开源分布式存储系统(HDFS、Ceph)架构分析
文章目录
- 中间控制节点架构-HDFS
-
- NameNode节点分析
- DataNode节点分析
- SecondNameNode节点分析
- Client分析
- 完全无中心架构-Ceph
-
- Ceph Monitor分析
- Ceph OSD分析
- Ceph Manager分析
- Ceph Clients分析
- 小结
-
- HDFS
-
- 优点
- 缺点
- Ceph
-
- 优点
- 缺点
- 参考
中间控制节点架构-HDFS
以HDFS( Hadoop Distribution File System )为代表的架构是中间控制节点架构的代表。
HDFS分布式文件系统是被设计成主从式的一种架构,集群中主要由客户端、名称节点NameNode、数据节点DataNode 和第二名称节点SecondNameNode组成。其中名称节点相当于分布式文件系统的管理者,主要用于管理文件系统命名空间及对整个集群进行控制等功能,数据节点则是文件实际存储的基本单元并在NameNode的控制下进行数据的读写和出错处理等基本操作,SecondNameNode则是用于备份NameNode的系统信息文件增强了集群抵抗单点失效的能力,客户端主要负责与NameNode与DataNode之间的通信,访问HDFS文件系统对文件进行增删查改等操作,HDFS集群中通常会包括一个NameNode节点与一个SecondNameNode节点,数据节点则会根据集群规模不同有所不同,一般的集群会有几十或着几百个数据节点规模大的甚至可以达到上千个,它的基本架构图如下图所示:
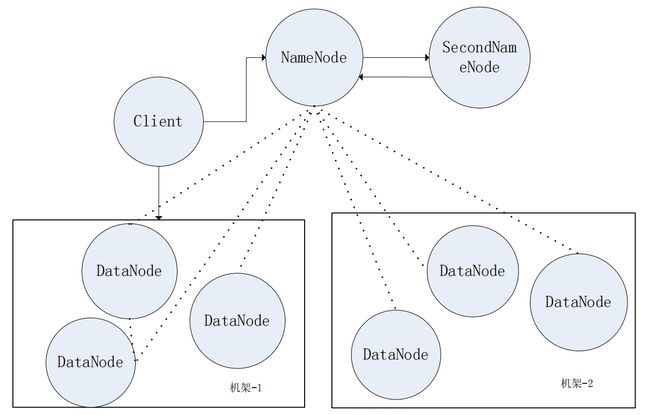
在HDFS系统中,通常会有一个NameNode、一个SecondNameNode、多个DataNode和多个HDFS Client。各个结点都会以守护进程的方式运行在以网络分布的不同服务器上。其中,NameNode相当于集群的管理者,DataNode是集群的基本存储单元,客户端用于访问HDFS,SecondNameNode会定期合并NameNode的元数据信息。
NameNode节点分析
NameNode的作用:
- 保存文件的元数据信息。NameNode主要负责存储文件系统的命名空间元数据,它将决定数据块映射到哪个DataNode上。
- 通过心跳机制检测DataNode的运行状态。NameNode启动之后将运行一个监听DataNode消息的进程,在DataNode运行之后它将会连接NameNode并会定期的向NameNode发送一个HeartBeat(即心跳)报告,将运行状态信息发送给NameNode,NameNode将根据这些信息来确定集群中的机器运行状态和数据块的分布状态,发送的时间默认是20分钟当超过这个时间没有接收到节点的信息时则认为该节点出现了故障。
NameNode是整个HDFS架构中最为核心的部分,它维护了整个文件系统的文件目录树和文件、目录的元数据信息与文件数据快索引,这些信息以两种形式存储在NameNode的本地文件系统中:一种是命名空间镜像FSImage(即文件系统镜像),另一种是EditLog(即命名空间的编辑日志)。
DataNode节点分析
DataNode的作用:
- 主要负责数据块的实际复制与存储。
- 定期向NameNode节点汇报自身运行状态。
每个数据结点都会运行一个守护进程,它主要负责将HDFS中的数据块写入到本地文件系统中的实际物理文件中和从这些文件中读取数据块。在客户端要对文件内容进行操作时,先由NameNode节点通知客户端每个数据块存储在哪个数据结点上,然后客户端直接与DataNode上的守护进程进行通信来进行数据块的读写操作。
DataNode在本地文件中主要保存了数据块与数据块元文件,其中数据块元文件存储的是数据块的校检信息,DataNode在运行之后,将会定期的对数据块文件进行扫描并将计算出的校检信息与数据块元文件进行比较,如果出现不符则认为数据块已经损坏需要进行恢复,数据块的恢复将由BadBlockReport机制实现,DataNode将信息上报给NameNode,NameNode则将数据块信息记录到恢复队列中并在之后通知其它DataNode进行失效数据块的复制,这样就保障了每一个数据块都有规定的副本数,提高了系统的可靠性。
