λ),fμid−21∂μid∂L(X∣λ),fδid−21∂δid∂L(X∣λ),]
-
式中,L (X| λ)为似然函数,d为维数, f w i − 1 2 , f μ i d − 1 2 和 f δ i d − 1 2 f^{-\frac12}_{w_i}, f^{-\frac12}_{\mu_i^d}和f^{-\frac12}_{\delta_i^d} fwi−21,fμid−21和fδid−21 为通过高斯参数计算的归一化因子。上公式可知,数据均值和方差的每一个维度都需要计算偏导数,因此fisher向量的维数非常高,降低了后续图像检索或识别的效率。fisher向量的计算方案如图 (b)所示。VLAD方法在BoW的简单性和fisher向量的表示能力之间取得了很好的平衡。VLAD首先将所有图像的局部特征描述子(SIFT)分组成几个簇,然后计算每个簇质心与属于该簇的特定图像的描述子之间的残差向量的代数和。图像表示形式为所有聚类质心的残差和的串联。假设 c i , ( i = 1 , … ) K ) c_i, (i = 1,…)K) ci,(i=1,…)K) 为其中一个聚类,¯x ci为质心,则每个聚类对应的VLAD特征向量的条目可以表示为:
-
∑ x i ∈ c i ( x i − x ˉ c i ) \sum_{x_i\in c_i}(x_i-\bar x_{c_i}) xi∈ci∑(xi−xˉci)
-
VLAD的计算方案如图 ©所示。在多个基准数据集上,VLAD特征向量的图像检索性能优于BoW和fisher向量。
-
-
然而,VLAD也有它的弱点。一个明显的问题是,两幅图像相对于同一聚类质心的残差向量在方向和大小上的分布可能不同,但残差向量的代数和仍然是相同的,这可以通过下图来解释。
-

-
在VLAD计算中,残差矢量相对于质心的分布有两种明显的情况。
-
-
在图 (a)的上半部分中,图像的两个局部描述子围绕着残差矢量的大小分别为4d和1d的质心矢量在相反方向上定位,两个残差矢量的代数和为一个大小为3d的矢量。图 (a)的下半部分为另一图像的两个局部描述子,位于质心矢量的同一侧,残差矢量的代数和与上图中获得的3d量级的代数和相同。图 (b)中描述了另一种情况,上下图显示了两幅图像的局部描述符,它们相对于质心在方向上以相同的度间隔分布,但大小不同。在上图中,三个残差向量的大小为2d,且以120度的间隔分布,因此代数和等于零向量。在下图中,每个残差向量的大小为d,但代数和也是一个零向量。
-
上图展示了两种具有较少判别特征的情况,为了简单起见,我们将局部描述子渲染为2D向量。然而,我们相信类似的问题可能发生在其他特征空间。鉴于这种情况,迫切需要扩大代数和向量的变化量,使和既能描述全局又能描述局部描述子分布的细粒度结构信息。
Weighted VLAD
-
我们希望不同的图像对于相同的聚类质心具有不同的残差和,从而使特征表示能够进行细粒度的区分。因此,我们可能需要夸大每个残差向量的个性化特征,以确保每个质心的残差和具有较大的差异性。为此,一种可能的解决方案是在VLAD表示的计算过程中为每个残差向量分配一个权重系数,并且权重只依赖于残差向量本身。权重可以用多种方法计算。在本文中,我们建议使用每个残差向量的大小作为赋予它的权值:
-
∑ j = 1 N i m i j ( x i j − x ˉ c i ) m i j = n o r m ( x i j − x ˉ c i ) \sum^{N_i}_{j=1}m^j_i(x^j_i-\bar x_{c_i})\\ m^j_i=norm(x^j_i-\bar x_{c_i}) j=1∑Nimij(xij−xˉci)mij=norm(xij−xˉci)
-
其中, x i j x^j_i xij 是一个被分组到簇 c i c_i ci 中的残差向量, N i N_i Ni 是关于 c i c_i ci 的残差向量的个数, m i j m^j_i mij 表示分配给 x i j − x ˉ c i x^j_i -\bar x_{c_i} xij−xˉci 的权重。
-
-
这种加权方案简单而有效。在上图 (a)所描述的情况下,从两个图像计算的残差和是完全相同的。这可以用以下方式描述:
