【二叉树篇】速刷牛客TOP101 高效刷题指南
文章目录
- 23、BM23 二叉树的前序遍历
- 24、BM24 二叉树的中序遍历
- 25、BM25 二叉树的后序遍历
- 26、BM26 求二叉树的层序遍历
- 27、BM27 按之字形顺序打印二叉树
- 28、BM28 二叉树的最大深度
- 29、BM29 二叉树中和为某一值的路径(一)
- 30、BM30 二叉搜索树与双向链表
- 31、BM31 对称的二叉树
- 32、BM32 合并二叉树
- 33、BM33 二叉树的镜像
- 34、BM34 判断是不是二叉搜索树
- 35、BM35 判断是不是完全二叉树
- 36、BM36 判断是不是平衡二叉树
- 37、BM37 二叉搜索树的最近公共祖先
- 38、BM38 在二叉树中找到两个节点的最近公共祖先
- 39、BM39 序列化二叉树
- 40、BM40 重建二叉树
- 41、BM41 输出二叉树的右视图
23、BM23 二叉树的前序遍历

思路步骤:
- 前序遍历:遵循 根—>左—>右
- 首先需要一个List来存放遍历的节点值
- 用递归的方式遍历每个节点
- 将List中的节点转存到数组中返回
public class Solution {
public int[] preorderTraversal (TreeNode root) {
//前序遍历 遵循根--->左--->右
//创建一个集合来存储遍历的结点值
List<Integer> list = new ArrayList<>();
helper(root, list);
int[] res = new int[list.size()];
for (int i = 0; i < res.length; i++) {
//将集合中的元素转存到数组中
res[i] = list.get(i);
}
//将数组返回
return res;
}
private void helper(TreeNode node, List<Integer> list) {
if (node == null) {
return;
}
//存入结点
list.add(node.val);
//遍历左树
helper(node.left, list);
//遍历右树
helper(node.right, list);
}
}
24、BM24 二叉树的中序遍历

思路步骤:
什么是二叉树的中序遍历,简单来说就是“左根右”,展开来说就是对于一棵二叉树,我们优先访问它的左子树,等到左子树全部节点都访问完毕,再访问根节点,最后访问右子树。同时访问子树的时候,顺序也与访问整棵树相同。
可以理解为递归的子问题,根节点的左右子树访问方式与原本的树相同,可以看成一颗树进行中序遍历,因此可以用递归处理:
- 终止条件: 当子问题到达叶子节点后,后一个不管左右都是空,因此遇到空节点就返回。
- 返回值: 每次处理完子问题后,就是将子问题访问过的元素返回,依次存入了数组中。
- 本级任务: 每个子问题优先访问左子树的子问题,等到左子树的结果返回后,再访问自己的根节点,然后进入右子树。
public class Solution {
public int[] inorderTraversal (TreeNode root) {
// write code here
/**
递归法
*/
//中序遍历 遵循左--->根--->右
//创建一个集合来存储遍历的结点值
List<Integer> list = new ArrayList<>();
helper(root, list);
int[] res = new int[list.size()];
for (int i = 0; i < res.length; i++) {
//将集合中的元素转存到数组中
res[i] = list.get(i);
}
//将数组返回
return res;
}
private void helper(TreeNode node, List<Integer> list) {
if (node == null) {
return;
}
//遍历左树
helper(node.left, list);
//存入结点
list.add(node.val);
//遍历右树
helper(node.right, list);
}
}
25、BM25 二叉树的后序遍历

