python报错—使用.str.contains()方法替换某一列报错:AttributeError: ‘str‘ object has no attribute ‘str‘及解决方案
项目场景:
1.要求:筛选channel_type_desc列,将"含有实体渠道的"全部替换"实体渠道",将"含有电子渠道的"全部替换成"电子渠道",将"含有直销渠道的"全部替换成"直销渠道",其他替换为"未识别"。
导入数据及查看数据情况
#导入数据
import os
import pandas as pd
import numpy as np
def read_file(filepath):
os.chdir(os.path.dirname(filepath))
return pd.read_csv(os.path.basename(filepath),encoding='utf-8')
file_pos="F:\\python_machine_learing_work\\501_model\\data\\第一次建模用的样本数据\\训练集\\v1_6_feature.csv"
data_pos_1=read_file(file_pos)
#查看channel_type_desc的数据分布
data_pos_1.channel_type_desc.value_counts()

问题描述
2.实现过程
def func(x):
if x.str.contains('实体渠道'):
return "实体渠道"
elif x.str.contains('电子渠道'):
return "电子渠道"
elif x.str.contains('直销渠道'):
return "直销渠道"
else:
return "未识别"
使用apply方法对 “data_pos_1[‘channel_type_desc’]” 调用函数func。
data_pos_1[data_pos_1['channel_type_desc'].apply(func)]
3.发现问题:报错:AttributeError: ‘str’ object has no attribute ‘str’
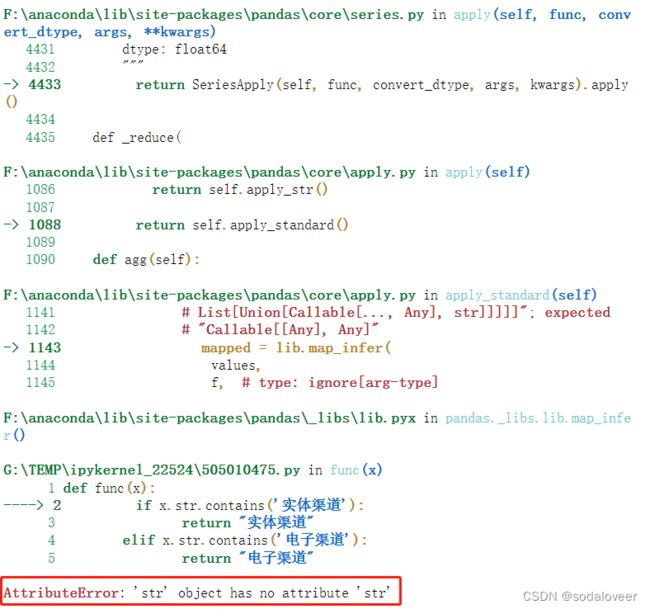
原因分析:
- 原因一:.str.contains()函数只能对Series使用。
- 原因二:Series使用apply方法后,apply会自动遍历整个Series,将Series分解为一个个元素(元素数据类型跟数据列的数据类型一致)传入函数中,按照相对应的函数进行运算,最终将所有的计算结果存储在一个新的Series中返回。
4.具体原因分析:

从上面我们可以看到,“data_pos_1[‘channel_type_desc’]” 数据类型是Series,但是 “data_pos_1[data_pos_1[‘channel_type_desc’].apply(func)]” 等于对Series使用apply方法,实际上是将"data_pos_1[‘channel_type_desc’]"中的元素一个个传入到func函数中,元素类型是
,又因为.str.contains()函数只能对Series使用,因此会报错AttributeError: ‘str’ object has no attribute ‘str’。
原因二举例说明:
1.创建测试DataFrame
import pandas as pd
df = pd.DataFrame({'A': [1, 80, 4],
'B': [9, 80, 5],
'C': ['pink','puple','blue']})
df