-
v 1 + v 2 = − d ⋅ e + 4 d ⋅ e = 3 d ⋅ e , v 1 + v 2 = 2 d ⋅ e + d ⋅ e = 3 d ⋅ e , v_1+v_2=-d·e+4d·e=3d·e,\\ v_1+v_2=2d·e+d·e=3d·e,\\ v1+v2=−d⋅e+4d⋅e=3d⋅e,v1+v2=2d⋅e+d⋅e=3d⋅e,
-
其中v1和v2是通过描述符1和描述符2计算得到的残差向量,e是与图 (a)中描述符2方向相同的单位向量。对每个残差向量赋权后,残差和计算为:
-
v 1 + v 2 = d ⋅ − d ⋅ e + 4 d ⋅ 4 d ⋅ e = 15 d 2 ⋅ e , v 1 + v 2 = 2 d ⋅ 2 d ⋅ e + d ⋅ d ⋅ e = 5 d 2 ⋅ e , v_1+v_2=d·-d·e+4d·4d·e=15d^2·e,\\ v_1+v_2=2d·2d·e+d·d·e=5d^2·e,\\ v1+v2=d⋅−d⋅e+4d⋅4d⋅e=15d2⋅e,v1+v2=2d⋅2d⋅e+d⋅d⋅e=5d2⋅e,
-
显然,残差向量的加权和在两幅图像之间是不同的。因此,VLAD描述符可以具有更强的判别能力。
-
The Weighted NetVLAD
-
Arandjelovi´c等人将VLAD与神经网络相结合,用于深度图像特征提取。这是通过在一定的卷积层后插入一个VLAD模块到骨干神经网络中来实现的。假设 X ∈ R C × H × W X∈R ^{C×H×W} X∈RC×H×W 是卷积层的输出,H和W分别代表C个特征映射的高度和宽度。张量X实际上是由H × W C维向量构成的。VLAD模块将每个H × W位置的C维向量作为图像的局部特征描述符,并使用这些局部描述符计算图像的VLAD表示。为了在神经网络中实现描述子的聚类,VLAD模块利用局部描述子对聚类质心的软赋值来代替原VLAD使用的硬赋值。具体来说,VLAD模块从给定的局部描述子中减去K个聚类质心,得到该描述子的K个残差向量,并将K个残差向量中的每一个乘以一个系数。这K个系数的和等于1,这样它们就可以表示当前局部描述符属于每个聚类的概率。设P为概率,P可计算为:
-
P = s o f t m a x ( A p ⊗ X ⊕ b p ) P=softmax(A_p\otimes X\oplus b_p) P=softmax(Ap⊗X⊕bp)
-
其中, A p ∈ R 1 × 1 × C × K A_p∈R^{1 ×1 ×C×K} Ap∈R1×1×C×K 是k1 ×1卷积核, b p b_p bp 是K ×1维偏置向量, ⊗ \otimes ⊗ 代表卷积和 ⊕ \oplus ⊕ 展开一个向量,使它可以加到一个张量上。由于每个残差向量的维数为C,因此VLAD模块生成的图像表示为一个C × K维向量R,其中每个C维片段围绕一个特定的簇心¯x C为:
-
R c i = ∑ h = 1 H ∑ w = 1 W P c i , h , w ( X h , w − x ˉ c i ) R_{c_i}=\sum^H_{h=1}\sum^W_{w=1}P_{c_i,h,w}(X_{h,w}-\bar x_{c_i}) Rci=h=1∑Hw=1∑WPci,h,w(Xh,w−xˉci)
-
其中, X h , w X_{h,w} Xh,w 是位置(h, w)的局部描述符, P c i , h , w P_{c_i,h,w} Pci,h,w 代表-表示X h,w属于簇ci的概率。这个管道被命名为NetVLAD。
-
基于上述讨论,我们可以很容易地将所提出的加权方案锻造到NetVLAD中。我们所需要做的就是在将它们加在一起之前,为每个残差向量分配一个相对于聚类质心的权重。根据上述方法,权值可以简单地表示为残差向量的大小。因此,该方法被命名为加权NetVLAD,根据该方法,特征表示R中关于质心¯x c1的C维片段可以计算为:
-
