基于机器学习的影像组学根据磁共振成像对胶质母细胞瘤患者转录亚型进行有效分类
背景:在胶质瘤领域,转录组亚型被认为是一种重要的诊断和预后生物标志物,有助于提高治疗效果。然而,现有的转录组亚型鉴别方法由于检测周期相对较长、无法通过活检或手术获得肿瘤标本以及病变内异质性而受到限制。为了寻找优于先前模型的方法,本研究评估了基于极端梯度增强(XGBoost)的影像组学模型对胶质母细胞瘤患者转录组亚型进行分类。
方法:这项回顾性研究检索了TCGA-GBM和IvyGAP队列中病理诊断为胶质母细胞瘤的患者,并将他们分为不同的转录组亚型组。然后将GBM患者图像分为三种不同的MRI区域:肿瘤核心增强区(ET)、肿瘤核心非增强区(NET)和瘤周水肿区(ED)。随后,我们基于多模态MRI手动提取的影像组学特征(n=704)和特征选择方法(Spearman相关性和F评分检验)建立机器学习模型,找到相关的特征。
结果:在特征选择方法之后,我们确定了13个显著的影像组学特征,这些特征是最有意义的,可用于获得最佳鉴别结果。有了这些特征,我们的XGBoost模型对经典、间质、神经和原神经亚型的预测准确率分别达到70.9%、73.3%、88.4%和88.4%。与其他模型以及之前在同一数据集上的方法相比,我们的模型性能有所提高。
结论:XGBoost和特征选择方法(Spearman相关性和F评分)的使用有望成为高效分类转录组亚型的潜在组合,并可能引起公众对基于影像组学的GBM分类模型进一步研究的关注。本文发表在Computers in Biology and Medicine杂志。
1 引言
胶质母细胞瘤(GBM)是最具侵袭性和异常侵袭性的脑肿瘤,根据其起源细胞进行分类[1]。全球每年每10万人中有2至3人患有GBM,占所有原发性脑瘤的52%。尽管GBM的发病率相对较低,但其不良预后(侵袭性和浸润性生长模式)使得无法进行治疗[2,3]。尽管全球范围内做出了大量努力,但GBM的治疗仍然被认为是临床上最困难的工作。肿瘤的组织病理学分析是GBM最终诊断的参考标准。最近,肿瘤基因组特征(可从手术切除中获得的组织)推进了GBM的临床评估,以提供治疗反应和结果的额外预测因子。
影像组学是一种新方法,通常用于确定临床症状和潜在遗传特征之间的关联[4]。肿瘤表型可以通过从高通量医学图像中提取大量特征来确定[5]。在先前发表的研究中,使用影像组学模型对神经胶质瘤的不同亚型进行了分类。例如,通过使用磁共振成像(MRI)灰度不变纹理特征[6]、五个显著特征[7]、基于小波的特征[8],甚至深度学习特征[9]来确定胶质瘤分级。对于分子亚型分类,异柠檬酸脱氢酶(IDH)突变状态、1p/19q编码缺失状态、TERT启动子状态和O6甲基鸟嘌呤DNA甲基转移酶(MGMT)甲基化状态已被用作关键生物标记物。因此,Lu等人基于影像组学构建机器学习模型进行神经胶质瘤三级分类 [10]。这些分子亚型由IDH基因的突变状态和1p/19q的共缺失状态确定。对于每个突变状态,影像组学模型已用于预测IDH[11–14]、1p/19q缺失[12,15]、TERT启动子[16,17]、p53[18]和MGMT[19,20]的状态。
除了世界卫生组织分级或分子亚型外,转录组亚型的分类在GBM的评估和治疗中也起着至关重要的作用。根据文献[21],GBM可分为四种转录组亚型:经典型、间质型、神经型和原神经型。这些亚型包括不同的生物标志物,如经典亚型中的10号染色体集体缺失和7号染色体扩增,17q11.2区域的局部半合子缺失,包括间充质亚型中NF1基因,原神经亚型中PDGFRA畸变和IDH1突变,以及神经亚型的GABRA1、SYT1、NEFL和SLC12A5。最近的研究[22]还表明,亚类遗传异常具有作为预测标记和治疗靶向的能力。由于这些转录组亚型在GBM中的重要性,它们被认为是替莫唑胺耐药性和不良无进展生存(PFS)的关键因素。因此,识别转录组亚型的无创成像生物标志物可以为GBM治疗提供辅助,并提供准确的治疗指导和预后。