思路步骤:
- 一样的思路,顺序变了而已
- 先递归左右子树,返回结果后再访问自己的根节点
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型一维数组
*/
public int[] postorderTraversal (TreeNode root) {
// write code here
//后序遍历 遵循左--->右--->根
//创建一个集合来存储遍历的结点值
List<Integer> list = new ArrayList<>();
helper(root, list);
int[] res = new int[list.size()];
for (int i = 0; i < res.length; i++) {
//将集合中的元素转存到数组中
res[i] = list.get(i);
}
//将数组返回
return res;
}
private void helper(TreeNode node, List<Integer> list) {
//basecase
if (node == null) {
return;
}
helper(node.left, list);
helper(node.right, list);
list.add(node.val);
}
}
26、BM26 求二叉树的层序遍历
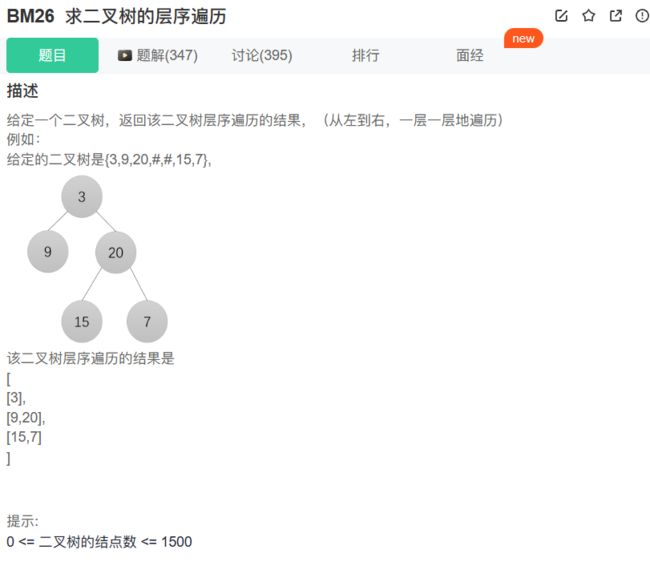
BFS广度优先遍历
思路:
二叉树的层次遍历就是按照从上到下每行,然后每行中从左到右依次遍历,得到的二叉树的元素值。对于层次遍历,我们通常会使用队列来辅助:
因为队列是一种先进先出的数据结构,我们依照它的性质,如果从左到右访问完一行节点,并在访问的时候依次把它们的子节点加入队列,那么它们的子节点也是从左到右的次序,且排在本行节点的后面,因此队列中出现的顺序正好也是从左到右,正好符合层次遍历的特点。
具体做法:
- step 1:首先判断二叉树是否为空,空树没有遍历结果。
- step 2:建立辅助队列,根节点首先进入队列。不管层次怎么访问,根节点一定是第一个,那它肯定排在队伍的最前面。
- step 3:每次进入一层,统计队列中元素的个数。因为每当访问完一层,下一层作为这一层的子节点,一定都加入队列,而再下一层还没有加入,因此此时队列中的元素个数就是这一层的元素个数。
- step 4:每次遍历这一层这么多的节点数,将其依次从队列中弹出,然后加入这一行的一维数组中,如果它们有子节点,依次加入队列排队等待访问。
- step 5:访问完这一层的元素后,将这个一维数组加入二维数组中,再访问下一层。
public class Solution {
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
//BFS 广度优先遍历
//通常与队列一起配合
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
//basecase
if (root == null) {
return res;
}
//定义一个队列
Queue<TreeNode> q = new LinkedList<>();
//将root 先丢到队列里
q.add(root);
//开启新的层
while (q.size() > 0) {
//维护一个size用来记录队列中元素的数量
//每次循环都更新size
int size = q.size();
//定义一个List用来记录二叉树的某一行
ArrayList<Integer> list = new ArrayList<>();
//当前层的元素
while (size > 0) {
//将队列中的元素取出来
TreeNode cur = q.poll();
//存到List
list.add(cur.val);
//判断取出的这个元素有没有左右孩子
if (cur.left != null) {
//将左孩子加到队列
q.add(cur.left);
}
if (cur.right != null) {
q.add(cur.right);
}
size--;
}
res.add(new ArrayList<>(list));
}
return res;
}
}
DFS深度优先遍历
思路:
既然二叉树的前序、中序、后序遍历都可以轻松用递归实现,树型结构本来就是递归喜欢的形式,那我们的层次遍历是不是也可以尝试用递归来试试呢?
按行遍历的关键是每一行的深度对应了它输出在二维数组中的深度,即深度可以与二维数组的下标对应,那我们可以在递归的访问每个节点的时候记录深度:
dfs(root, res, 0);
进入子节点则深度加1:
//递归左右时深度记得加1
dfs(node.left, res, level + 1);
dfs(node.right, res, level + 1);
每个节点值放入二维数组相应行。
res.get(level).add(node.val);
因此可以用递归实现:
- 终止条件: 遍历到了空节点,就不再继续,返回。
- 返回值: 将加入的输出数组中的结果往上返回。
- 本级任务: 处理按照上述思路处理非空节点,并进入该节点的子节点作为子问题。
具体做法:
- step 1:首先判断二叉树是否为空,空树没有遍历结果。
- step 2:使用递归进行层次遍历输出,每次递归记录当前二叉树的深度,每当遍历到一个节点,如果为空直接返回。
- step 3:如果遍历的节点不为空,输出二维数组中一维数组的个数(即代表了输出的行数)小于深度,说明这个节点应该是新的一层,我们在二维数组中增加一个一维数组,然后再加入二叉树元素。
- step 4:如果不是step 3的情况说明这个深度我们已经有了数组,直接根据深度作为下标取出数组,将元素加在最后就可以了。
- step 5:处理完这个节点,再依次递归进入左右节点,同时深度增加。因为我们进入递归的时候是先左后右,那么遍历的时候也是先左后右,正好是层次遍历的顺序。
public class Solution {
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
//DFS 深度优先遍历
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
//basecase
if (root == null) {
return res;
}
dfs(root, res, 0);
return res;
}
private void dfs(TreeNode node, ArrayList<ArrayList<Integer>> res, int level) {
//递归退出的条件
if (node == null) {
return;
}
//当前层级大于数组大小
if (level > res.size() - 1) {
//就需要加一个空的数组,才能存放元素
res.add(new ArrayList<>());
}
res.get(level).add(node.val);
if (node.left != null) {
dfs(node.left, res, level + 1);
}
if (node.right != null) {
dfs(node.right, res, level + 1);
}
}
}
27、BM27 按之字形顺序打印二叉树