R c i = ∑ h = 1 H ∑ w = 1 W P c i , h , w ⋅ m c i , h , w ⋅ ( X h , w − x ˉ c i ) m c i , h , w = n o r m ( X h , w − x ˉ c i ) R_{c_i}=\sum^H_{h=1}\sum^W_{w=1}P_{c_i,h,w}·m_{c_i,h,w}·(X_{h,w}- \bar x_{c_i})\\ m_{c_i,h,w}=norm(X_{h,w}-\bar x_{c_i}) Rci=h=1∑Hw=1∑WPci,h,w⋅mci,h,w⋅(Xh,w−xˉci)mci,h,w=norm(Xh,w−xˉci)
-
其中 m c i , h , w m_{c_i,h,w} mci,h,w 赋予的权重为 X h , w − x ˉ c i X_{h,w}-\bar x_{c_i} Xh,w−xˉci
-
-
加权后的NetVLAD可以用下图进行解释,其中虚线框内的操作构成加权后的VLAD块。为简单起见,下图将通道数定义为3,即C = 3。
-

-
加权NetVLAD方法的解释。虚线框内的操作构成加权VLAD块,其中红色圆角矩形表示加权方案。
-
-
加权VLAD块接收维度为C × H × W的特征映射作为输入,生成C × K的图像特征表示。在图A中,p被分割成K个1 × 1维的核,其深度为C,通过上公式计算权值。
The Gated NetVLAD
-
上图显示了两个典型的例子,其中传统的VLAD可以从两个不同的图像中获得相同的残差和。我们认为加权NetVLAD可以解决上图(a)所示的问题。然而,基于幅度的加权方案无法处理上图 (b)所示的问题,其中从图像中提取的残差向量具有相同的幅度并且在方向上分布均匀(具有相同的交角)。为此,需要改进基于幅度的权重方案,从残差向量中发现潜在的语义区分。
-
我们提出用自动权重估计取代 magnitude-based 的权重计算。受多尺度特征提取中典型采用的门控机制的启发,我们认为每个残差向量的权重系数可以用一个门来代替。设v为残差向量,栅极g可按如下方法计算:
-
g = s i g m o i d ( v ⊗ w s + b s ) g=sigmoid(v\otimes w_s+b_s) g=sigmoid(v⊗ws+bs)
-
其中 ⊗ \otimes ⊗ 表示卷积,ws和bs表示共享的一维核和偏置向量。值得注意的是,我们的意图是从每个残差向量中发现潜在的个性化特征。换句话说,我们希望门只依赖于残数向量本身。因此,所有指向同一聚类的残差向量都应由同一核向量进行卷积。这就是我们使用共享卷积核和偏置向量的原因。
-
-
将门控方案代入加权NetVLAD,得到门控NetVLAD方法,可表示为:
-
R c i = ∑ h = 1 H ∑ w = 1 W P c i , h , w ⋅ g c i , h , w ⊙ ( X h , w − x ˉ c i ) g c i , h , w = s i g m o i d ( ( X h , w − x ˉ c i ) ⊗ w c i + b c i ) R_{c_i}=\sum^H_{h=1}\sum^W_{w=1}P_{c_i,h,w}·g_{c_i,h,w}\odot(X_{h,w}-\bar x_{c_i})\\ g_{c_i,h,w}=sigmoid((X_{h,w}-\bar x_{c_i})\otimes w_{c_i}+b_{c_i}) Rci=h=1∑Hw=1∑WPci,h,w⋅gci,h,w⊙(Xh,w−xˉci)gci,h,w=sigmoid((Xh,w−xˉci)⊗wci+bci)
-
其中 R c i R_{c_i} Rci 是图像表示中与ci相关的片段R, g c i , h , w g_{c_i,h,w} gci,h,w是门,wci和bci是共享核和偏置, ⊙ \odot ⊙ 表示逐元素的乘法。
-
-
网络中的门控VLAD块可以通过下图的左面板来解释,其中门控机制在右面板的红色虚线框中指定。为简单起见,我们也将图中的C表示为3。
-

-
门控VLAD块的解释。左侧虚线框内的操作表示门控VLAD,其中在右侧虚线框中指定了门控方案。
-
Experiments