如何基于MRI的影像组学特征对GBM的转录组亚型进行分类是目前一项具有挑战性的任务。为了解决这个问题,已经进行了一些影像组学研究。例如,Saima等人[23]对GBMs的转录组亚型进行了分类,平均准确率为71%。Macyszyn等人[24]在创建基于多模态MRI的模型实现了76%的多分类准确率,该模型包含105名患者的60个不同特征。Lee等人[25]通过将多分类问题分为四个二元分类来解决该问题。为了筛选显著的影像组学特征,Yang等人[26]证实,纹理特征可能在GBM转录组亚型分类中发挥重要作用。Kourosh等人[27]搜集了46名GBM患者,仅用于鉴定间充质分子亚型。Nicholas等人[28]创建了一项基于影像基因组学的间充质亚型和经典亚型分类的研究。
先前的工作已经提出了一些有前景的机器学习模型和影像组学特征,用于分类GBMs中的转录组亚型。然而,性能仍然不令人满意,并且很难研究有助于提高分类性能的其他模型。为了解决这个问题,本研究提出了基于极端梯度增强(XGBoost)结合两级(Spearman相关和F-score)特征筛选方法的高效的影像组学模型。
2 材料与方法
图1展示了我们提出的影像组学框架,系统在以下小节中描述。
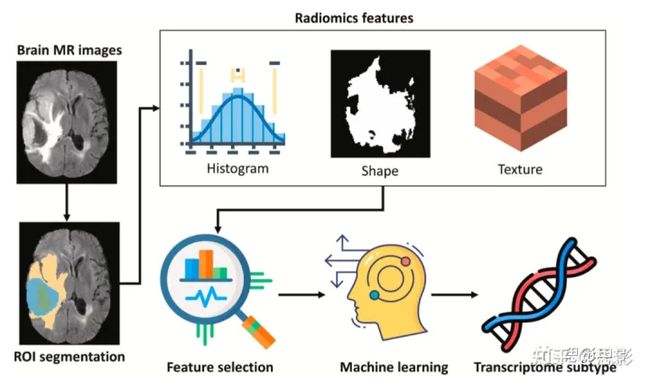
图1.本研究的流程图。它包括四个过程:数据收集、影像组学特征提取、特征选择和机器学习实现。
2.1 入组病例
我们的患者队列是从癌症成像档案(TCIA)[29]获得的,这是一个可下载的大量癌症医学图像的公共资源库。由于我们旨在对GBM的转录组亚型进行分类,我们从TCGA-GBM项目中选择了患者数据[30]。该项目包括262名参与者(来自美国和意大利的八家机构)及其术前多模态磁共振成像(MRI)图像。选择的MRI模态为T1加权成像(T1)、T1加权增强(T1-Gd)成像、T2成像和T2-FLAIR成像。经典型、间叶型、神经型和原神经型转录组亚型的受试者数量分别为20、34、11和21[31]。同时,我们使用了86例患者的转录组亚型信息,将其纳入下一次分析。
大多数影像组学指南建议使用外部验证集来验证其再现性和重复性[32]。因此,我们还从TCIA检索了另一个GBM集,以验证我们的预测性能以及我们的影像组学特征。所选数据集为Ivy胶质母细胞瘤图谱(IvyGAP)[33],其中包含GBM患者的基因组改变和基因表达模式。有34名GBM患者包含转录组亚型信息,经典型、间质型、神经型和神经原型分别为15、12、12和10。请注意,很少有患者被标记为同时属于两种甚至两种以上的转录组亚型,我们使用了所有这些信息。因此,我们将这34名GBM患者作为外部验证队列。
2.2 磁共振图像分割和影像组学特征
医学图像已根据BraTS挑战的标准进行了一致分割[34]。根据这一标准,GBM MRI可分为三个不同区域:
(1)肿瘤核心(ET)的增强区域,通过T1-Gd中相对于T1健康白质(WM)的高密度区域来区分;
(2) 与T1 Gd中的T1健康WM相比,肿瘤核心的非增强部分(NET)显示T1 Gd的低信号存在;
(3)最后,T2-FLAIR容积中的高信号用于表征瘤周水肿(ED)。
BraTS challenge还发布了分割标准[35],其中包含TCGA-GBM项目的常规特征和影像组学特征。具体而言,在分割之前,对mMRI体积执行预处理步骤,包括重新定向到LPS坐标(左后上),共同配准到同一T1解剖模板,重新采样到1mm3体素分辨率,以及颅骨剥离(使用fMRI软件库(FSL)[36])。GLISTRboost[37]是胶质瘤图像分割和配准(GLISTR)[38]的工具,用于产生分割标签。原始文章中显示的一个重要注意事项是,在分割之前,他们没有使用任何非参数、非均匀强度归一化算法来标准化磁共振成像。原因是,他们观察到,这种算法的应用消除了T2-FLAIR信号。