思路:
按照层次遍历按层打印二叉树的方式,每层分开打印,然后对于每一层利用flag标记,第一层为false,之后每到一层取反一次,如果该层的flag为true,则记录的数组整个反转即可。
//奇数行反转,偶数行不反转
if(flag)
reverse(row.begin(), row.end());
但是难点在于如何每层分开存储,从哪里知晓分开的时机?在层次遍历的时候,我们通常会借助队列(queue),事实上,队列中的值大有玄机,让我们一起来看看:当根节点进入队列时,队列长度为1,第一层节点数也为1;若是根节点有两个子节点,push进队列后,队列长度为2,第二层节点数也为2;若是根节点一个子节点,push进队列后,队列长度为为1,第二层节点数也为1。由此,我们可知,每层的节点数等于进入该层时队列长度,因为刚进入该层时,这一层每个节点都会push进队列,而上一层的节点都出去了。
int n = temp.size();
for(int i = 0; i < n; i++){
//访问一层
}
具体做法:
- step 1:首先判断二叉树是否为空,空树没有打印结果。
- step 2:建立辅助队列,根节点首先进入队列。不管层次怎么访问,根节点一定是第一个,那它肯定排在队伍的最前面,初始化flag变量。
- step 3:每次进入一层,统计队列中元素的个数,更改flag变量的值。因为每当访问完一层,下一层作为这一层的子节点,一定都加入队列,而再下一层还没有加入,因此此时队列中的元素个数就是这一层的元素个数。
- step 4:每次遍历这一层这么多的节点数,将其依次从队列中弹出,然后加入这一行的一维数组中,如果它们有子节点,依次加入队列排队等待访问。
- step 5:访问完这一层的元素后,根据flag变量决定将这个一维数组直接加入二维数组中还是反转后再加入,然后再访问下一层。
public class Solution {
public ArrayList<ArrayList<Integer>> Print (TreeNode pRoot) {
// write code here
TreeNode head = pRoot;
ArrayList<ArrayList<Integer>> res = new ArrayList<ArrayList<Integer>>();
if(head == null){
//返回空list
return res;
}
//队列存储,进行层次遍历
Queue<TreeNode> temp = new LinkedList<TreeNode>();
//先把根节点加到队列里面
temp.offer(head);
//定义一个变量存放队列中取出来节点
TreeNode p;
//定义一个flag变量
boolean flag = true;
while(!temp.isEmpty()){
//定义一个数组记录二叉树的某一行
ArrayList<Integer> row = new ArrayList<>();
//维护一个变量记录队列元素的个数
int n = temp.size();
//奇数行反转,偶数行不反转
flag = !flag;
//因为首先进入的都是根节点,所以每层节点多少,队列大小就是多少
for(int i = 0; i < n; i++){
//将队列中的节点取出来
p = temp.poll();
//加到存放行的列表
row.add(p.val);
//若是左右孩子存在,则存入左右孩子作为下一个层次
if(p.left != null){
temp.offer(p.left);
}
if(p.right != null){
temp.offer(p.right);
}
}
//奇数行反转,偶数行不反转
if(flag){
Collections.reverse(row);
}
res.add(row);
}
return res;
}
}
28、BM28 二叉树的最大深度

方法一:递归
二叉树的递归,则是将某个节点的左子树、右子树看成一颗完整的树,那么对于子树的访问或者操作就是对于原树的访问或者操作的子问题,因此可以自我调用函数不断进入子树。
思路:
最大深度是所有叶子节点的深度的最大值,深度是指树的根节点到任一叶子节点路径上节点的数量,因此从根节点每次往下一层深度就会加1。因此二叉树的深度就等于根节点这个1层加上左子树和右子树深度的最大值,而每个子树我们都可以看成一个根节点,继续用上述方法求的深度,于是我们可以对这个问题划为子问题,利用递归来解决:
- 终止条件: 当进入叶子节点后,再进入子节点,即为空,没有深度可言,返回0.
- 返回值: 每一级按照上述公式,返回两边子树深度的最大值加上本级的深度,即加1.
- 本级任务: 每一级的任务就是进入左右子树,求左右子树的深度。
具体做法:
- step 1:对于每个节点,若是不为空才能累计一次深度,若是为空,返回深度为0.
- step 2:递归分别计算左子树与右子树的深度。
- step 3:当前深度为两个子树深度较大值再加1。
import java.util.*;
public class Solution {
public int maxDepth (TreeNode root) {
//空节点没有深度
if(root == null)
return 0;
//返回子树深度+1
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
方法二:队列
队列是一种仅支持在表尾进行插入操作、在表头进行删除操作的线性表,插入端称为队尾,删除端称为队首,因整体类似排队的队伍而得名。它满足先进先出的性质,元素入队即将新元素加在队列的尾,元素出队即将队首元素取出,它后一个作为新的队首。
思路:
既然是统计二叉树的最大深度,除了根据路径到达从根节点到达最远的叶子节点以外,我们还可以分层统计。对于一棵二叉树而言,必然是一层一层的,那一层就是一个深度,有的层可能会很多节点,有的层如根节点或者最远的叶子节点,只有一个节点,但是不管多少个节点,它们都是一层。因此我们可以使用层次遍历,二叉树的层次遍历就是从上到下按层遍历,每层从左到右,我们只要每层统计层数即是深度。
具体做法:
- step 1:既然是层次遍历,我们遍历完一层要怎么进入下一层,可以用队列记录这一层中节点的子节点。队列类似栈,只不过是一个先进先出的数据结构,可以理解为我们平时的食堂打饭的排队。因为每层都是按照从左到右开始访问的,那自然记录的子节点也是从左到右,那我们从队列出来的时候也是从左到右,完美契合。
- step 2:在刚刚进入某一层的时候,队列中的元素个数就是当前层的节点数。比如第一层,根节点先入队,队列中只有一个节点,对应第一层只有一个节点,第一层访问结束后,它的子节点刚好都加入了队列,此时队列中的元素个数就是下一层的节点数。因此遍历的时候,每层开始统计该层个数,然后遍历相应节点数,精准进入下一层。
- step 3:遍历完一层就可以节点深度就可以加1,直到遍历结束,即可得到最大深度。
public class Solution {
public int maxDepth (TreeNode root) {
//BFS
// write code here
if (root == null) {
return 0;
}
//创建一个队列
Queue<TreeNode> q = new LinkedList<>();
//将根节点加入到队列
q.offer(root);
//维护一个res记录深度
int res = 0;
//如果这个队列不等于空
while (!q.isEmpty()) {
//每一层的个数
int size = q.size();
while (size-- > 0) {
//如果这一层的个数大于0,就取出来
TreeNode cur = q.poll();
//取出来之后看这个节点是否有左右孩子
if (cur.left != null)
//加入到队列
q.offer(cur.left);
if (cur.right != null)
q.offer(cur.right);
}
//每一层的个数++
res++;
}
return res;
}
}
29、BM29 二叉树中和为某一值的路径(一)

