Redis初步学习整理——第六节Cluster集群部署、主从复制、哨兵模式
前言
在实际生产中,不可能Redis是以单机启动的,因为这样的服务是非常不稳定的,现在的项目首先提倡高可用,而高可用最佳的使用方式就是分布式部署(多部署几份以分摊意外的分享),而集群部署和主从复制是一个意思,Redis是通过主从复制来完成集群部署的,哨兵机制(Sentinel)又是在主从复制上的又一级别的改进了!
一、主从复制
主从复制也就是当主服务(Master)更新时,从节点(Slave)也随之更新,这块也有一个数据库概念不得不提的,叫做读写分离,这一切的目的呢,都是为了可以更好地提高服务,保证高可用!
那么看一下Redis主从复制有什么优点:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复:当主节点发生了问题时,可以由从节点提供服务,实现快速故障恢复,也是一种服务的冗余
- 负载均衡:在主从复制上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分摊服务器的负载;尤其是在写少读多的情况下,通过多个节点来分担读负载,可以大大提高Redis服务器的并发量
再次说一下Redis不可以单机启动的原因:
- 结构上,单个Redis服务容易发生单点故障,并且一台服务器需要处理所有的请求负载,压力过大
- 容量上,Redis是使用的内存存储,一台服务器的内存是有限的,哪怕超过了百G内存,也不可能将所有的数据存放下,一般来说单台Redis最大使用内存不应该超过20G
注意:
每一台Redis服务默认自己就是Master,一个Master可以有多个Slave,但是Slave只可以有一个Master
这其中涉及到的命令如下
info replication # 显示当前redis节点状态
slaveof ip part # 设置从机,ip:主机ip;part:主机part
slaveof on one # 解除当前Redis服务的Slave角色
这两个命令就可以完成这个主从复制的部署了,因为我只有一台服务器,所以就不以服务器作为测试了,如果在一台机器上测试的话,其实就是使用不同的端口号去启用。不过我没有采用这种办法,我是在本地起了三个虚拟机,他们分别拥有三个虚拟的ip端口,实现下图的关系
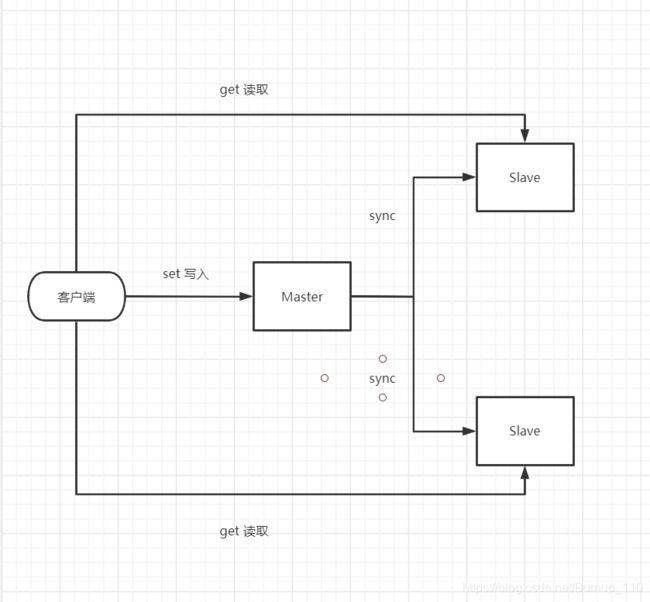
主从分离,在Master写入,其他Slave读取
(1)在shell中连接三台机器
分别安装Redis并且配置好配置文件,如果这个不太清楚的,看我第一节写的linux安装Redis教程,这里开启Redis服务,并且查看一下Redis的状态,可以看出来现在是Master,其他两台机器和这个状态一致

(2)其他两台Redis服务分别设置成Slave
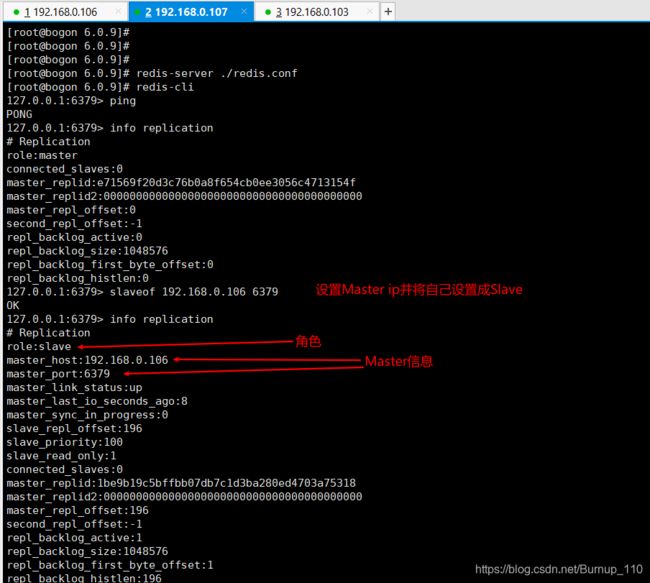
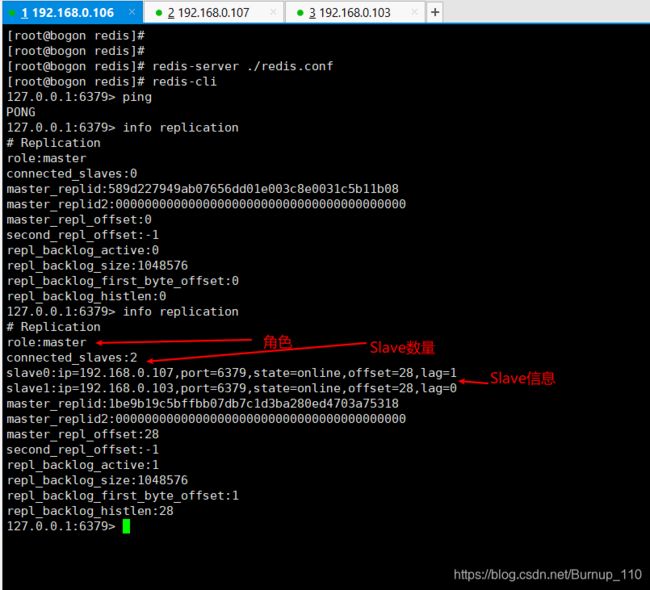
自此就设置完了,配置这个是非常简单的,让我们测试一下以及研究一下目前存在的问题