图2显示了如何将GBM患者分割为三个不同区域的示例。接下来,原始研究还开发了癌症成像表型工具包(CaPTk)[39],用于从图像中提取影像组学特征以及分割。本研究中使用的所有影像组学特征与图像生物标志物标准化倡议(ISBI)[40]引入的174个标准化特征一致。影像组学特征包括直方图强度信息、图像二阶特征、形状信息、纹理特征,和GLISTR后验概率图。在提取影像组学特征时,选择了面元(bin)为64的离散化方法。然后,我们使用704个已提取并输入机器学习模型的影像组学特征来评估预测性能。

图2,在多模式MRI图像上分割GBM患者的示例(患者ID:TCGA-06-5413,神经转录组亚型)。
2.3 两级影像组学特征选择方法
基于影像组学的机器学习模型最重要的问题是数据的维数。由于在机器学习模型中使用大量的影像组学特征作为特征集,这将提高模型的计算复杂性以及过拟合问题。因此,需要进行特征筛选。解决这一问题有许多常用方法(如基于相关性、基于信息论等),本研究希望在此基础上提出一种两级特征选择技术。首先,我们进行了Spearman相关检验,以评估转录组亚型分类的显著特征。如果特征在任何其他特征中具有高相关系数(>0.8),则该特征是显著的。因此,我们又基于F分数分析在上述特征中提取最佳特征。F-score是检查两组值之间的性能结果差异的方法[41],如下所示:
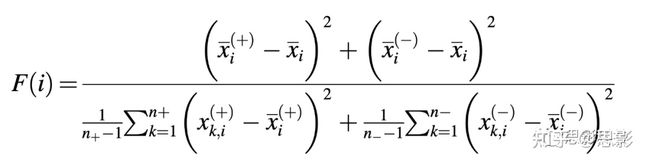
其中n+是正实例数,n− 是负实例数。此外,x , x(+), and x(− )分别是整个数据集、正数据集和负数据集的第i个特征的平均值;
X(k,i)+是第k个正实例的第i个特征;和X(k,i)-是第k个负实例的第i个特征。在先前的研究中,F分数分析已用于筛选GBM二元分类中的最佳影像组学特征[42]。在这里,我们将F分数分析扩展到多分类中,我们首先计算所有重要影像组学特征的F评分值,然后将其按降序排列,以查看最重要的特征。之后,我们将重要特征一个一个地反馈到我们的模型中,以测试特征选择的阈值。将达到最佳值的点作为选择F分数特征的最佳截止点。为了显示不同特征数量下的性能结果,我们使用递归特征消除(RFE)方法来呈现。这是一种在逐个增加特征数量后显示训练性能的有效方法。
2.4 机器学习模型构建
在这项研究中构建了不同的机器学习模型,以查看哪些模型对于这些形式的影像组学特征表现良好。这些包括k近邻(kNN)、朴素贝叶斯、随机森林、支持向量机(SVM)和XGBoost。我们的机器学习模型是使用Python编程语言和scikit学习库实现的[43]。每个机器学习算法都需要一个过程,即超参数优化,以实现最佳结果。
2.5.统计分析和测量指标
为了分析多分类问题,我们将其视为多个二分类,然后计算各个预测度量。由于数据有限,我们使用留一法交叉验证(LOOCV)作为评估方法来验证输出。在该方法中,每个样本用作测试,而其他样本用于训练,所述精度是所有测试精度的平均值。在构建模型后,我们还使用了一个外部验证集来评估我们的模型对未知数据的预测性能。我们在预测模型中采用了不同的性能指标,如准确性、受试者工作特性(ROC)曲线和曲线下面积(AUC),以分层训练数据,改进基于机器学习的GBM亚型分类。其中,ROC曲线和AUC通过显示不同阈值点的总体性能,克服了数据集不平衡问题。这些测量度量在机器学习中很常见,它们已成功地用于许多生物医学工作中,并具有很高的可靠性[42,44]。
3 结果
3.1 患者的临床特性
表1显示了我们训练和验证组的患者特性。我们的训练数据分别包含20名、34名、11名和21名经典、间充质、神经和前神经转录组患者。我们的大多数患者的基因组信息中都有IDH1野生型,因此本研究可作为IDH1野型GBM患者的转录组亚型分类。
| 表1:训练和验证集的病人特性 | ||
|---|---|---|
| 训练集(n=86) | 验证集(n=34) | |
| 年龄(均值±标准差,年) | 59.22±12.7 | |
| 性别 | ||
| 男 | 57 | 17 |
| 女 | 29 | 17 |