HDFS文件系统中默认的副本数量是3个,数据块的3个副本分布于不同的DataNode上,当这些数据节点上的任意一个崩溃或者不能网络进行访问时可以通过其它节点来进行文件的操作,名称节点的元数据与数据节点上的数据块由下图所示:

SecondNameNode节点分析
SecondNameNode的作用:
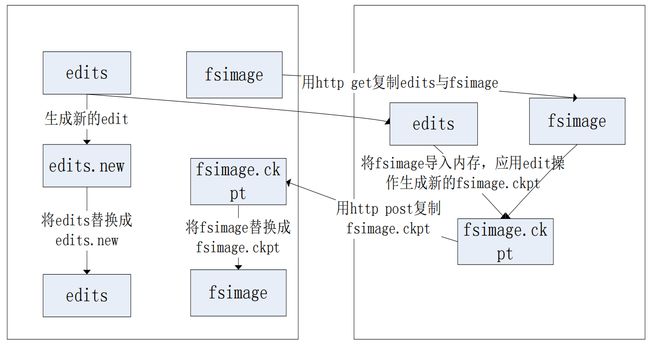
- SecondNameNode在HDFS中的作用是定期和NameNode通信来备份NameNode中的FSImage、EditLog等系统文件,这样就保障了NameNode在发生故障时整个系统命名空间和元数据信息的完整性。
SecondNameNode与名称节点NameNode最大的区别就是它不接受和记录HDFS的任何实时变化,它只是根据系统配置的间隔不断地获得HDFS中某一时间点的命名空间的镜像与编辑日志,并将其合并成一个新的命名空间镜像,这个新的镜像文件会上传到NameNode上替换先前的的命名空间镜像并清空日志文件,这样SecondNameNode为NameNode提供了一个简单的Checkpoint(即检查点)机制从而避免了集群运行时间过长编辑日志过大导致的NameNode启动时间过长的问题。
Client分析
客户端的主要工作就是和NameNode与DataNode进行交互从而进行文件的基本操作,HDFS文件系统提供了多种的客户端交互手段,主要包括:Java API、命令行接口、C 语言库、Thrift 接口与用户文件系统等。
完全无中心架构-Ceph
以Ceph为代表的架构是完全无中心架构的代表。
Ceph存储系统的设计目标是提供高性能、高可扩展性、高可用的分布式存储服务。它采用RADOS(Reliable Autonomic Distributed Object Store)在动态变化和异构的存储设备集群上,提供了一种稳定、可扩展、高性能的单一逻辑对象存储接口和能够实现节点自适应和自管理的存储系统。数据的放置采取CRUSH算法,客户端根据算法确定对象的位置并直接访问存储节点,不需要访问元数据服务器。CRUSH算法具有更好的扩展性和性能。本节介绍了Ceph的集群架构、数据放置方法以及数据读写路径,并在此基础上分析其性能特点和瓶颈。
RADOS可提供高可靠、高性能和全分布式的对象存储服务。对象的分布可以基于集群中各节点的实时状态,也可以自定义故障域来调整数据分布。块设备和文件都被抽象包装为对象,对象则是兼具安全和强一致性语义的抽象数据类型,因此RADOS可在大规模异构存储集群中实现动态数据与负载均衡。
对象存储设备(Object Storage Device,OSD)是RADOS集群的基本存储单元,它的主要功能是存储、备份和恢复,数据,并与其他OSD之间进行负载均衡和心跳检查等。一块硬盘通常对应一个OSD,由OSD对硬盘存储进行管理,但有时一个分区也可成为一个OSD,每个OSD皆可提供完备和具有强一致性的本地对象存储服务。MDS(Metadata Server)是元数据服务器,向外提供CephFS在服务时发出的处理元数据的请求,将客户端对文件的请求转化为对对象的请求。RADOS中可以有多个MDS分担元数据查询的工作。
如下图所示,一个RADOS集群由大量OSD、0~n个MDS和少数几个Monitor组成。
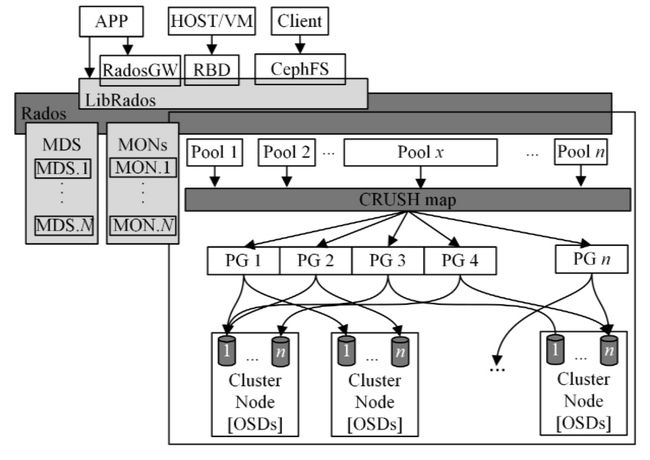
Ceph存储集群由多种类型的守护进程组成:
Ceph Monitor分析
Ceph Monitor维护集群的主副本映射、Ceph集群的当前状态以及处理各种与运行控制相关的工作。在Ceph集群中配置多个Ceph Monitor可确保在其中一个Ceph Monitor守护进程或其主机发生故障时的可用性。