(3)综合测试
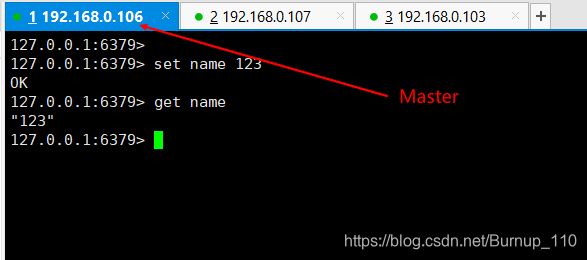
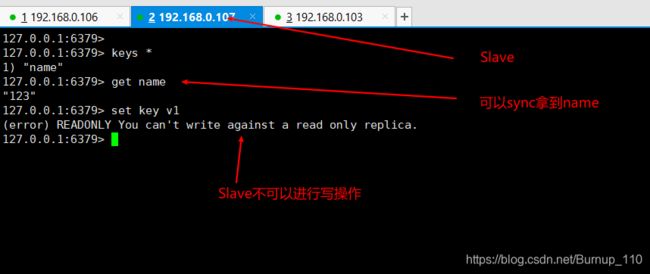
第一需要注意的是,Slave不可以进行写操作
这里试想一下,在这个简单的三个集群中,会不会出现以下问题呢?
- Master宕机了,其他的状态是什么样的呢?
Master宕机后,整个集群还可以正常的进行读操作,但是因为没有Master,所以无法进行写操作,此时如果Java程序连接整个集群的话,那么应该可以正常读取,写操作时报错! - 当Master重启后,这个集群的状态又是什么样的呢?
当Master重启后,整个集群又恢复了正常运行了,数据因为有RDB持久化的原因,还是和以前一致!我人为的制造了数据丢失(删除dump.rdb文件),这个时候Master重启后,数据为空,其他Slave也为空!所以可以判断出这个数据的数据是以Master为主,如何避免因为Master的数据丢失,而导致整个集群数据丢失呢?其实这个在哨兵模式中得到了解决,简单来看就是选举其他Slave为Master,就可以避免这个问题。 - 其中一个Slave宕机了,这个集群的状态是什么样的呢?
其中一个Slave宕机了,对整个集群来说没有任何影响!及时将它重启即可 - 当这个Slave重启后,这个集群的状态是什么样的呢?
刚刚宕机Slave重启后,并不会再主动加入到这个集群中,需要使用命令手动再此加入到集群中!当然这个和是使用命令定义的集群关系有关系,也就是说命令定义集群关系是一种临时关系,当重启Redis服务后,这个关系就会失效,如何定义一个长期有效的关系呢?这个Redis也是支持的,就是当我们把关系写到redis.conf配置文件中的时候,这种关系就会随着Redis重启而在此加入到Redis集群,下面看一下这个相关配置
关于这些问题,我直接答案写到这了,好奇的也可以自己去探索,这些结论也是我实践出来的,若有问题,望指教
(4)主从复制原理
Slave启动成功首次连接Master后会发送一个sync同步命令,Master接受到命令后,启动存盘进程去收集所有修改数据集的命令,再执行完毕后,Master会将这个文件发送给Slave,完成一次完全同步(全量复制)
全量复制: Slave收到Master的数据库文件,将其完全存盘到内存中
增量复制:Master持续将新的修改命令依次传给Slave,完成sync
二、哨兵模式
关于哨兵模式这里,我整理了几篇文章来讲解一下这部分的内容,我认为这块简单的使用是非常方便的,在网络上摘抄一些配置内容就可以启动了,但是具体到其中的观念还是挺多的!以下内容不涉及哨兵相关的算法,这块超出了我目前探索的范围
1. 概念
(1)哨兵的概述和优缺点
哨兵机制(Sentinel)是基于Redis的主从复制的,也是为了解决主从复制所带来的问题,有句话说得好,程序里边就没有加一层解决不了的问题,就好比主从复制很方便,但是如果集群中某个机器宕机了,这就需要人工去操作重启和配置了,这里就是很不智能的地方!