| 转录亚型 | ||
| 经典型 | 20 | 15 |
| 间充质 | 34 | 12 |
| 神经 | 11 | 12 |
| 前神经 | 21 | 10 |
| IDH1表型 | ||
| 野生型 | 68 | 31 |
| 突变型 | 18 | 3 |
| MGMT表型 | ||
| 甲基化 | 22 | 12 |
| 非甲基化 | 27 | 20 |
根据数据特征,前神经亚型患者比其他亚型患者年轻(平均年龄为54.6岁,其他亚型为61.4岁、59.7岁和62.8岁)。四种转录组亚型之间也存在许多性别差异,间充质和神经亚型中男性比例较高。另一方面,在经典转录组亚型中女性的比例较高。此外,不同转录组亚型和甲基化类别之间的MGMT甲基化状态没有太多差异。数据统计还显示了训练数据和验证数据之间的一致性水平,这意味着我们可以使用该IvyGAP数据集作为高质量的外部数据集来验证性能结果。
3.2.筛选显著的MRI影像组学特征
两级特征选择已用于筛选GBM转录组亚型分类的显著的影像组学特征。我们首先进行了Spearman相关检验,以统计方式查看可能影响预测性能的重要特征。在此步骤之后,我们筛选出470个显著的影像组学特征(相关系数>0.8)。接下来,我们在这些特征中应用了F分数分析,并确定了一些具有高F分数值的更具显著性的特征,如VOLUME_NET_OVER_ED(F分数=0.18037)、TEXTURE_GLCM_ET_FLAIR_Entropy(F分数=0.15062)和TEXTURE_ GLSZM_ET _FLAIR_SZHGE(F分数=0.1432)。关于影像组学特征及其F分数值的所有详细信息见补充表S1。之后,我们的RFE曲线(图3)表明,我们可以使用前13个特征(最佳截止F分数为0.1085)作为模型的输入,以获得最优结果。
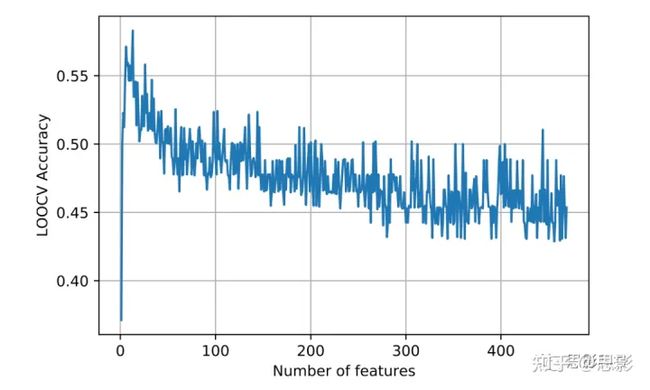
图3.使用不同数量特征分类GBM转录组亚型的RFE曲线。
在Spearman相关测试和F分数分析后,使用前13个特征达到最佳性能。
3.3 模型构建
第一个实验是为了寻找单个机器学习分类器的最佳参数。对每个算法应用相同的设置;然后在表2中给出了所有搜索的超参数的范围以及最佳值。对于实验结果,我们基于影像组学的分类器对kNN、Naïve Bayes、随机森林、SVM和XGBoost的平均准确率分别达到69.8%、75%、77.3%、71.5%和80.2%(如表3所示)。XGBoost的平均敏感性和特异性(分别为51.9%和87.5%)也优于其他方法。还进行了Wilcoxon检验,以查看XGBoost与其他分类器相比的显著改进。我们可以观察到,与其他分类器相比,XGBoost在大多数度量指标方面都有改进。在四个子类型的个体分类器中,该模型在识别间充质(敏感性为70.6%)和原神经(敏感性为66.7%)亚型方面具有良好潜力。最差的表现来自其他两种亚型;然而,对于一个具有挑战性的多分类问题来说,这也是一个可接受的水平,其特异性足够高,足以显示模型的效率。
| 表2:每个机器学习模型的最优超参数 | ||
|---|---|---|
| 机器学习模型 | 超参数范围 | 最优值 |
| 最近邻 | n_neighbors = [1,2,3,..,10] | 1 |
| weights= [uniform, distance] | uniform | |
| metric=[euclidean,manhattan, minkowski] | minkowski | |
| 随机森林 | max_depth= [80, 90, 100, 110] | 110 |
| max_features = [2, 3] | 3 | |
| min_samples_leaf = [3, 4, 5] | 4 | |
| min_samples_split = [8, 10, 12] | 8 | |