- 我们在CIFAR-10、MNIST Dig- its、匹兹堡谷歌街景数据集和ImageNet上进行了一组实验,以证明VLAAD框架的效果。首先,我们简要介绍了四个数据集的建立,然后描述了实验中使用的评估指标。为了揭示加权VLAD和门控VLAD块的影响,在CIFAR-10和MNIST Dig- its数据集上提供了一组消融实验。随后,我们将加权NetVLAD和门控NetVLAD方法与几种类似的最先进方法进行比较,以显示VLAAD框架的优越性。
Datasets
-
MNIST数字数据集:该数据集包括数字1到数字10的70000张图像,其中60000张图像定义为训练数据,10000张图像定义为测试数据,每个数字涵盖60000张训练图像和10000张测试图像。我们将60,0 0 0图像应用于VLAAD框架的训练,并使用10,0 0 0测试图像对框架进行评估。
-
CIFAR-10数据集:该数据集包括60,0 0 0张彩色图像,分为10个类,每个类有60,0 0张图像。每个类包含50 000个训练图像和10 000个测试图像。我们使用这50 000 000张训练图像来训练VLAAD框架,并使用剩下的10 000 000张图像进行评估。
-
匹兹堡谷歌街景数据集:该数据集包含从谷歌街景下载的52,00,0张图片,尺寸为640 × 480,每张图片都有相应的GPS数据,表示该图片在匹兹堡的特定位置,30,000张图片构成训练集,其余22,000张图片用于测试。将训练集和测试集进一步划分为查询集和样本集。训练集中的查询和样本图像数量分别为20000和10000,测试集中的查询和样本图像数量分别为14000和8000。
-
ImageNet- dog数据集:ImageNet数据集包含大量图像。为了加快训练和评估过程,我们从ImageNet中选择一个子集,即狗数据集进行实验。ImageNet-Dog数据集包含100多个狗的类别,每个类别由1300张图像组成。我们选择10个分类,并使用1300000的图像来训练具有交叉熵损失函数的网络。评估集包含100个类别的5000张图像,每个类别有50张图像。这些数据集的详细配置如下表所示。

Evaluation Metrics
- 实验中采用了两种评价指标:图像检索中的分类精度和平均精度(mAP@K)。分类准确率反映了正确分类的图像占所有测试图像的比例。平均精度(mAP)是在一次检索过程中计算得到的平均精度(APs)的平均值。给定一个查询图像,我们可以从样本集中得到K个相似的图像。我们根据相似度对K个图像进行排序,并将每个真正图像记为tp @ K,其中K(1≤k≤K)表示其秩。对于k的精度计算为 P k = ∣ T P @ t ( 1 ≤ T ≤ k ) ∣ k P_k = \frac{| TP@t(1≤T≤k)|} k Pk=k∣TP@t(1≤T≤k)∣ ,其中|·|表示集合的元素个数。则此检索过程的AP可表示为 $AP@K = \frac{\sum_{k∈Q} P_k}{|Q|} $ 其中Q为排名前k的真正图像集。我们可以对多次检索得到的AP@Ks求平均值,得到mAP@K。
Implementation Details
-
加权NetVLAD和门控NetVLAD使用的骨干神经网络是ResNet-50。门控VLAD块或加权VLAD块以ResNet-50的第五个卷积块产生的特征映射作为图像特征表示的输入和输出。通过反向传播估计的参数包括主干和门控/加权VLAD块中的簇质心和卷积核。
-
对于MNIST Digits数据集和CIFAR-10数据集,第5个卷积块输出的特征映射构成一个大小为64 × 2048 × 1 × 1的张量,其中64表示批大小,2048表示通道号,特征映射的高度和宽度分别缩小为1。在门控/加权VLAD块中,指定聚类质心个数为64,对应每个图像特征表示的大小为64 × 2048。对于匹兹堡谷歌街景数据集,第五个卷积块生成的特征图大小为4 × 2048 × 8 × 8。聚类数也是64,因此每个图像特征表示的大小为64 × 2048,与MNIST Digits和CIFAR-10图像表示的大小相同。对于ImageNet-Dog数据集,第五个卷积块输出的特征图大小为192 × 2048 × 8 × 8。集群号为64。图像表示的维度也是64 × 2048。
-