思路步骤:
既然是检查从根到叶子有没有一条等于目标值的路径,那肯定需要从根节点遍历到叶子,我们可以在根节点每次往下一层的时候,将sum减去节点值,最后检查是否完整等于0. 而遍历的方法我们可以选取二叉树常用的递归前序遍历,因为每次进入一个子节点,更新sum值以后,相当于对子树查找有没有等于新目标值的路径,因此这就是子问题,递归的三段式为:
- 终止条件: 每当遇到节点为空,意味着过了叶子节点,返回。每当检查到某个节点没有子节点,它就是叶子节点,此时sum减去叶子节点值刚好为0,说明找到了路径。
- 返回值: 将子问题中是否有符合新目标值的路径层层往上返回。
- 本级任务: 每一级需要检查是否到了叶子节点,如果没有则递归地进入子节点,同时更新sum值减掉本层的节点值。
具体做法:
- step 1:每次检查遍历到的节点是否为空节点,空节点就没有路径。
- step 2:再检查遍历到是否为叶子节点,且当前sum值等于节点值,说明可以刚好找到。
- step 3:检查左右子节点是否可以有完成路径的,如果任意一条路径可以都返回true,因此这里选用两个子节点递归的或。
public class Solution {
public boolean hasPathSum (TreeNode root, int sum) {
// write code here
//如果根节点为空,或者叶子节点也遍历完了也没找到这样的结果,就返回false
if (root == null)
return false;
//如果到叶子节点了,并且剩余值等于叶子节点的值,说明找到了这样的结果,直接返回true
if (root.left == null && root.right == null && sum - root.val == 0)
return true;
//分别沿着左右子节点走下去,然后顺便把当前节点的值减掉,左右子节点只要有一个返回true,
//说明存在这样的结果
return hasPathSum(root.left, sum - root.val) ||
hasPathSum(root.right, sum - root.val);
}
}
30、BM30 二叉搜索树与双向链表