2.查看对 Series下使用 apply方法,Series传入函数的数据类型。
print(type(df['C']))
![]()
def test(data):
print(data)
print(type(data))
print('______')
return data
result=df['C'].apply(test)
print('------分隔线------')
print("最终返回一个新的Series")
print(type(result))
print('------分隔线------')
print("将series对象转为Dataframe对象",'\n',result.apply(pd.Series),'\n',type(result.apply(pd.Series)))
运行结果:
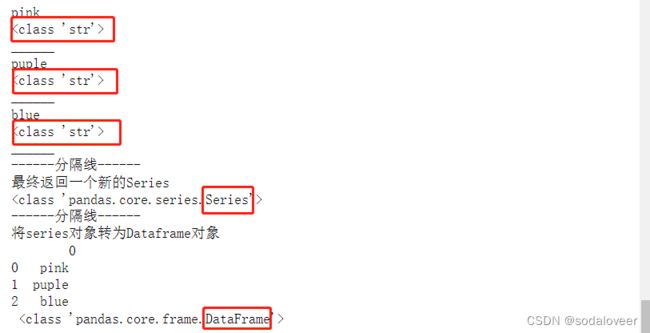
从上面可以看出,apply将df[‘C’]中元素一个个分解开传入函数中,每个元素类型为
解决方案:
方案一: 使用其他方法进行替换,不使用.str.contains()函数。
举例1:使用re.match()函数
import re
def func(data):
if re.match(r'[\u4e00-\u9fa5]*实体渠道*[\u4e00-\u9fa5]',str(data)):
return "实体渠道"
elif re.match(r'[\u4e00-\u9fa5]*电子渠道*[\u4e00-\u9fa5]',str(data)):
return "电子渠道"
elif re.match(r'[\u4e00-\u9fa5]*直销渠道*[\u4e00-\u9fa5]',str(data)):
return "直销渠道"
else:
return "未识别"
data_pos_1['channel_type_desc']=data_pos_1['channel_type_desc'].apply(func)
举例2:使用re.search()函数
import re
def func(x):
if re.search(r'[\u4e00-\u9fa5]*实体渠道*[\u4e00-\u9fa5]',str(x)):
return "实体渠道"
elif re.search(r'[\u4e00-\u9fa5]*电子渠道*[\u4e00-\u9fa5]',str(x)):
return "电子渠道"
elif re.search(r'[\u4e00-\u9fa5]*直销渠道*[\u4e00-\u9fa5]',str(x)):
return "直销渠道"
else:
return "未识别"
data_pos_1['channel_type_desc']=data_pos_1['channel_type_desc'].apply(func)
举例3:使用np.where()函数,这个方法没有加上str.contains()模糊查询来的简洁,不太推荐。
import numpy as np
data_pos_1['channel_type_desc']=np.where((data_pos_1['channel_type_desc']=='社会实体渠道')|(data_pos_1['channel_type_desc']=='自营实体渠道'),'实体渠道',
np.where((data_pos_1['channel_type_desc']=='社会电子渠道')|(data_pos_1['channel_type_desc']=='自营电子渠道'),'电子渠道',
np.where((data_pos_1['channel_type_desc']=='社会直销渠道')|(data_pos_1['channel_type_desc']=='自营直销渠道'),'直销渠道','未识别')))
举例4:使用Series.replace()函数
#第一种写法
def func(x):
result=x.replace(r'[\u4e00-\u9fa5]*实体渠道*[\u4e00-\u9fa5]','实体渠道',regex=True)
result1=result.replace(r'[\u4e00-\u9fa5]*电子渠道*[\u4e00-\u9fa5]','电子渠道',regex=True)
result2=result1.replace(r'[\u4e00-\u9fa5]*直销渠道*[\u4e00-\u9fa5]','直销渠道',regex=True)
result3=result2.replace(np.nan,'未识别',regex=True)
return result3
data_pos_1['channel_type_desc']=func(data_pos_1['channel_type_desc'])
#第二种写法
data_pos_1['channel_type_desc'].replace(r'[\u4e00-\u9fa5]*实体渠道*[\u4e00-\u9fa5]','实体渠道',regex=True).replace(r'[\u4e00-\u9fa5]*电子渠道*[\u4e00-\u9fa5]','电子渠道',regex=True).replace(r'[\u4e00-\u9fa5]*直销渠道*[\u4e00-\u9fa5]','直销渠道',regex=True).replace(np.nan,'未识别',regex=True)
注意: 不可以使用 data_pos_1[‘channel_type_desc’].apply(func) 调用函数,会报错TypeError: str.replace() takes no keyword arguments,具体原因查看python报错—为什么用apply方法使用.replace()方法报错TypeError: str.replace() takes no keyword arguments
举例5:使用re.sub()函数
import re
import re
def func(data):
result1=re.sub(r'[\u4e00-\u9fa5]*实体渠道*[\u4e00-\u9fa5]',"实体渠道",str(data))
result2=re.sub(r'[\u4e00-\u9fa5]*电子渠道*[\u4e00-\u9fa5]',"电子渠道",result1)
result3=re.sub(r'[\u4e00-\u9fa5]*直销渠道*[\u4e00-\u9fa5]',"直销渠道",result2)
result4=re.sub(r'nan','未识别',result3)
return result4
data_pos_1['channel_type_desc']=data_pos_1['channel_type_desc'].apply(func)
注意: 不可以使用 data_pos_1[‘channel_type_desc’]=func(data_pos_1[‘channel_type_desc’]) 调用函数,运行结果不致,re.sub(pattern, repl, string, count=0, flags=0),第三个要被查找替换的原始字符串,必须是string字符串类型。具体参数可以参考:python基础—re模块下的函数及匹配对象的属性与方法(re.match()/re.search()…等)
方案二: 对Series数据类型使用.str.contains()方法
举例1:使用np.where()函数+.str.contains()函数
import numpy as np
data_pos_1['channel_type_desc']=np.where(data_pos_1['channel_type_desc'].str.contains('实体渠道'),'实体渠道',
np.where(data_pos_1['channel_type_desc'].str.contains('直销渠道'),'直销渠道',
np.where(data_pos_1['channel_type_desc'].str.contains('电子渠道'),'电子渠道','未识别')))
参考文章:
[1].str.contains()方法官方文档
[2]pandas下的DataFrame、Series对象的apply方法
[3].str.contains()只能对Series使用