在门控VLAD块中,共享的一维核是3 × 1 × 1,步幅为1。为了保证门向量与残差向量具有相同的长度,在卷积后采用填充。网络可以通过交叉熵损失或三重熵损失进行训练。MNIST Digits、CIFAR-10和ImageNet-Dog数据集使用交叉熵损失训练,匹兹堡数据集使用三重损失训练。所述三元组损失使用的每个元组包括一个查询图像、一个正图像和10个负图像。对于MNIST Digits和CIFAR-10数据集,训练过程的学习率为0.1。对于匹兹堡谷歌街景数据集,学习率为0.001。对于ImageNet-Dog数据集,学习率为0.01。
Ablation Experiments
-
在CIFAR-10和MNIST数字数据集上进行了消融实验。在实验中,我们使用所有具有交叉熵损失函数的训练数据,分别训练原始NetVLAD方法和带加权NetVLAD (Weighted NetVLAD)和门控NetVLAD (Gated NetVLAD)方案,即VLAAD框架。在图像检索中,为了提高计算效率,我们从每个测试集中随机选择100张查询图像,并将其输入训练好的网络进行特征提取。从每个类中选择10个图像,使查询图像覆盖所有10个类。然后将查询图像的特征与训练图像的特征进行比较,并返回与每个查询特征距离最小的排名前k的训练特征作为检索结果。因此,我们可以根据检索结果计算mAP@K。在图像分类中,我们使用每个数据集的所有测试图像来计算分类精度Acc。
-
从CIFAR-10和MNIST Digits数据集中得到的Acc和mAP@K如下表所示,其中mAP分别用5、10、15、20和25张检索到的图像计算。在下表中,与原来的NetVLAD相比,VLAAD框架产生了更高的Acc和mAP@K。加权NetVLAD具有最高的Acc和mAP@5,分别比NetVLAD高0.42%和2.21%。与此同时,门控NetVLAD的得分最高,从mAP@10到mAP@25,分别比NetVLAD高出3.91%、3%、1%、4.48%。
-

-
CIFAR-10数据集的消融实验结果。
-
-
在下表中,加权NetVLAD的Acc最高,从mAP@5到mAP@25。加权NetVLAD的Acc比NetVLAD高0.28%,加权NetVLAD的mAP@5到mAP@25分别比NetVLAD高7.46%、5.89%、6.64%、7.81%和7.92%。此外,门控NetVLAD在Acc中的性能比NetVLAD高出0.23%,在mAP@5 ~ mAP@25中的性能比NetVLAD分别高出1.11%、0.02%、0.68%、1.05%和0.84%。
-

-
MNIST数字数据集的消融实验结果。
-
-
VLAAD框架优于原始的NetVLAD框架,因为该框架放大了每个残差向量的独特特征,使得每个聚类质心的残差和有很大的变化,从而提高了图像表示的判别能力。值得注意的是,加权NetVLAD在CIFAR-10查询集上通过mAP@25无法得到良好的mAP@10。这是由于基于震级的权重计算的固有弱点。对于含量丰富的图像,一个质心周围的残差向量极有可能具有相同的大小,并且在方向上以均匀的角度间隔位于质心周围,使得残差和为零。这也可能发生在另一个图片。
-
因此,即使我们给每个残差向量增加权重,这也不能改变两个图像的残差和等于零的事实。我们认为,在处理具有复杂场景和前景对象的自然图像时,这个问题很容易(但不一定)发生。幸运的是,门控NetVLAD可以很好地解决这个问题,因为权值是通过门控机制自动估计的,这个权值很有可能以最优的方式强调残差向量的独特性。
-
还请注意,令我们惊讶的是,加权NetVLAD在MNIST数字查询集上比NetVLAD甚至门控NetVLAD产生更好的Acc和mAP@5到mAP@25。加权NetVLAD算法得到的map比NetVLAD算法得到的map有较大的优势。由于MNIST数据集中的图像非常简单,即暗背景配亮数字,因此残差向量非常稀疏,因此往往定位在几个固定的方向上。
-
因此,上图 (b)中描述的现象在计算VLAD表示时不太可能发生。在这种情况下,我们只需要调整残差向量的大小,而不需要改变残差向量的方向,就可以扩大残差和的变化。当我们使用门控机制计算权值时,每个残差向量的方向会发生移位,这可能会给VLAD表示引入不确定性。这可能是门控NetVLAD不如加权NetVLAD的原因。
Comparative Studies