思路:
二叉搜索树最左端的元素一定最小,最右端的元素一定最大,符合“左中右”的特性,因此二叉搜索树的中序遍历就是一个递增序列,我们只要对它中序遍历就可以组装称为递增双向链表。
具体做法:
- step 1:创建两个指针,一个指向题目中要求的链表头(head),一个指向当前遍历的前一节点(pre)。
- step 2:首先递归到最左,初始化head与pre。
- step 3:然后处理中间根节点,依次连接pre与当前节点,连接后更新pre为当前节点。
- step 4:最后递归进入右子树,继续处理。
- step 5:递归出口即是节点为空则返回。
public class Solution {
//返回的第一个指针,即为最小值,先定为null
TreeNode head = null;
//中序遍历当前值的上一位,初值为最小值,先定为null
TreeNode pre = null;
public TreeNode Convert(TreeNode pRootOfTree) {
if (pRootOfTree == null) {
return null;
}
//首先递归到最左最小值
Convert(pRootOfTree.left);
//找到最小值,然后初始化head和pre
if (pre == null) {
head = pRootOfTree;
pre = pRootOfTree;
}
//当前节点与上一节点建立连接,将pre设置为当前值
else {
pre.right = pRootOfTree;
pRootOfTree.left = pre;
pre = pRootOfTree;
}
Convert(pRootOfTree.right);
return head;
}
}
31、BM31 对称的二叉树
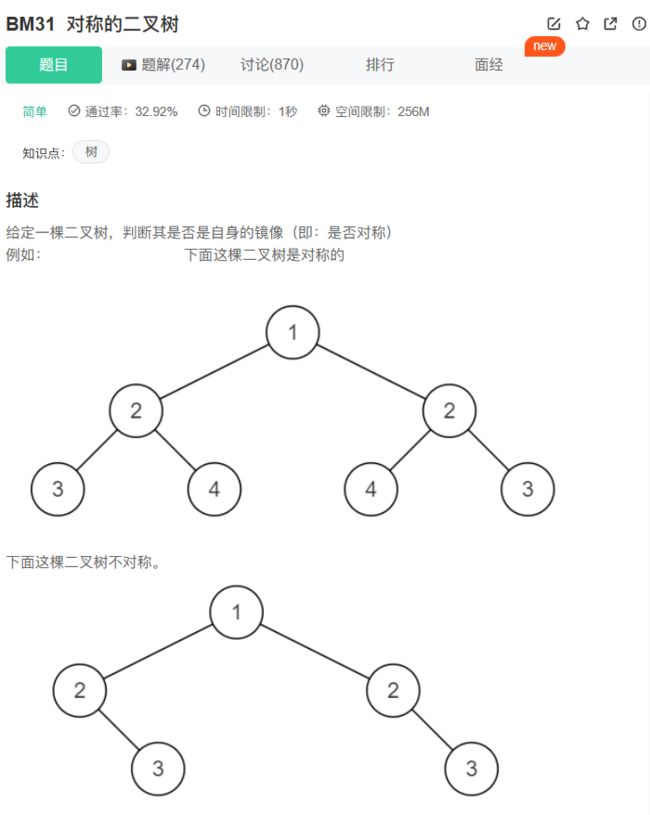
思路:
前序遍历的时候我们采用的是“根左右”的遍历次序,如果这棵二叉树是对称的,即相应的左右节点交换位置完全没有问题,那我们是不是可以尝试“根右左”遍历,按照轴对称图像的性质,这两种次序的遍历结果应该是一样的。
不同的方式遍历两次,将结果拿出来比较看起来是一种可行的方法,但也仅仅可行,太过于麻烦。我们不如在遍历的过程就结果比较了。而遍历方式依据前序递归可以使用递归:
- 终止条件: 当进入子问题的两个节点都为空,说明都到了叶子节点,且是同步的,因此结束本次子问题,返回true;当进入子问题的两个节点只有一个为空,或是元素值不相等,说明这里的对称不匹配,同样结束本次子问题,返回false。
- 返回值: 每一级将子问题是否匹配的结果往上传递。
- 本级任务: 每个子问题,需要按照上述思路,“根左右”走左边的时候“根右左”走右边,“根左右”走右边的时候“根右左”走左边,一起进入子问题,需要两边都是匹配才能对称。
具体做法:
- step 1:两种方向的前序遍历,同步过程中的当前两个节点,同为空,属于对称的范畴。
- step 2:当前两个节点只有一个为空或者节点值不相等,已经不是对称的二叉树了。
- step 3:第一个节点的左子树与第二个节点的右子树同步递归对比,第一个节点的右子树与第二个节点的左子树同步递归比较。
public class Solution {
public boolean isSymmetrical (TreeNode pRoot) {
return recursion(pRoot, pRoot);
}
public boolean recursion(TreeNode root1, TreeNode root2) {
//可以两个都为空,
if (root1 == null && root2 == null) {
return true;
}
//只有一个为空或者节点值不同,一定不对称
if (root1 == null || root2 == null || root1.val != root2.val) {
return false;
}
//每层对应的节点进入递归比较
return recursion(root1.left, root2.right) && recursion(root1.right, root2.left);
}
}
32、BM32 合并二叉树

思路:
要将一棵二叉树的节点与另一棵二叉树相加合并,肯定需要遍历两棵二叉树,那我们可以考虑同步遍历两棵二叉树,这样就可以将每次遍历到的值相加在一起。遍历的方式有多种,这里推荐前序递归遍历。
具体做法:
- step 1:首先判断t1与t2是否为空,若为则用另一个代替,若都为空,返回的值也是空。
- step 2:然后依据前序遍历的特点,优先访问根节点,将两个根点的值相加创建到新树中。
- step 3:两棵树再依次同步进入左子树和右子树。
public class Solution {
public TreeNode mergeTrees (TreeNode t1, TreeNode t2) {
// write code here
//若只有一个节点返回另一个,两个都为null自然返回null
if(t1 == null){
return t2;
}
if(t2 == null){
return t1;
}
//根左右的方式递归
TreeNode head = new TreeNode(t1.val + t2.val);
head.left = mergeTrees(t1.left, t2.left);
head.right = mergeTrees(t1.right,t2.right);
return head;
}
}
33、BM33 二叉树的镜像