那如何解决呢?当然是启用另外一个进程或者服务去监听Redis集群,如果发现宕机或者不可用,那么自动进行配置!而不是人工进行配置,这样就可以解决问题了

就好比如上图,当又有一个问题来了,那要是哨兵这个机器宕机了呢?这就是一个高可用的问题,凡是高可用的问题,大多数集群必定可以解决,搭建一个Sentinel集群就好了
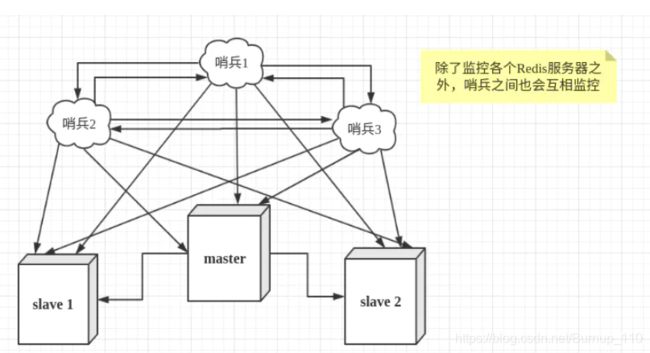
所以程序的本质的处理方式都是相同的,或许语法不太相同,但是解决方案大同小异
优点:
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都有。
- 主从可以自动切换,系统更健壮,可用性更高
缺点:
- redis较难支持在线扩容,在集群容量达上限时在线扩容变的很复杂。
####(2)SDOWN和ODOWN
上面了解了什么是Sentinel,这里立刻就引入了这两个名词,主要是在Sentinel监控的过程中,是如何认为Master节点宕机了呢?首先Sentinel肯定是实时监控着Master节点,这个肯定没错,当Sentinel对Master节点发送ping命令反应超时或者回应错误的时候,那么这个Sentinel节点就认为Master节点SDOWN(主观下线),因为一般都是有Sentinel集群的,所以一个Sentinel认为Master节点SDOWN肯定是不行的,只要超过了(配置的参数)预定的Sentinel节点都认为这个Master节点SDOWN,那么这个节点才真正的ODOWN(客观下线),随后才会选举出一个Sentinel节点去执行failover。
需要注意的是: SDOWN和ODOWN这种概念只适用于Master节点,Slave节点并不适用
(2)版本号
- 当确定ODOWN并且一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
- sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover
- 总结一下,Sentinel必须被其他Sentinel选举并授权后才能进行failover(故障转移),并且在failover时,它是有一个配置版本号的,这个是唯一的!当它成功配置后,会将这个配置应用给所有的节点。如果失败了,那么另外一个Sentinel重新获取一个唯一的版本号再次进行failover
(3)配置传播
- 一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
- 一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
- 当将一个slave选举为master并发送SLAVEOF NO ONE后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的,然后所有sentinels将会发布新的配置信息。
- 举个例子:
当SentinelA被推选出来进行failover,此时它的最新版本号是2,其他sentinel版本号是1,那么当它failover成功后,会将最新配置2同步到其他的节点,其他节点接受到最新配置后会和自己的配置进行对比,发现最新配置版本号更高后,更新配置
这意味着sentinel集群保证了第二种活跃性:一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
(4)Sentinel之间的自动发现机制
- 虽然sentinel集群中各个sentinel都互相连接彼此来检查对方的可用性以及互相发送消息。但是你不用在任何一个sentinel配置任何其它的sentinel的节点。因为sentinel利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点。通过向名为__sentinel__:hello的管道中发送消息来实现。
- 同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
- 每个sentinel通过向每个master和slave的发布/订阅频道__sentinel__:hello每秒发送一次消息,来宣布它的存在。
- 每个sentinel也订阅了每个master和slave的频道__sentinel__:hello的内容,来发现未知的sentinel,当检测到了新的sentinel,则将其加入到自身维护的master监控列表中。
- 每个sentinel发送的消息中也包含了其当前维护的最新的master配置。如果某个sentinel发现自己的配置版本低于接收到的配置版本,则会用新的配置更新自己的master配置。
- 在为一个master添加一个新的sentinel前,sentinel总是检查是否已经有sentinel与新的sentinel的进程号或者是地址是一样的。如果是那样,这个sentinel将会被删除,而把新的sentinel添加上去。
(5)Slave之间的选举和优先级
这里涉及到了,Sentinel是如何来判断在Slave中选举出Master的,主要是根据以下几点
- 与master断开连接的次数
- Slave的优先级
- 数据复制的下标(用来评估slave当前拥有多少master的数据)
- 进程ID
关于断开连接次数是很重要去否决一个Slave成为Master的条件
如果一个slave与master失去联系超过10次,并且每次都超过了配置的最大失联时间(down-after-milliseconds),如果sentinel在进行failover时发现slave失联,那么这个slave就会被sentinel认为不适合用来做新master的。
更严格的定义是,如果一个slave持续断开连接的时间超过
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
就会被认为失去选举资格。
符合上述条件的slave才会被列入master候选人列表,并根据以下顺序来进行排序:
- sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。
