一篇文章带你学会Hadoop-3.3.4集群部署

目录
编辑
一、Hadoop集群部署
二、基础设施配置
2.1 设置网络
2.1.1 设置主机名称
2.1.2 设置hosts配置文件
2.1.3 关闭防火墙
2.1.4 关闭selinux
2.1.5 更换语言环境
2.1.6 更换时区
2.1.7 ssh免密
2.1.7.1 生成.ssh文件夹
2.1.7.2 进入文件夹
2.1.7.3 生成密码和私钥
2.1.7.4 免密授权
三、软件安装
3.1 jdk 安装
3.1.1 解压jdk
3.1.2 移动解压目录
3.1.3 配置jdk,设置环境变量
3.1.4 修改系统默认JDK
3.1.4.1 查看系统当前默认配置
3.1.4.2 把自己安装的JDK加入系统备选中
3.1.4.3 将自己的JDK作为java首选
3.1.5 检查环境使用的JDK
3.1.6 分发JDK到其他节点
3.1.6.1 分发JDK
3.1.6.2 分发环境变量文件
3.1.7 分发环境生效
3.2 安装zookeeper 集群
3.2.1 解压
3.2.2 移动解压目录
3.2.3 配置zookeeper
3.2.3.1 拷贝生成zoo.cfg
3.2.3.2 建立zookeeper 目录
3.2.3.3 修改zoo.cfg文件
3.2.3.4 创建myid文件
3.2.3.5 设置环境变量
3.2.3.6 分发zookeeper
3.2.3.7 分发环境变量文件
3.2.3.8 生效环境
3.2.3.9 启动zookeeper
3.3 安装hadoop
3.3.1 解压hadoop
3.3.2 移动解压目录
3.3.3 配置hadoop
3.3.3.1 设置Hadoop JAVA_HOME
3.3.3.2 设置YARN JAVA_HOME
3.3.3.3 设置core-site.xml文件
3.3.3.4 设置hdfs-site.xml 文件
3.3.3.5 设置mapred-site.xml 文件
3.3.3.6 设置yarn-site.xml文件
3.3.3.7 修改workers文件
3.3.3.8 修改 start-dfs.sh 和stop-dfs.sh 文件
3.3.3.9 修改start-yarn.sh和stop-yarn.sh文件
3.3.4 分发复制到其他节点
3.4.4.1 分发Hadoop文件
3.4.4.2 分发/etc/profile 文件
3.4.5 启动hadoop集群
3.4.5.1 初始化namenode
3.4.5.2 初始化zk中的ha状态
3.4.5.3 启动整个集群
3.3.5 集群验证及简单使用
3.3.5.1 查看yarn 集群状态
3.3.5.2 查看namenode集群状态
3.3.5.3 访问hdfs 集群页面
3.3.5.4 访问yarn 集群页面
3.3.5.5 简单使用
3.3.5.5.1 创建bigdata 目录
3.3.5.5.2 创建 /user/root目录
一、Hadoop集群部署
系统环境描述:本教程基于CentOS 8.0版本虚拟机
机器节点信息:

软件版本:
jdk-8u211-linux-x64.tar.gz
apache-zookeeper-3.8.2-bin.tar.gz
hadoop-3.3.4.tar.gz
提示:如果想入门hadoop,特别是集群部署,hadoop涉及的角色还是比较多的,建议先从总体架构抓起,先熟悉总体架构,再熟悉HA部署模式的相关理论和知识,然后再跟着部署的过程中就会有豁然开朗的感觉,印象也会比较深刻,推荐先看下我前面的hadoop系列的理论文章YARN框架和其工作原理流程介绍_夜夜流光相皎洁_小宁的博客-CSDN博客、HDFS介绍_夜夜流光相皎洁_小宁的博客-CSDN博客、MapReduce介绍_夜夜流光相皎洁_小宁的博客-CSDN博客
二、基础设施配置
2.1 设置网络
2.1.1 设置主机名称
分别登录进入 192.168.31.215、192.168.31.8、192.168.31.9、192.168.31.167、192.168.31.154等节点服务器,执行命令:
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
hostnamectl set-hostname node4
2.1.2 设置hosts配置文件
vi /etc/hosts
192.168.31.215 master
192.168.31.8 node1
192.168.31.9 node2
192.168.31.167 node3
192.168.31.154 node4
2.1.3 关闭防火墙
systemctl stop firewalld
systemctl stop iptables
#永久关闭防火墙
systemctl disable firewalld
2.1.4 关闭selinux
#临时关闭
setenforce 0
#永久关闭
vim /etc/selinux/config 然后设置 SELINUX=disabled
2.1.5 更换语言环境
dnf install glibc-langpack-zh.x86_64
echo LANG=zh_CN.UTF-8 > /etc/locale.conf
source /etc/locale.conf
2.1.6 更换时区
timedatectl list-timezones
timedatectl set-timezone Asia/Shanghai
timedatectl
2.1.7 ssh免密
2.1.7.1 生成.ssh文件夹
ssh localhost
2.1.7.2 进入文件夹
cd /root/.ssh/
2.1.7.3 生成密码和私钥
ssh-keygen -t rsa
一路按回车键就行
2.1.7.4 免密授权
ssh-copy-id root@master
说明:在本环境中,我们需要将master的密钥,发送给其他node1、node2、node3、node4节点,其中,
master和node1要相互免密,原因是:1)启动start-dfs.sh脚本的机器需要将公钥分发给别的节点
2)在HA模式下,每一个NN身边会启动ZKFC,ZKFC会用免密的方式控制自己和其他NN节点的NN状态
三、软件安装
3.1 jdk 安装
3.1.1 解压jdk
tar -zxvf jdk-8u211-linux-x64.tar.gz
3.1.2 移动解压目录
mv jdk1.8.0_211/ /usr/local/
3.1.3 配置jdk,设置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_211
export PATH=$PATH:${JAVA_HOME}/bin
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
3.1.4 修改系统默认JDK
因为我安装的CentOS 8.0 操作系统,默认安装了自带的open jdk,显然不满足我们的需要,我又不想卸载open jdk,所以才选择使用update-alternatives来管理JDK,如果你们的环境没有多版本jdk 管理需求,可忽略本步骤。
3.1.4.1 查看系统当前默认配置
输入命令:update-alternatives --display java
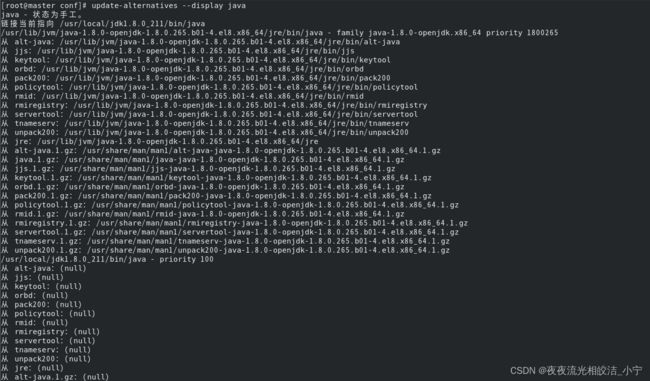
3.1.4.2 把自己安装的JDK加入系统备选中
update-alternatives --install /usr/bin/java java /usr/local/jdk1.8.0_211/bin/java 1800265
-- 提示: 1800265为执行update-alternatives --display java 后看到的系统默认jdk的权限编号
3.1.4.3 将自己的JDK作为java首选
update-alternatives --config java