| n_estimators = [100, 200, 300, 1000] | 100 | |
| SVM | C = [0.001, 0.01, 0.1, 1, 10] | 1 |
| gammas = [0.001, 0.01, 0.1, 1] | 0.001 | |
| kernels = [rbf, linear] | rbf | |
| XGBoost | min_child_weight = [1, 5, 10] | 1 |
| gamma = [0.5, 1, 1.5, 2, 5] | 1 | |
| subsample = [0.6, 0.8, 1] | 0.8 | |
| colsample_bytree = [0.6, 0.8, 1] | 1 | |
| max_depth = [3, 4, 5] | 4 |
| 表3:不同机器学习模型和转录亚型留一交叉验证性能 | ||||
|---|---|---|---|---|
| 机器学习模型 | 转录亚型 | 敏感性 | 特异性 | 精确度 |
| K近邻 | 经典 | 50.0 | 80.3 | 73.3 |
| 间充质 | 67.6 | 42.3 | 52.3 | |
| 神经 | 9.1 | 94.7 | 83.7 | |
| 原神经 | 0.0 | 92.3 | 69.8 | |
| 朴素贝叶斯 | 经典 | 45.0 | 81.8 | 73.3 |
| 间充质 | 61.8 | 63.5 | 62.8 | |
| 神经 | 36.4 | 88.0 | 81.4 | |
| 原神经 | 42.9 | 95.4 | 82.6 | |
| 随机森林 | 经典 | 25.0 | 90.9 | 75.6 |
| 间充质 | 85.3 | 50.0 | 64.0 | |
| 神经 | 0.0 | 93.3 | 81.4 | |
| 原神经 | 61.9 | 96.9 | 88.4 | |
| 支持向量机 | 经典 | 15.0 | 97.0 | 77.9 |
| 间充质 | 82.4 | 28.8 | 50.0 | |
| 神经 | 0.0 | 98.7 | 86.0 | |
| 原神经 | 61.9 | 86.2 | 72.1 | |
| XGBoost | 经典 | 28.6 | 84.8 | 70.9 |
| 间充质 | 25.0 | 75.0 | 73.3 | |
| 神经 | 45.5 | 94.7 | 88.4 | |
| 原神经 | 66.7 | 95.4 | 88.4 |
为了观察不同阈值水平下的性能,计算ROC曲线和AUC。我们逐一提供了不同转录组亚型的XGBoost模型的ROC曲线(图4)。根据该图所示的信息,我们再次观察到,我们的模型在使用影像组学特征时结果良好(四种转录组亚型的AUC分别达到0.711、0.763、0.745和0.854)。因此,我们强烈建议可以结合这13种特征和XGBoost算法,以高性能分类GBM转录组亚类。

图4.使用XGBoost对13个显著影像组学特征进行GBM转录组亚型分类的ROC曲线分析。
3.4 验证结果
为了确保最终模型的效率,我们使用验证数据集来评估该模型和影像组学特征的预测性能。具体而言,我们使用了39名IvyGAP患者[33]的13个相同的影像组学特征,并基于其建模。图5显示了训练和验证数据集在敏感度、特异性和准确性方面的比较性能。我们观察到这两组数据之间存在一致性,这确保了我们的模型是可靠的,不包含太多的过度拟合。这也意味着我们的13个特征可能在GBM患者转录组亚型分类中具有重要意义。
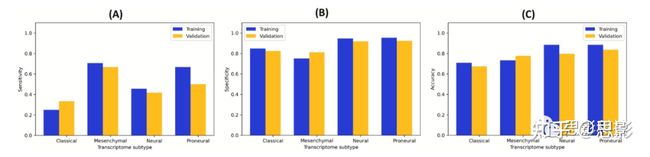
图5,训练集和验证集性能对比
4 讨论