- 如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。
- 如果优先级和下标都相同,就选择进程ID较小的那个。
一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。要注意到master也是有可能通过failover变成slave的。
如果一个redis的slave优先级配置为0,那么它将永远不会被选为master。但是它依然会从master哪里复制数据。
(6)Sentinel工作原理
- Sentinel集群通过给定的配置文件发现master,启动时会监控master。通过向master发送info信息获得该服务下面的所有从服务器。
- Sentinel集群通过命令连接向被监控的主从服务器发送hello信息(每秒一次),该信息包括Sentinel本身的ip、端口、id等内容,以此来向其他Sentinel宣告自己的存在。
- Sentinel集群通过订阅连接接收其他Sentinel发送的hello信息,以此来发现监视同一个主服务器的其他Sentinel;集群之间会互相创建命令连接用于通信,因为已经有主从服务器作为发送和接收hello信息的中介,Sentinel之间不会创建订阅连接。
- Sentinel集群使用Sentinel命令来检测实例的状态,如果指定的时间内(down-after-milliseconds)没有回复或者返回错误回复,那么该实例被判为主观下线SDOWN。
- 当failover主备切换被触发后,failover并不会马上进行,还需要Sentinel集群中另外quorum个其他Sentinel授权,成功后进入ODOWN客观下线状态,之后再进行failover。
- Sentinel向选为master的slave发送slaveof no one 命令,选择slave的条件是上面提到的选举条件
- Sentinel被授权后会获得宕机的master的一份最新配置版本号(config-epoch)当failover结束后,这个版本号将会用于最新的配置,通过广播的形式通知其他Sentinel,其它的Sentinel则更新对应的master配置。
(7)网络隔离时的一致性
例子:
- 有三个主机,每个主机分别运行一个redis和一个sentinel。初始状态下redis3是master, redis1和redis2是slave。
- 之后redis3所在的主机网络不可用了,sentinel1和sentinel2启动了failover并把redis1选举为master。
- Sentinel集群的特性保证了sentinel1和sentinel2得到了关于master的最新配置。但是sentinel3依然是旧的配置,因为它与外界隔离了。
当网络恢复以后,我们知道sentinel3将会更新它的配置。但是,如果客户端所连接的master被网络隔离,会发生什么呢?
- 客户端将依然可以向redis3写数据,但是当网络恢复后,redis3就会变成redis的一个slave,那么,在网络隔离期间,客户端向redis3写的数据将会丢失。(主要是主从复制的特性)
- 因为redis采用的是异步复制,在这样的场景下,没有办法避免数据的丢失。然而,你可以通过以下配置来配置redis3和redis1,使得数据不会丢失。
min-slaves-to-write 1
min-slaves-max-lag 10
通过上面的配置,当一个redis是master时,如果它不能向至少一个slave写数据(上面的min-slaves-to-write指定了slave的数量),它将会拒绝接受客户端的写请求。
于复制是异步的,master无法向slave写数据意味着slave要么断开连接了,要么不在指定时间内向master发送同步数据的请求了(上面的min-slaves-max-lag指定了这个时间)。
2. 配置
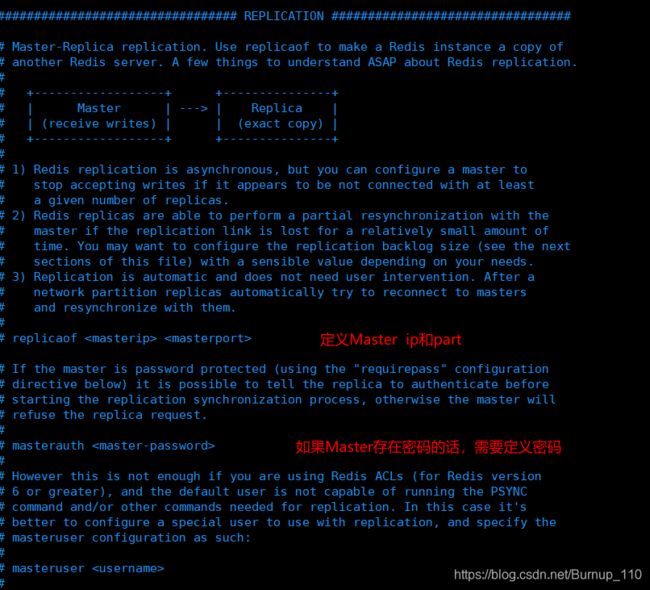
(1)redis.conf 关于主从复制的详细配置
################################# REPLICATION #################################
#复制选项,slave复制对应的master。
# slaveof
#如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。
# masterauth (2)sentinel.conf配置
port 20086 #默认端口26379
dir "/tmp"
logfile "/var/log/redis/sentinel_20086.log"
daemonize yes
#格式:sentinel ;#该行的意思是:监控的master的名字叫做T1(自定义),地址为127.0.0.1:10086,行尾最后的一个2代表在sentinel集群中,多少个sentinel认为masters死了,才能真正认为该master不可用了。
sentinel monitor T1 127.0.0.1 10086 2
#sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒,默认30秒。
sentinel down-after-milliseconds T1 15000
#failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。默认180秒,即3分钟。
sentinel failover-timeout T1 120000
#在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
sentinel parallel-syncs T1 1
#sentinel 连接设置了密码的主和从
#sentinel auth-pass xxxxx
#发生切换之后执行的一个自定义脚本:如发邮件、vip切换等
##sentinel notification-script ##不会执行,疑问?