解题思路:
根据二叉树镜像的定义,考虑递归遍历(dfs)二叉树,交换每个节点的左 / 右子节点,即可生成二叉树的镜像。
解题步骤:
1、特判:如果pRoot为空,返回空
2、交换左右子树
3、把pRoot的左子树放到Mirror中镜像一下
4、把pRoot的右子树放到Mirror中镜像一下
5、返回根节点root
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
public TreeNode Mirror (TreeNode pRoot) {
// write code here
if(pRoot == null){
return pRoot;
}
//左右子树交换
TreeNode temp = pRoot.left;
pRoot.left = pRoot.right;
pRoot.right = temp;
//递归左右子树
Mirror(pRoot.left);
Mirror(pRoot.right);
return pRoot;
}
}
34、BM34 判断是不是二叉搜索树
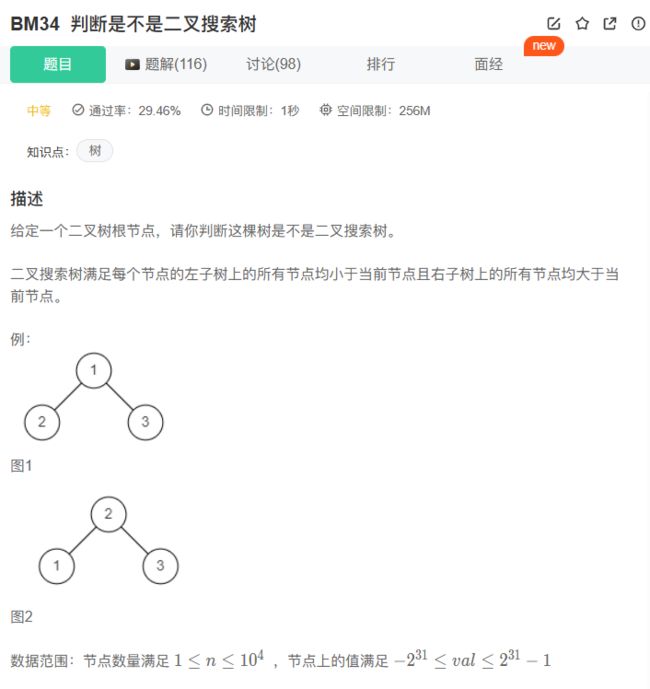
思路:
二叉搜索树的特性就是中序遍历是递增序。既然是判断是否是二叉搜索树,那我们可以使用中序递归遍历。只要之前的节点是二叉树搜索树,那么如果当前的节点小于上一个节点值那么就可以向下判断。只不过在过程中我们要求反退出。比如一个链表1->2->3->4,只要for循环遍历如果中间有不是递增的直接返回false即可。
if(root.val < pre)
return false;
具体做法:
- step 1:首先递归到最左,初始化maxLeft与pre。
- step 2:然后往后遍历整棵树,依次连接pre与当前节点,并更新pre。
- step 3:左子树如果不是二叉搜索树返回false。
- step 4:判断当前节点是不是小于前置节点,更新前置节点。
- step 5:最后由右子树的后面节点决定。
public class Solution {
int pre = Integer.MIN_VALUE;
public boolean isValidBST (TreeNode root) {
// write code here
//中序遍历
if(root == null){
return true;
}
//先进入左子树
if(!isValidBST(root.left)){
return false;
}
if(root.val < pre){
return false;
}
//更新最值
pre = root.val;
//再进入右子树
return isValidBST(root.right);
}
}
35、BM35 判断是不是完全二叉树
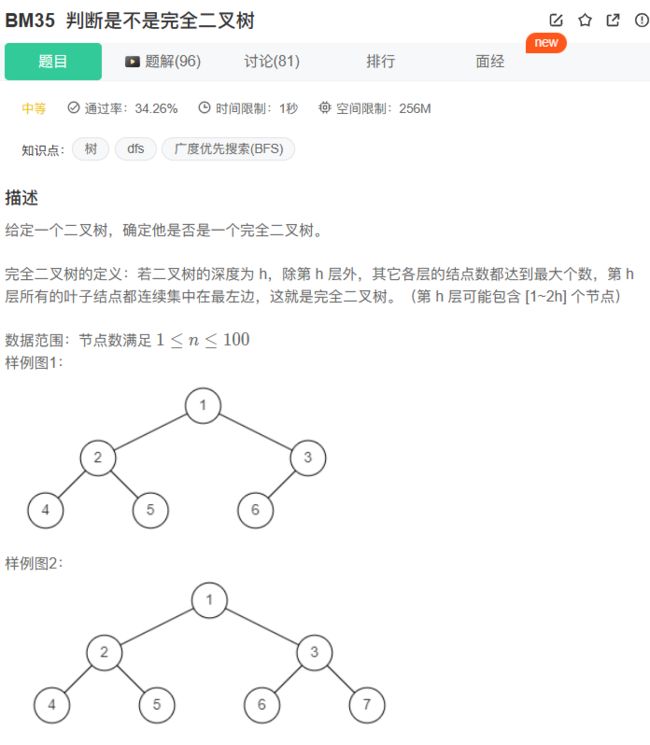
思路:
对完全二叉树最重要的定义就是叶子节点只能出现在最下层和次下层,所以我们想到可以使用队列辅助进行层次遍历——从上到下遍历所有层,每层从左到右,只有次下层和最下层才有叶子节点,其他层出现叶子节点就意味着不是完全二叉树。
具体做法:
- step 1:先判断空树一定是完全二叉树。
- step 2:初始化一个队列辅助层次遍历,将根节点加入。
- step 3:逐渐从队列中弹出元素访问节点,如果遇到某个节点为空,进行标记,代表到了完全二叉树的最下层,若是后续还有访问,则说明提前出现了叶子节点,不符合完全二叉树的性质。
- step 4:否则,继续加入左右子节点进入队列排队,等待访问。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return bool布尔型
*/
public boolean isCompleteTree (TreeNode root) {
// write code here
//空树一定是完全二叉树
if(root == null){
return true;
}
//辅助队列
Queue<TreeNode> q = new LinkedList<>();
//根节点加入队列
q.offer(root);
//从队列中取出的节点
TreeNode cur;
//定义一个首次出现的标记位
boolean notComplete = false;
while(!q.isEmpty()){
cur = q.poll();
//标记第一次遇到空节点
if(cur == null){
notComplete = true;
//退出
continue;
}
//后续访问已经遇到空节点了
if(notComplete){
return false;
}
q.offer(cur.left);
q.offer(cur.right);
}
return true;
}
}
36、BM36 判断是不是平衡二叉树