-
在MNIST Digits, CIFAR-10, Pittsburgh Google街景和ImageNet-Dog数据集上,我们将加权和门控NetVLAD与几种现有方法进行了比较研究。
-
比较中涉及的方法包括浅层特征提取器,如PCA和LTSA和深层特征提取器,如深度信念网络(DBN)、深度卷积神经网络(DCNN)、ResNet-50、NetVLAD、带NetVLAD的特征Pyra- mid网络(FPN-NetVLAD)和门控多尺度NetVLAD (GM-NetVLAD)。关于主成分分析的评论可以在参考文献综述部分找到。LTSA是一种经典的非线性降维算法,它通过对齐在每个数据样本上学习到的局部切线空间来保持数据集的局部几何形状。通常,LTSA以批处理的方式计算特征,因此我们首先计算训练图像的特征,然后通过结合在训练集中找到的相邻图像的特征来获得每个查询图像的特征表示。DBN是通过将一系列受限玻尔兹曼机(Restricted Boltzmann Machines, rbm)逐层叠加而成的。典型的RBM是无监督学习方法,但我们通过全连通层将顶层RBM的输出与类标签连接起来,构造了一个有监督的深度神经网络。DCNN利用一组卷积层和池化层来提取图像的深层特征表示。ResNet-50是这几种基于NetVLAD的方法的主干,我们使用ResNet-50作为基准。
-
为了提高NetVLAD的性能,本文还使用了NetVLAD作为基准模型。FPN-NetVLAD将常用的特征金字塔网络与NetVLAD相结合,提取多尺度图像特征。特征金字塔网络利用骨干网络不同层的多个特征映射来构建图像特征金字塔。我们将每个金字塔层的特征链接到一个NetVLAD模块,并将这些NetVLAD表示连接起来,以获得图像的FPN-NetVLAD表示。由于特征金字塔,FPN- NetVLAD赋予了NetVLAD多尺度特征表示能力。为了进一步增强FPN-NetVLAD的这种能力,GM-NetVLAD在金字塔的每一级特征提取过程中插入gate计算块,从而自动控制从骨干特征映射流向金字塔中的特征映射的信息。
Comparison on MNIST Digits dataset
-
遵循MNIST数字数据集消融研究的实验设置,使用所有训练数据训练神经网络,并使用相同的查询集(与消融研究中一样)从基于图像特征的训练集中检索相似的神经网络。然后计算带有K个检索图像的mAP s,以显示方法的性能。同时,我们使用所有的测试图像来计算Accs。
-
NetVLAD、FPN-NetVLAD、GM- NetVLAD、加权NetVLAD和门控NetVLAD的实验结果如下表所示。
-

-
MNIST数字数据集上不同方法mAPs的比较。
-
-
为简单起见,我们重用加权NetVLAD和门控NetVLAD的结果。可以看出,FPN-NetVLAD和GM-NetVLAD明显优于NetVLAD,因为它们具有多尺度的图像感知能力。GM-NetVLAD略优于FPN-NetVLAD,因为GM-NetVLAD的门控机制自动控制骨干特征映射对构造最优特征金字塔的贡献。加权NetVLAD在mAP@5到mAP@15上分别比GM-NetVLAD高出1.63、1.11和0.05%,在mAP@20和mAP@25上与GM-NetVLAD非常接近。我们认为其原因是加权NetVLAD为每个残差向量分配了一个权重(其大小),以扩大残差和的变化,从而提高了特征的判别能力。加权机制对具有简单背景和前景内容的图像特别有效。门控NetVLAD不能产生令人满意的结果,原因已经在关于MNIST数字数据集的消融研究中讨论过。
Comparison on CIFAR-10
-
与消融实验类似,使用CIFAR-10的所有训练图像来训练模型,并从每个图像类别中随机选择一组图像构成查询集。我们使用训练好的模型分别从训练集和查询集中提取特征,并使用查询特征来重新检索训练特征。排名前k的检索结果被用来计算mAP@K。
-