#sentinel client-reconfig-script ##这个会执行
以上内容整理自Redis哨兵机制(sentinel),这个博主写的有点多,看了两三个小时,才理清楚,本来想总结整理一下的,但是发现如果想理解清晰透彻,有些内容确实不能少,所以只是整理了一部分,有些内容就照搬了
(3)Redis Sentinel集群部署
我是以虚拟机进行搭建集群的,分别在三台虚拟机上启动了一个Redis服务以及Sentinel服务,下面是详细的配置信息
1)redis.conf配置信息(关于Replication部分的)
# Slave配置一个Master的关联就可以了,其他的使用默认的就可以(毕竟是测试使用,没有那么多的要求)
replicaof 10.159.82.6 6379
2)sentinel.conf配置信息(只修改部分,其他默认)
sentinel monitor mymaster 10.159.82.6 6379 2
sentinel down-after-milliseconds mymaster 10000
3)启动Redis集群
然后依次启用所有Redis集群即可,记得这里要Master先启动,其他的顺序都没关系
redis启动命令
redis.server ./redis.conf
sentinel启动命令
redis.sentinel ./sentinel.conf
这种效果就可以了
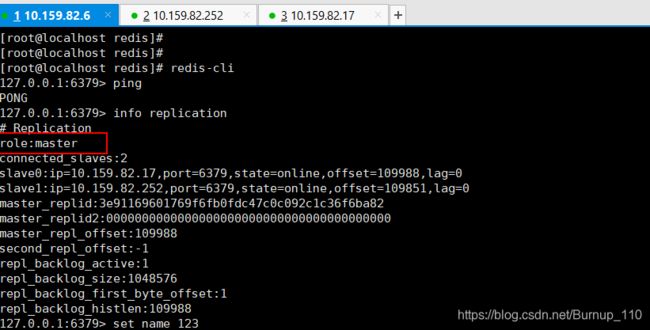
之后就可以进行测试了,比如手动将Master宕机掉,看一下Sentinel是否会选举出一个Master,我这边是没问题的,这块只要配置文件没问题了,启动。。。。不可能出问题吧,这不可能吧
三、Cluster集群部署
集群就是cluster,这块不得不说一下写这篇博客的辛酸,在写这篇博客之前,我一直以为由三个节点组成的集群就是cluster,结果大错特错,耽误了好长时间,不过这也让我查看了好多文章,对这部分内容理解更深刻了些
下面着重讲一下Redis中主从复制、sentinel、cluster的区别
- 主从模式:备份数据、负载均衡,读写分离,一个Master可以有多个Slaves。
- 监控,自动转移,sentinel发现master挂了后,就会从slave中重新选举一个master。
- 为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
- Sentinel应用于高可用,cluster我认为是Sentinel的又一提升,可用于高并发及单机存储有限问题
搭建Cluster集群
(1)准备
首先需要准备六个节点,集群一般都是两个为一组,一共三组,这个在我看来也是最小的集群模型了!这六个节点可以在一个服务器中搭建,但是这个其实是一个伪集群,它并不能做到风险分摊。我这边是在三个虚拟机上搭建了六个节点,对了cluster集群搭建好了之后,它默认两个为一组的主从节点不是一个主机
(2)配置文件
这里他的参数很多,我测试所用只修改打开了他的cluster开关,其他内容采用了默认的形式
cluster-enabled yes #开启集群模式
cluster-config-file nodes-7000.conf #集群内部的配置文件
cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no
因为可能是在一个主机中进行的多个节点的分配,所以一定要修改port端口号和pid进程号,不要打开replication主从复制的配置
(3)启动服务
分别启动六个节点服务,这块我是直接写了一个脚本文件进行启动的
cd /opt/redis/6.0.9/conf/6379
./redis-server6379 ./redis6379.conf
cd /opt/redis/6.0.9/conf/6380
./redis-server6380 ./redis6380.conf
上边就是脚本文件redis-cluster.sh的内容,如果创建了脚本文件一定要给它授权后才能使用
chmod +x redis-cluster.sh
这样就可以直接启动脚本文件了
(4)搭建集群
开启六个节点服务后,就可以直接搭建集群了,这块有一点需要注意的是,现在大多数的DSCN文章都是对以前的Redis版本进行的讲解,所以使用的是ruby搭建Redis的方法!但是在Redis5.0之后,使用了redis-cli就可以进行集群的搭建了
使用命令
redis-cli --cluster create 10.159.82.252:6379 10.159.82.252:6380 10.159.82.6:6379 10.159.82.6:6380 10.159.82.17:6379 10.159.82.17:6380 --cluster-replicas 1
cluster-replicas:从机数量
redis-cli --cluster create:后面跟着的是六个节点的ip和端口号
执行命令后如下
[root@localhost conf]# redis-cli --cluster create 10.159.82.252:6379 10.159.82.252:6380 10.159.82.6:6379 10.159.82.6:6380 10.159.82.17:6379 10.159.82.17:6380 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.159.82.6:6380 to 10.159.82.252:6379
Adding replica 10.159.82.17:6380 to 10.159.82.6:6379
Adding replica 10.159.82.252:6380 to 10.159.82.17:6379
M: 2f8d3e6906a2f925f1b9da164f3ca89b452760ad 10.159.82.252:6379
slots:[0-5460] (5461 slots) master
S: bf26ca8ce8db660493817b72a880c8de6c8d7bf3 10.159.82.252:6380
replicates 729a491dd4aaeb1b986e523fa21374ba42badc68
M: 6076e01590550da6cc56fb365f4757af3bcfaf51 10.159.82.6:6379
slots:[5461-10922] (5462 slots) master
S: 3b07433fe987dda2db812a1403f86b4a846cf874 10.159.82.6:6380
replicates 2f8d3e6906a2f925f1b9da164f3ca89b452760ad
M: 729a491dd4aaeb1b986e523fa21374ba42badc68 10.159.82.17:6379
slots:[10923-16383] (5461 slots) master