然后输入+2 回车。
3.1.5 检查环境使用的JDK
java -version
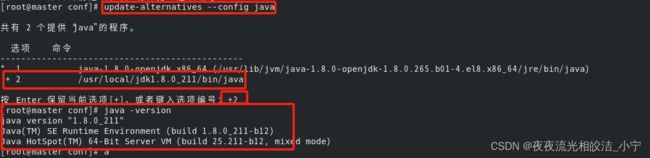
成功配置了我们自己安装的java版本
3.1.6 分发JDK到其他节点
3.1.6.1 分发JDK
scp -r /usr/local/jdk1.8.0_211/ root@node1:/usr/local/
scp -r /usr/local/jdk1.8.0_211/ root@node2:/usr/local/
scp -r /usr/local/jdk1.8.0_211/ root@node3:/usr/local/
scp -r /usr/local/jdk1.8.0_211/ root@node4:/usr/local/
3.1.6.2 分发环境变量文件
scp /etc/profile root@node1:/etc/profile
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
scp /etc/profile root@node4:/etc/profile
3.1.7 分发环境生效
node1、node2、node3、node4虚拟机上执行 source /etc/profile 使环境生效
提示:如果虚拟机默认了JDK,需要执行3.1.4小节的命令,切换系统默认JDK为你自己安装的JDK
3.2 安装zookeeper 集群
3.2.1 解压
tar -zxvf apache-zookeeper-3.8.2-bin.tar.gz
3.2.2 移动解压目录
mv apache-zookeeper-3.8.2-bin /usr/local/
3.2.3 配置zookeeper
3.2.3.1 拷贝生成zoo.cfg
cd /usr/local/apache-zookeeper-3.8.2-bin/conf
cp zoo_sample.cfg zoo.cfg
3.2.3.2 建立zookeeper 目录
cd /usr/local/apache-zookeeper-3.8.2-bin/
mkdir zkdata
mkdir logs
3.2.3.3 修改zoo.cfg文件
vim zoo.cfg
--zoo.cfg 添加内容:
dataDir=/usr/local/apache-zookeeper-3.8.2-bin/zkdata
dataLogDir=/usr/local/apache-zookeeper-3.8.2-bin/logs
server.1=node2:2888:3888
server.2=node3:2888:3888
server.3=node4:2888:3888
3.2.3.4 创建myid文件
node2、node3、node4虚拟机,分别在/usr/local/apache-zookeeper-3.8.2-bin/zkdata目录下创建myid
echo 1 > myid //node2
echo 2 > myid //node3
echo 3 > myid //node4
3.2.3.5 设置环境变量
vim /etc/profile
export ZK_HOME=/usr/local/apache-zookeeper-3.8.2-bin
export PATH=$PATH:$ZK_HOME/bin
3.2.3.6 分发zookeeper
scp -r /usr/local/apache-zookeeper-3.8.2-bin/ root@node3:/usr/local/
scp -r /usr/local/apache-zookeeper-3.8.2-bin/ root@node4:/usr/local/
3.2.3.7 分发环境变量文件
scp /etc/profile root@node3:/etc/profile
scp /etc/profile root@node4:/etc/profile
3.2.3.8 生效环境
注意三台虚拟机分贝执行source /etc/profile 使环境生效
3.2.3.9 启动zookeeper
分别在node2、node3、node4节点启动zookeeper 服务
命令:zkServer.sh start