根据第二张表报告的结果,我们认为gate NetVLAD更好地反映了CIFAR-10上VLAAD框架的优越性。除了门控NetVLAD,我们还在CIFAR-10数据集上实现了PCA、LTSA、DBN和DCNN等4种模型。实验结果如下表所示,门控NetVLAD基本上获得了最好的图像检索结果。其中,Gated NetVLAD的mAP@5为56。21%,略低于DCNN的56%。56%),但比第三种方法(DBN)高出6.38%。同时,门控NetVLAD在mAP@10到mAP@25范围内的性能大大优于所有其他方法。门控NetVLAD的mAP@10 ~ mAP@25分别比次优方法(DCNN)高出3.95%、5.21%、9.01%和10.3%。
-
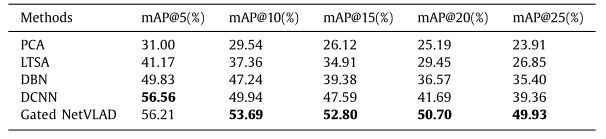
-
CIFAR-10数据集上不同方法mAPs的比较。
-
-
可以预见的是,PCA和LTSA得到的结果比较琐碎,因为它们都是单层的浅学习方法,它们可能无法揭示隐藏在数据中的对分类很重要的深层语义信息。由于能够发现深层特征,DBN的效果比浅层方法好得多,但在图像检索方面不如DCNN。这是由于DCNN中的卷积是专门为提取图像特征表示而设计的。请注意,DCNN方法获得了最高的mAP@5,这证明了它在图像检索中的有效性。门控NetVLAD通过mAP@25获得了比DCNN高得多的mAP@10,因为NetVLAD学习了局部描述符分布的细粒度结构信息,更重要的是,门控方案自适应地为每个残差向量分配了权重,增强了图像表示的判别特性。
Comparison on Pittsburgh Google street view dataset
-
对于匹兹堡谷歌街景数据集,我们使用训练集中的所有样本和查询图像来构建用于训练神经网络的三元组。为了加速测试过程,我们从测试集中随机抽取几千张样本图像和几十张查询图像进行评估。这些图像被输入到训练好的网络中进行特征提取。使用测试查询特征检索测试样本特征,通过检索结果计算mAP@K s。
-
由于ResNet在模式识别方面的良好性能,我们首先将加权门控NetVLAD与ResNet- 50进行了比较。我们还将这两种方法与FPN-NetVLAD和GM- netvlad进行了比较,我们认为FPN-NetVLAD具有多尺度图像感知和特征提取的能力,并通过在GM- NeVLAD中加入门控机制进一步增强了这一能力。五种方法的mAP@5到mAP@25如下表所示。
-
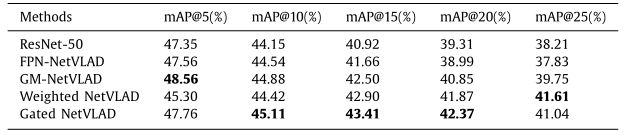
-
在匹兹堡谷歌街景数据集上不同方法生成的地图的比较。
-
-
可以预见的是,基于vlad的ap方法基本上优于ResNet方法,因为它们能够在全局特征空间上描述特征描述符的分布。GM-NetVLAD在所有指标上都优于FPN-NetVLAD (mAP@5至mAP@25),因为它采用了增益机制。请注意,GM-NetVLAD由于其门控多尺度特征表示能力,在所有方法中获得了最好的mAP@5,而门控NetVLAD和FPN-NetVLAD在这个度量上非常接近GM-NetVLAD。vad框架通过mAP@25击败了GM-NetVLAD。
-
具体而言,gate NetVLAD在mAP@10, mAP@15, mAP@20和mAP@25上分别比GM-NetVLAD高出0.23%,0.91%,1.52%和1.29%。加权NetVLAD比mAP@25进一步提高0.57%。VLAAD框架通常优于其他比较方法,因为自适应权值分配机制可以放大每个残差向量的独特特征,从而扩大残差和的多样性,提高图像表示的判别能力。一般来说,门控NetVLAD在该数据集上的性能优于加权NetVLAD。
-
我们认为,这是因为对于前景复杂、背景杂乱的图像,门控NetVLAD所采用的门控机制可以为每个残差向量分配一个自动学习的权值,这使得残差向量比手工制作的权值具有更多的个体特征,残差和具有较大的多样性,提高了特征表示的判别能力。
Comparison on ImageNet-Dog dataset
-
在ImageNet-Dog数据集上测试了NetVLAD、FPN-NetVLAD、GM-NetVLAD、加权NetVLAD和门控NetVLAD。这些网络使用13000张图像进行训练,然后从每个评估类别中选择一张图像作为查询集,并从训练集中检索相关图像。检索是基于神经网络提取的图像特征。下表演示了这些方法的mAP@5到mAP@25。由于多尺度学习或加权/门控机制,其他四种方法在所有指标上都优于NetVLAD。