S: 56357f19fab6dd5e780f06f78decc067e60c9f75 10.159.82.17:6380
replicates 6076e01590550da6cc56fb365f4757af3bcfaf51
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 10.159.82.252:6379)
M: 2f8d3e6906a2f925f1b9da164f3ca89b452760ad 10.159.82.252:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: bf26ca8ce8db660493817b72a880c8de6c8d7bf3 10.159.82.252:6380
slots: (0 slots) slave
replicates 729a491dd4aaeb1b986e523fa21374ba42badc68
S: 3b07433fe987dda2db812a1403f86b4a846cf874 10.159.82.6:6380
slots: (0 slots) slave
replicates 2f8d3e6906a2f925f1b9da164f3ca89b452760ad
M: 6076e01590550da6cc56fb365f4757af3bcfaf51 10.159.82.6:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 56357f19fab6dd5e780f06f78decc067e60c9f75 10.159.82.17:6380
slots: (0 slots) slave
replicates 6076e01590550da6cc56fb365f4757af3bcfaf51
M: 729a491dd4aaeb1b986e523fa21374ba42badc68 10.159.82.17:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
创建集群的过程中可能会遇到各种问题,下面我简单举例几个常见的
- 执行过创建集群命令redis-cli --cluster create,并因为其他原因失败,再此创建提示错误信息,如下

这种问题,是因为每次创建集群,Redis 都会自动生成一个node.conf的配置文件,这个文件中记录了之前创建集群生成的配置信息,如果再此创建集群,需要将这类文件删除掉 - 没有截图了,还有就是执行创建集群命令后一直在等待,这个大概率是因为使用的服务器的防火墙没有打开,需要打开防火墙重试
- 登录集群需要使用命令:redis-cli -c,一定要加上-c,代表进入集群
(5)cluster 常见命令
- 获取cluster节点信息:redis-cli -p 6379 cluster nodes
[root@localhost conf]# redis-cli -p 6379 cluster nodes
729a491dd4aaeb1b986e523fa21374ba42badc68 10.159.82.17:6379@16379 myself,master - 0 1608292538000 5 connected 10923-16383
6076e01590550da6cc56fb365f4757af3bcfaf51 10.159.82.6:6379@16379 master - 0 1608292538376 3 connected 5461-10922
bf26ca8ce8db660493817b72a880c8de6c8d7bf3 10.159.82.252:6380@16380 slave 729a491dd4aaeb1b986e523fa21374ba42badc68 0 1608292539383 5 connected
3b07433fe987dda2db812a1403f86b4a846cf874 10.159.82.6:6380@16380 slave 2f8d3e6906a2f925f1b9da164f3ca89b452760ad 0 1608292540389 1 connected
2f8d3e6906a2f925f1b9da164f3ca89b452760ad 10.159.82.252:6379@16379 master - 0 1608292536000 1 connected 0-5460
56357f19fab6dd5e780f06f78decc067e60c9f75 10.159.82.17:6380@16380 slave 6076e01590550da6cc56fb365f4757af3bcfaf51 0 1608292537368 3 connected
- 获取cluster信息:redis-cli -p 6379 cluster info
[root@localhost conf]# redis-cli -p 6379 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:5
cluster_stats_messages_ping_sent:538
cluster_stats_messages_pong_sent:573
cluster_stats_messages_meet_sent:1
cluster_stats_messages_sent:1112
cluster_stats_messages_ping_received:573
cluster_stats_messages_pong_received:539
cluster_stats_messages_received:1112
- 在连接中,获取cluster状态:info cluster
127.0.0.1:6379> info cluster
# Cluster
cluster_enabled:1
- 在连接中,获取cluster信息帮助:cluster help
127.0.0.1:6379> cluster help
1) CLUSTER <subcommand> arg arg ... arg. Subcommands are:
2) ADDSLOTS <slot> [slot ...] -- Assign slots to current node.
3) BUMPEPOCH -- Advance the cluster config epoch.
4) COUNT-failure-reports <node-id> -- Return number of failure reports for <node-id>.
5) COUNTKEYSINSLOT <slot> - Return the number of keys in <slot>.
6) DELSLOTS <slot> [slot ...] -- Delete slots information from current node.