医学成像特征被认为是诊断和评估癌症预后反应的基石。由于提取了数百种定量影像组学特征,包括CT、PET和MR扫描,许多疾病特征,特别是肿瘤学领域的疾病特征已经被揭示。最近,随着公共医疗数据集的日益开放[29],大大提高了基于影像组学的机器学习模型的预测性能,特别是GBM转录组亚型。在本研究中,通过对TCGA-GBM[30]数据集的研究,证明了多模式融合两级特征选择技术识别GBM亚型的能力。最终模型也在外部数据集(IvyGAP)[33]上进行了验证,获得了有价值的结果。
一般而言,许多特征选择技术已应用在基于影像组学的机器学习模型中,以分类GBM转录组亚型,如顺序正向特征选择[23]、个体预测测试[24]、空间点模式分析[25]或Mann–Whitney检验[27]。因此,本研究为应用另一种有效技术进行分类提供了证据。我们的13个特征可能有别于以前的方法,它们有助于在多分类中产生更优异的性能。此外,通过结合使用Spearman和F-score分析,我们的影像组学特征可靠且易于解释。
我们的研究还分析了不同机器学习模型在学习影像组学特征方面的效率。这项研究的结果(表3)表明,XGBoost优于其他方法来分类胶质瘤患者的转录组亚型。这一发现与之前的研究一致,其中XGBoost也是胶质母细胞瘤研究的最佳模型,如[42,45]。因此,本研究再次强调了集成学习(尤其是XGBoost)在影像组学中的重要性。以后的影像组学研究可以将其视为有效学习特征的首选。
基于影像组学的不同的GBM研究使用不同的患者队列,因此,准确地比较不同研究具有挑战性。然而,为了对我们的方法的有效性有一个相对的看法,我们还提供了我们的模型和以前关于相同转录组亚型分类的工作之间的比较结果。在GBM转录组亚型的分类方面,有一些已发表的研究具有良好的性能,如[23,26]。检索其性能结果以支持比较目的。例如,与[23]在相同TCIA数据集上的工作相比,我们的模型平均精度提高了约5%。关注个体亚型之间的详细性能结果,我们的模型在间充质、神经和前神经亚型中取得了比[26]更好的性能。通过比较发现,在相同和公平的比较水平上,我们的模型的性能比其他模型好一点。
此外,我们的13个放射组学特征的最佳集合可能会引起GBM研究的更多关注。该影像组学特征与XGBoost分类器相结合,在高性能分类转录组亚型方面具有潜力。另一个发现是,在我们包含13个特征的生物标志物集中,大多数来自纹理特征。这与先前基于影像组学的GBM模型的工作一致,如MGMT甲基化状态的预测[46,47]、IDH1突变和1p/19q编码缺失状态的预测[48,49]。此外,观察到小波变换(即GLSZM)主要出现在基本特征集中。因此,结合小波变换特征或其他高阶特征,计算模型在GBM患者中无创和术前分类转录组变得更加可能。
尽管这项研究取得了积极的结果,但也有必要审视这项研究的局限性。首先,为了提高研究质量,有必要增加样本量,以评估我们模型的泛化。然而,通过LOOCV多次重复训练,本研究以某种方式解决了这一局限性。此外,我们还发布了选定radiomics特征的详细信息;这将有助于在其他中心进一步研究中验证结果。第二,更新的GBM的TCGA分子亚型不包括神经亚型,神经亚型更可能是GBM肿瘤块以外的相邻脑组织。因此,基于转录组亚型的进一步研究可以排除TCGA-GBM项目中的神经亚型以避免数据不足。最后,如先前的影像组学研究[50]所示,影像组学特征的重复性因验证-再验证和图像配准而受到影响。因此,更重要的是,在应用影像组学分析之前,可以对异构数据执行图像归一化或标准化。
5 结论
通过对86例GBM患者数据集的研究,本研究探讨了两级特征选择和基于影像组学的XGBoost模型在GBM患者转录组亚型分类中的作用。通过将多分类作为单独的二元分类来解决。此后,我们发现对13个特征的特征选择分析有助于提高模型的预测性能和稳定性。使用13个特征作为输入的最终预测模型,四种亚型的准确率分别为70.9%、73.3%、88.4%和88.4%。我们基于人工智能的影像组学模型在外部验证数据集上也显示了显著的性能。这项研究表明,结合Spearman相关性、F-score和XGBoost的建模方法是GBM转录组亚型分类的一种有前景的方法。这一发现可能被重复,以增强进一步影像组学研究的预测性能。