-

-
不同方法在ImageNet-Dog数据集上mAPs的比较。
-
-
GM-NetVLAD在mAP@10到mAP@25上与FPN-NetVLAD相当或略高于FPN-NetVLAD,这是由于自动控制每个金字塔级别对特征构建的贡献。基于vlad的方法(加权NetVLAD和门控NetVLAD)击败了多尺度方法(FPN-NetVLAD和gmm -NetVLAD),门控NetVLAD在四个指标上取得了最好的结果。具体来说,在mAP@10到mAP@25上,Gated NetVLAD分别比GM-NetVLAD高出1.6%、1.29%、1.88%和2.41%。FPN-NetVLAD是所有方法中性能最好的mAP@5。这可以归因于它的多尺度特征学习能力。
-
与匹兹堡数据集中的街景图像类似,ImageNet中的狗图像也具有丰富的纹理和颜色信息。对于这些图像,在VLAD特征构建中,每个残差的自动权值计算比手工权值计算能发现更多的图像个体特征。我们认为这就是门控NetVLAD在这些图像上比加权NetVLAD表现更好的原因。
Conclusion
-
VLAD是一种有效的图像表示方法,在图像识别和检索中发挥着重要作用。然而,局部描述子与聚类中心之间的残差向量和可能缺乏足够的多样性,这可能会降低不同图像的可区分性。这个弱点仍然存在于VLAD的深度学习版本NetVLAD中。
-
本文提出在每个残差向量相加之前给它们分配一个权值,这个权值可以用残差向量的大小手工生成(加权NetVLAD),也可以用门控机制自动估计(门控NetVLAD)。我们认为权值有助于扩大残差和的多样性,从而提高图像特征的判别能力。这可能是所提出的方法的优点。将所提方法与ResNet、NetVLAD和多尺度NetVLAD (FPN-NetVLAD和GM-NetVLAD)进行比较,发现多尺度NetVLAD虽然提高了特征表示的质量,但其效果不如加权/门控NetVLAD。
-
此外,这两种方法各有优缺点。具体来说,对于内容简单的图像,加权NetVLAD的性能优于门控NetVLAD,而对于内容复杂的图像,门控NetVLAD的性能优于加权NetVLAD。这是因为简单图像的残差矢量可能会在几个固定的方向上分布,仅调整矢量的大小就可以提高特征质量,而复杂图像的残差分布更为不规则,自动选通机制产生的残差和差异较大。门控NetVLAD的另一个缺点是计算效率低,因为我们必须通过一维卷积来计算每个特征的权值。
-
在前人研究的基础上,我们计划从以下几个方面继续研究基于vlad的方法:
-
更有效的图像特征多尺度感知:虽然我们发现多尺度NetVLAD不如加权/门控NetVLAD,但我们认为多尺度NetVLAD仍然值得研究。在FPN-NetVLAD中,通过聚合从不同网络层中选择的骨干特征映射来构建特征金字塔。在此过程中,需要将顶层特征图放大几次,以添加到底层特征图中。由于这种操作,一些细粒度的信息,如前景目标的位置和方向可能是模糊的,这将给特征金字塔带来不确定性。虽然GM-NetVLAD利用门控机制控制信息聚合到低层特征映射,但效果仍不理想。解决好这个问题将有助于实现细粒度图像识别和细粒度图像检索。
-
将高级语义描述整合到VLAD表示中:VLAD表示可以看作是Fisher Vector和Bag of Word表示之间的折衷。VLAD仅记录描述符与相应聚类中心之间的残差向量之和,而不提供图像的颜色和空间布局等语义信息。由于这个原因,两个完全不同的映像可能会共享相似的VLAD表示。虽然加权或加权机制可以增强每个残差向量的个体特征来缓解这个问题,但我们仍然需要更多的基本解决方案。通过基于区域的VLAD特征连接构建分层表示。这项工作对这个问题提供了一些见解。
-
使用VLAD和NetVLAD特性加速任务实现。VLAD和NetVLAD表示通常具有非常高的维度,这意味着使用这些特征进行后续分类或检索可能非常耗时。以往加速计算的方法都是通过PCA进行降维排序,但降维后的特征失去了原有的物理意义。像Hamming嵌入那样生成二进制VLAD或NetVLAD表示是很吸引人的,这样可以大大加快距离计算。为此,必须保证特征生成过程的差异性,使之能够在神经网络中反向传播。
-