7) FAILOVER [force|takeover] -- Promote current replica node to being a master.
8) FORGET <node-id> -- Remove a node from the cluster.
9) GETKEYSINSLOT <slot> <count> -- Return key names stored by current node in a slot.
10) FLUSHSLOTS -- Delete current node own slots information.
11) INFO - Return information about the cluster.
12) KEYSLOT <key> -- Return the hash slot for <key>.
13) MEET <ip> <port> [bus-port] -- Connect nodes into a working cluster.
14) MYID -- Return the node id.
15) NODES -- Return cluster configuration seen by node. Output format:
16) <id> <ip:port> <flags> <master> <pings> <pongs> <epoch> <link> <slot> ... <slot>
17) REPLICATE <node-id> -- Configure current node as replica to <node-id>.
18) RESET [hard|soft] -- Reset current node (default: soft).
19) SET-config-epoch <epoch> - Set config epoch of current node.
20) SETSLOT <slot> (importing|migrating|stable|node <node-id>) -- Set slot state.
21) REPLICAS <node-id> -- Return <node-id> replicas.
22) SAVECONFIG - Force saving cluster configuration on disk.
23) SLOTS -- Return information about slots range mappings. Each range is made of:
24) start, end, master and replicas IP addresses, ports and ids
- 在连接中,获取cluster信息:cluster nodes
127.0.0.1:6379> cluster nodes
729a491dd4aaeb1b986e523fa21374ba42badc68 10.159.82.17:6379@16379 myself,master - 0 1608292718000 5 connected 10923-16383
6076e01590550da6cc56fb365f4757af3bcfaf51 10.159.82.6:6379@16379 master - 0 1608292717764 3 connected 5461-10922
bf26ca8ce8db660493817b72a880c8de6c8d7bf3 10.159.82.252:6380@16380 slave 729a491dd4aaeb1b986e523fa21374ba42badc68 0 1608292715751 5 connected
3b07433fe987dda2db812a1403f86b4a846cf874 10.159.82.6:6380@16380 slave 2f8d3e6906a2f925f1b9da164f3ca89b452760ad 0 1608292718771 1 connected
2f8d3e6906a2f925f1b9da164f3ca89b452760ad 10.159.82.252:6379@16379 master - 0 1608292717000 1 connected 0-5460
56357f19fab6dd5e780f06f78decc067e60c9f75 10.159.82.17:6380@16380 slave 6076e01590550da6cc56fb365f4757af3bcfaf51 0 1608292716757 3 connected
其他的根据help信息,应该可以了解
下面看一下在java程序中 如何连接redis集群
四、SpringBoot 连接Redis集群(Lettuce、Sentinel,Cluster)
接下来的Springboot很简单,其实就是配置一些配置文件,写一些配置类,这块对于基础使用的朋友已经足够了,如果有深入想了解底层流程或者优化连接的朋友那估计要等半年左右我去解读一下Lettuce底层了,那时候没准你就先会了。
下面是我对Cluster的配置,如果是Sentinel 的话,那修改一下配置就好了。对了,我认为针对于上面Redis的三种集群模式,Spring Data 也有三种不同的连接方式,分别是读写分离、Sentinel连接,Cluster连接。有兴趣的朋友可以去了解一下,这边只有Cluster连接,重点说一下,这三种肯定是Cluster最完善,但是并不是Cluster最好,因为任何技术都要根据业务来说的,当你业务量比较少的时候,用Cluster那分明是大炮打鸟。。哈哈
(1)依赖坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<!-- redis依赖commons-pool 这个依赖一定要添加 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
(2)yml 配置文件
spring:
redis:
# host: 127.0.0.1 # 单机配置
# port: 6379
timeout: 10000ms
database: 0
# sentinel: # Sentinel 配置
# master: mymaster
# nodes:
# - 10.159.82.252:26379 # Sentinel 地址
# - 10.159.82.17:26379
# - 10.159.82.6:26379
cluster: # 配置Cluster集群
nodes:
- 10.159.82.252:6379
- 10.159.82.17:6379
- 10.159.82.6:6379
- 10.159.82.252:6380
- 10.159.82.17:6380
- 10.159.82.6:6380
max-redirects: 2 # 获取失败 最大重定向次数
lettuce:
pool:
max-active: 1000 #连接池最大连接数(使用负值表示没有限制)
max-idle: 10 # 连接池中的最大空闲连接
min-idle: 5 # 连接池中的最小空闲连接
max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制)
(3)Config配置文件
/**
* @program: redis-demo
* @description: Redis配置类
**/
@Configuration
@EnableCaching // 开启缓存支持
public class RedisConfig extends CachingConfigurerSupport {
@Resource
private LettuceConnectionFactory lettuceConnectionFactory;
private static Logger logger = LoggerFactory.getLogger(RedisConfig.class);
@Override
@Bean
public KeyGenerator keyGenerator() {
return (target, method, params) -> {
StringBuffer sb = new StringBuffer();
sb.append(target.getClass().getName());
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
};
}
// 缓存管理器
@Override
@Bean
public CacheManager cacheManager() {
RedisCacheManager.RedisCacheManagerBuilder builder = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(lettuceConnectionFactory);
@SuppressWarnings("serial")
Set<String> cacheNames = new HashSet<String>() {
{
add("codeNameCache");
}
};
builder.initialCacheNames(cacheNames);
return builder.build();
}
/**
* 配置Redis 序列化
* @param redisConnectionFactory
* @return
*/
@Bean("redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
template.setKeySerializer(stringRedisSerializer);
template.setHashKeySerializer(stringRedisSerializer);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
template.setValueSerializer(jackson2JsonRedisSerializer);
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
}
(4)Redis工具类
在实际工作中,不可能是使用RedisTemplate对Redis进行操作的,肯定是对RedisTemplate进行的又一层封装,这里有一个通用版的Redis Util类,需要的朋友自行拿走,不谢,点赞即可
/**
* @program: redis-demo
* @description: Redis 工具类,在实际使用的过程中,是对RedisTemplate进行再次封装,以简化开发,这里提供一个通用的Redis工具类