思路:
从题中给出的有效信息:
- 左右两个子树的高度差的绝对值不超过1
- 左右两个子树都是一棵平衡二叉树
故此 首先想到的方法是使用递归的方式判断子节点的状态
具体做法:
如果一个节点的左右子节点都是平衡的,并且左右子节点的深度差不超过 1,则可以确定这个节点就是一颗平衡二叉树。
public class Solution {
public boolean IsBalanced_Solution (TreeNode pRoot) {
// write code here
//递归
if(pRoot == null){
return true;
}
//判断左右子树是否符合规则,且深度不能超过2
return IsBalanced_Solution(pRoot.left) && IsBalanced_Solution(pRoot.right) && Math.abs(deep(pRoot.left) - deep(pRoot.right))< 2;
}
public int deep(TreeNode root){
if(root == null){
return 0;
}
return Math.max(deep(root.left), deep(root.right)) + 1;
}
}
37、BM37 二叉搜索树的最近公共祖先

思路:
我们可以利用二叉搜索树的性质:对于某一个节点若是p与q都小于等于这个这个节点值,说明p、q都在这个节点的左子树,而最近的公共祖先也一定在这个节点的左子树;若是p与q都大于等于这个节点,说明p、q都在这个节点的右子树,而最近的公共祖先也一定在这个节点的右子树。而若是对于某个节点,p与q的值一个大于等于节点值,一个小于等于节点值,说明它们分布在该节点的两边,而这个节点就是最近的公共祖先,因此从上到下的其他祖先都将这个两个节点放到同一子树,只有最近公共祖先会将它们放入不同的子树,每次进入一个子树又回到刚刚的问题,因此可以使用递归。
具体做法:
- step 1:首先检查空节点,空树没有公共祖先。
- step 2:对于某个节点,比较与p、q的大小,若p、q在该节点两边说明这就是最近公共祖先。
- step 3:如果p、q都在该节点的左边,则递归进入左子树。
- step 4:如果p、q都在该节点的右边,则递归进入右子树。
public class Solution {
public int lowestCommonAncestor (TreeNode root, int p, int q) {
// write code here
//递归
//空树找不到公共祖先
if(root == null){
return -1;
}
//pq在该节点两边说明该节点就是最近公共祖先
if((p >= root.val && q <= root.val) || (p <= root.val && q >= root.val)){
return root.val;
}
//pq都在该节点的左边
else if(p <= root.val && q <= root.val){
//进入左子树
return lowestCommonAncestor(root.left, p , q);
}//pq都在该节点的右侧
else{
//进入右子树
return lowestCommonAncestor(root.right, p, q);
}
}
}
38、BM38 在二叉树中找到两个节点的最近公共祖先

思路:
我们可以讨论几种情况:
- step 1:如果o1和o2中的任一个和root匹配,那么root就是最近公共祖先。
- step 2:如果都不匹配,则分别递归左、右子树。
- step 3:如果有一个节点出现在左子树,并且另一个节点出现在右子树,则root就是最近公共祖先.
- step 4:如果两个节点都出现在左子树,则说明最低公共祖先在左子树中,否则在右子树。
- step 5:继续递归左、右子树,直到遇到step1或者step3的情况。
public class Solution {
public int lowestCommonAncestor (TreeNode root, int o1, int o2) {
// write code here
//该子树为空,返回-1
if(root == null){
return -1;
}
//该节点是其中某一个节点
if(root.val == o1 || root.val == o2){
return root.val;
}
//左子树寻找公共祖先
int left = lowestCommonAncestor(root.left, o1, o2);
//右子树寻找公共祖先
int right = lowestCommonAncestor(root.right, o1, o2);
//左子树中没找到,则在右子树中
if(left == -1){
return right;
}
//右子树没有找到,则在左子树中
if(right == -1){
return left;
}
//否则是当前节点
return root.val;
}
}
39、BM39 序列化二叉树

思路:
序列化即将二叉树的节点值取出,放入一个字符串中,我们可以按照前序遍历的思路,遍历二叉树每个节点,并将节点值存储在字符串中,我们用‘#’表示空节点,用‘!'表示节点与节点之间的分割。
反序列化即根据给定的字符串,将二叉树重建,因为字符串中的顺序是前序遍历,因此我们重建的时候也是前序遍历,即可还原。
具体做法:
- step 1:优先处理序列化,首先空树直接返回“#”,然后调用SerializeFunction函数前序递归遍历二叉树。
SerializeFunction(root, res);
- step 2:SerializeFunction函数负责前序递归,根据“根左右”的访问次序,优先访问根节点,遇到空节点在字符串中添加‘#’,遇到非空节点,添加相应节点数字和‘!’,然后依次递归进入左子树,右子树。
//根节点
str.append(root.val).append('!');
//左子树
SerializeFunction(root.left, str);
//右子树
SerializeFunction(root.right, str);
- step 3:创建全局变量index表示序列中的下标(C++中直接指针完成)。
- step 4:再处理反序列化,读入字符串,如果字符串直接为"#",就是空树,否则还是调用DeserializeFunction函数前序递归建树。
TreeNode res = DeserializeFunction(str);
- step 5:DeserializeFunction函数负责前序递归构建树,遇到‘#’则是空节点,遇到数字则根据感叹号分割,将字符串转换为数字后加入新创建的节点中,依据“根左右”,创建完根节点,然后依次递归进入左子树、右子树创建新节点。
TreeNode root = new TreeNode(val);
......
//反序列化与序列化一致,都是前序
root.left = DeserializeFunction(str);
root.right = DeserializeFunction(str);
import java.util.*;
public class Solution {
//序列的下标
public int index = 0;
//处理序列化的功能函数(递归)
private void SerializeFunction(TreeNode root, StringBuilder str) {
//如果节点为空,表示左子节点或右子节点为空,用#表示
if (root == null) {
str.append('#');
return;
}
//根节点
str.append(root.val).append('!');
//左子树
SerializeFunction(root.left, str);
//右子树
SerializeFunction(root.right, str);
}
public String Serialize(TreeNode root) {
//处理空树
if (root == null)
return "#";
StringBuilder res = new StringBuilder();
SerializeFunction(root, res);
//把str转换成char
return res.toString();
}
//处理反序列化的功能函数(递归)
private TreeNode DeserializeFunction(String str) {
//到达叶节点时,构建完毕,返回继续构建父节点
//空节点
if (str.charAt(index) == '#') {
index++;
return null;
}
//数字转换
int val = 0;
//遇到分隔符或者结尾
while (str.charAt(index) != '!' && index != str.length()) {
val = val * 10 + ((str.charAt(index)) - '0');
index++;
}
TreeNode root = new TreeNode(val);
//序列到底了,构建完成
if (index == str.length())
return root;
else
index++;
//反序列化与序列化一致,都是前序
root.left = DeserializeFunction(str);
root.right = DeserializeFunction(str);
return root;
}
public TreeNode Deserialize(String str) {
//空序列对应空树
if (str == "#")
return null;
TreeNode res = DeserializeFunction(str);
return res;
}
}
40、BM40 重建二叉树