通过ps -ef|grep zookeeper 指令,我们查看到我们的zookeeper已经启动成功。
3.3 安装hadoop
3.3.1 解压hadoop
tar -zxvf hadoop-3.3.4.tar.gz
3.3.2 移动解压目录
mv hadoop-3.3.4/ /usr/local/
3.3.3 配置hadoop
3.3.3.1 设置Hadoop JAVA_HOME
cd /usr/local/hadoop-3.3.4/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_211
3.3.3.2 设置YARN JAVA_HOME
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_211
3.3.3.3 设置core-site.xml文件
vim core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/usr/local/hadoop-3.3.4/tmp
ha.zookeeper.quorum
node2:2181,node3:2181,node4:2181
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
3.3.3.4 设置hdfs-site.xml 文件
vim hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
/usr/local/hadoop-3.3.4/ha/dfs/name
dfs.datanode.data.dir
/usr/local/hadoop-3.3.4/ha/dfs/data
dfs.namenode.checkpoint.dir
/usr/local/hadoop-3.3.4/ha/dfs/secondary
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
master:9000
dfs.namenode.http-address.mycluster.nn1
master:50070
dfs.namenode.rpc-address.mycluster.nn2
node1:9000
dfs.namenode.http-address.mycluster.nn2
node1:50070
dfs.namenode.heartbeat.recheck-interval
50000
dfs.heartbeat.interval
3
dfs.namenode.shared.edits.dir
qjournal://master:8485;node1:8485;node3:8485/mycluster
dfs.journalnode.edits.dir
/usr/local/hadoop-3.3.4/ha/dfs/jn
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.ha.automatic-failover.enabled
true
dfs.webhdfs.enabled
true
3.3.3.5 设置mapred-site.xml 文件
vim mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4
mapreduce.map.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
mapreduce.map.java.opts
-Xmx1024m
mapreduce.reduce.java.opts
-Xmx1024m
3.3.3.6 设置yarn-site.xml文件
vim yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.zk-address
node2:2181,node3:2181,node4:2181
yarn.resourcemanager.cluster-id
ningzhaosheng
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node3
yarn.resourcemanager.webapp.address.rm1
node3:8088
yarn.resourcemanager.address.rm1
node3:8032
yarn.resourcemanager.hostname.rm2
node4
yarn.resourcemanager.webapp.address.rm2
node4:8088
yarn.resourcemanager.address.rm2
node4:8032
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
4096
3.3.3.7 修改workers文件
vim workers
#添加hostname
master
node1
node2
node3
node4
3.3.3.8 修改 start-dfs.sh 和stop-dfs.sh 文件
start-dfs.sh、stop-dfs.sh文件头部加入:
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.3.3.9 修改start-yarn.sh和stop-yarn.sh文件
start-yarn.sh、stop-yarn.sh文件头部加入:
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=root
YARN_NODEMANAGER_USER=root
3.3.4 分发复制到其他节点
3.4.4.1 分发Hadoop文件
scp -r /usr/local/hadoop-3.3.4/ root@node1:/usr/local/
scp -r /usr/local/hadoop-3.3.4/ root@node2:/usr/local/
scp -r /usr/local/hadoop-3.3.4/ root@node3:/usr/local/
scp -r /usr/local/hadoop-3.3.4/ root@node4:/usr/local/
3.4.4.2 分发/etc/profile 文件
scp /etc/profile root@node1:/etc/profile
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
scp /etc/profile root@node4:/etc/profile
注意:分发环境配置文件后,记得在各节点执行:source /etc/profile使环境配置生效
3.4.5 启动hadoop集群
3.4.5.1 初始化namenode
hdfs namenode -format
提示:初次启动需要,后续重启服务不再需要
3.4.5.2 初始化zk中的ha状态
hdfs zkfc -formatZK
提示:初次启动需要,后续重启服务不再需要
3.4.5.3 启动整个集群
start-all.sh start
3.3.5 集群验证及简单使用
3.3.5.1 查看yarn 集群状态
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2

查看状态显示,一个active状态,一个standby状态,启动正常。
3.3.5.2 查看namenode集群状态
hdfs haadmin -ns mycluster -getAllServiceState

查看状态显示,一个active状态,一个standby状态,符合预期,启动正常。
3.3.5.3 访问hdfs 集群页面
http://master:50070/


通过页面访问到了hadoop集群页面,且显示我们的节点都在线,启动正常。
3.3.5.4 访问yarn 集群页面
http://node3:8088/cluster
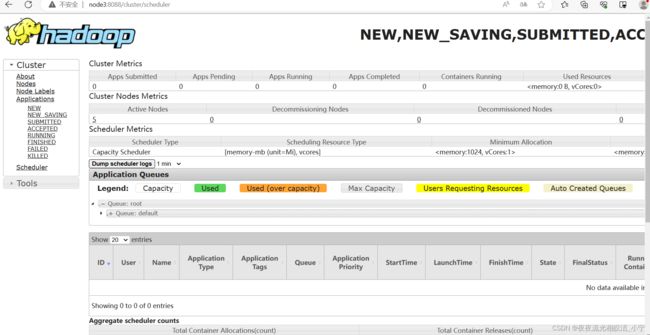
成功访问到了yarn调度集群页面,yarn启动正常。
3.3.5.5 简单使用
3.3.5.5.1 创建bigdata 目录
hdfs dfs -mkdir /bigdata
3.3.5.5.2 创建 /user/root目录
hdfs dfs -mkdir -p /user/root
今天Hadoop3.3.4集群部署的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!