**/
@Component
public class RedisUtil {
private static Logger logger = LoggerFactory.getLogger(RedisCacheManager.class);
@Autowired
@Qualifier("redisTemplate")
private RedisTemplate redisTemplate;
/**
* <b>功能:清库</b><br>
* <br>
*
* @return String
* @Author:pfyangf , 2018年5月25日
*/
public void flushDb() {
this.redisTemplate.execute(new RedisCallback<Object>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
connection.flushDb();
return "ok";
}
});
}
/**
* 指定缓存失效时间
*
* @param key 键
* @param time 时间(秒)
* @return
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 根据key 获取过期时间
*
* @param key 键 不能为null
* @return 时间(秒) 返回0代表为永久有效
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判断key是否存在
*
* @param key 键
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 删除缓存
*
* @param key 可以传一个值 或多个
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* 普通缓存获取
*
* @param key 键
* @return 值
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通缓存放入
*
* @param key 键
* @param value 值
* @return true成功 false失败
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* <b>功能:向通道发布数据</b><br>
* <br>
*
* @param channel
* @param message
* @return boolean
* @Author:pfyangf , 2018年3月13日
*/
public boolean publish(String channel, Serializable message) {
try {
this.redisTemplate.convertAndSend(channel, message);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 普通缓存放入并设置时间
*
* @param key 键
* @param value 值
* @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期
* @return true成功 false 失败
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 递增
*
* @param key 键
* @param delta 要增加几(大于0)
* @return
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递增因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 递减
*
* @param key 键
* @param delta 要减少几(小于0)
* @return
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递减因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return 值
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 获取hashKey对应的所有键值
*
* @param key 键
* @return 对应的多个键值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
*
* @param key 键
* @param map 对应多个键值
* @return true 成功 false 失败
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* HashSet 并设置时间
*
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 删除hash表中的值
*
* @param key 键 不能为null
* @param item 项 可以使多个 不能为null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
* @return
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash递减
*
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
* @return
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根据key获取Set中的所有值
*
* @param key 键
* @return
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return null;
}
}
/**
* 根据value从一个set中查询,是否存在
*
* @param key 键
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
/**
* 将set数据放入缓存
*
* @param key 键
* @param time 时间(秒)
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0) {
expire(key, time);
}
return count;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
/**
* 获取set缓存的长度
*
* @param key 键
* @return
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
/**
* 移除值为value的
*
* @param key 键
* @param values 值 可以是多个
* @return 移除的个数
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
// ===============================list=================================
/**
* 获取list缓存的内容
*
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
* @return
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return null;
}
}
/**
* 获取list缓存的长度
*
* @param key 键
* @return
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
/**
* 通过索引 获取list中的值
*
* @param key 键
* @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推
* @return
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
logger.error("执行程序异常:",e);
return null;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 根据索引修改list中的某条数据
*
* @param key 键
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return false;
}
}
/**
* 移除N个值为value
*
* @param key 键
* @param count 移除多少个
* @param value 值
* @return 移除的个数
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
logger.error("执行程序异常:",e);
return 0;
}
}
}
(5)测试
这里测试的话,我是使用的测试类进行的,其实不管是单机版、Sentinel还是Cluster集群,对于java层面来说使用都是一致的,都是直接调用Util类即可,当然如果是读写分离的模式的话,那么我估计还需要在Util中做一些处理,但是展现给最上层来看的都是一致的。这样也是非常重要的编程思想——封装
/**
* 测试Redis集群
*/
@Test
public void test1(){
redisUtil.flushDb();
redisUtil.set("name","xiaoming");
System.out.println(redisUtil.get("name"));
}
五、问题
在研究Redis的过程中,我看过很多教学视频以及各种相关文章,但是学习的更多难免产生了更多的疑惑,以下记录一下,望各位大神可以讨论答复一下
- SpringData连接Redis集群,是否实现了读写分离?就是我单单像上面那样写了一些配置文件和配置类,我操作Redis的时候,是否会自动写入在主节点,读取在从节点呢?
以后有时间研究SpringData-Redis源码的时候,我也会来追更的
六、结语
本来想一天结束,没想到弄了一周,本来想这一节直接结束Redis了,结果看样子还需要一节来补充Redis的内容,下一节将讲解Redis的缓存击穿、缓存穿透、缓存雪崩、数据预热以及缓存模式