思路:
对于二叉树的前序遍历,我们知道序列的第一个元素必定是根节点的值,因为序列没有重复的元素,因此中序遍历中可以找到相同的这个元素,而我们又知道中序遍历中根节点将二叉树分成了左右子树两个部分
具体做法:
- step 1:先根据前序遍历第一个点建立根节点。
- step 2:然后遍历中序遍历找到根节点在数组中的位置。
- step 3:再按照子树的节点数将两个遍历的序列分割成子数组,将子数组送入函数建立子树。
- step 4:直到子树的序列长度为0,结束递归。
public class Solution {
public TreeNode reConstructBinaryTree (int[] pre, int[] vin) {
// write code here
int n = pre.length;
int m = vin.length;
//每个遍历都不能为0
if (n == 0 || m == 0) {
return null;
}
//构建根节点
TreeNode root = new TreeNode(pre[0]);
for (int i = 0; i < m; i++) {
//找到中序遍历中的前序第一个元素
if (pre[0] == vin[i]) {
//构建左子树
root.left = reConstructBinaryTree(Arrays.copyOfRange(pre, 1, i + 1),
Arrays.copyOfRange(vin, 0, i));
//构建右子树
root.right = reConstructBinaryTree(Arrays.copyOfRange(pre, i + 1, pre.length),
Arrays.copyOfRange(vin, i + 1, vin.length));
break;
}
}
return root;
}
}
41、BM41 输出二叉树的右视图

思路:
首先呢根据上一题的建树思路,拿到树;然后采用层序遍历的方式 + 辅助队列,最后返回结果
具体做法:
-
step 1:首先检查树是否为空,为空就不打印。
-
step 2:建立队列辅助层次遍历,根节点先进队。
-
step 3:用一个size变量,每次进入一层的时候记录当前队列大小,等到size为0时,便到了最右边,记录下该节点元素。
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 求二叉树的右视图
* @param preOrder int整型一维数组 先序遍历
* @param inOrder int整型一维数组 中序遍历
* @return int整型一维数组
*/
public int[] solve (int[] preOrder, int[] inOrder) {
// write code here
//层次遍历
//先拿到重建的二叉树
TreeNode tree = reConstructBinaryTree(preOrder, inOrder);
if (tree == null) {
return new int[] {};
}
Queue<TreeNode> q = new LinkedList<>();
q.add(tree);
List<Integer> res = new ArrayList<>();
while (!q.isEmpty()) {
int size = q.size();
for (int i = 0; i < size; ++i) {
//取出来de节点
TreeNode cur = q.poll();
//加入到结果集中
//这里是关键,将每一层的最后一个元素加入到res中
if (i == size - 1) {
res.add(cur.val);
}
//看当前节点有没有左右孩子,有的话加入到队列
if (cur.left != null) {
q.offer((cur.left));
}
if (cur.right != null) {
q.offer(cur.right);
}
}
}
//封装右视图
int[] result = new int[res.size()];
for (int i = 0; i < res.size(); i++) {
result[i] = res.get(i);
}
return result;
}
//重建二叉树
public TreeNode reConstructBinaryTree (int[] pre, int[] vin) {
// write code here
int n = pre.length;
int m = vin.length;
//每个遍历都不能为0
if (n == 0 || m == 0) {
return null;
}
//构建根节点
TreeNode root = new TreeNode(pre[0]);
for (int i = 0; i < m; i++) {
//找到中序遍历中的前序第一个元素
if (pre[0] == vin[i]) {
//构建左子树
root.left = reConstructBinaryTree(Arrays.copyOfRange(pre, 1, i + 1),
Arrays.copyOfRange(vin, 0, i));
//构建右子树
root.right = reConstructBinaryTree(Arrays.copyOfRange(pre, i + 1, pre.length),
Arrays.copyOfRange(vin, i + 1, vin.length));
break;
}
}
return root;
}
}