每个Monitor节点上都运行守护进程(ceph-mon)。该守护进程可维护集群映射的主副本,包括集群拓扑图。这意味着Ceph客户端只需要连接到一个Monitor节点并检索当前的集群映射,即可确定所有Monitor和OSD节点的位置。
-
Ceph Monitor的主要作用是维护集群的数据主副本映射关系。同时,它为每个组件维护一个单独的信息图,包括OSD Map、MON Map、MDS Map、PG Map和CRUSH Map等。所有集群节点均向Monitor节点报告,并共享有关其状态的每个更改信息。Monitor不存储实际数据。存储数据是OSD的工作。
-
Ceph Monitor还提供身份验证和日志服务。Monitor将监控服务中的所有更改信息写入单个Paxos,并且Paxos更改写入的K/V存储,以实现强一致性。Ceph Monitor使用K/V存储的快照和迭代器(LevelDB数据库来执行整个存储的同步)。换句话说,Paxos是Ceph Monitor的核心服务,专门负责数据一致性工作。
Paxos服务解决的问题正是分布式一致性问题,即一个分布式系统中的各个进程如何就某个值(决议)达成一致。Paxos服务运行在允许有服务器宕机的系统中,不要求消息的可靠传递,可容忍消息丢失、延迟、乱序和重复。它利用大多数机制保证了 2 N + 1 2N+1 2N+1 的容错能力,即 2 N + 1 2N+1 2N+1 个节点的系统中最多允许 N N N 个节点同时出故障。
Ceph OSD分析
-
利用Ceph节点上的CPU、内存和网络进行数据复制、纠错、重新平衡、恢复、监控和报告等。
-
Ceph OSD守护进程检查自己的状态和其他OSD的状态,并向Ceph Monitor报告。
通常每个磁盘对应一个OSD守护进程。
Ceph Manager分析
维护PG(放置组)有关的详细信息,代替Ceph Monitor处理元数据和主机元数据,能显著改善大规模集群的访问性能。Ceph Manager处理许多只读Ceph CLI的查询请求,例如放置组统计信息。Ceph Manager还提供了RESTful API。
-
Ceph Manager从整个集群中收集状态信息。Ceph Manager守护进程和Ceph Monitor守护进程一起运行,提供了附加的监控功能,并与外部监控系统和管理系统连接。
-
它还提供其他服务(如Ceph DashBoard UI)、跟踪运行时指标,并通过基于Web浏览器和仪表盘和RESTful API公开集群信息。
将Ceph Manager和Ceph Monitor放在同一节点上运行比较明智,但不强制。
Ceph Clients分析
Ceph客户端接口负责和Ceph集群进行数据交互,包括数据的读写。客户端与Ceph集群进行通信需要以下数据:
- Ceph集群配置文件或集群的名称(通常命名为ceph)、Monitor地址
- 存储池名称
- 用户名和密钥路径
Ceph客户端维护对象ID和存储对象的存储池名称。为了存储和检索数据,Ceph客户端访问Ceph Monitor并检索最新的Cluster Map副本,然后由Ceph客户端向Librados提供对象名称和存储池名称。Librados会使用CRUSH算法为要存储和检索的数据计算对象的放置组和主OSD。客户端连接到主OSD,并在其中执行读取和写入操作。
小结
HDFS
优点
-
容错性:数据自动保存多个副本。通过增加副本的形式,提高容错性。其中一个副本丢失以后,可以自动恢复。
-
可以处理大数据:能够处理数据规模达到GB、TB甚至PB级别的数据;能够处理百万规模以上的文件数量。
-
可以构建在廉价的机器上,通过多副本机制,提高可靠性。
缺点
-
不适合低延时数据访问:比如毫秒级的存储数据,是做不到的。
-
无法高效对大量小文件进行存储:存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。同时,小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
-
不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写。仅支持数据append(追加),不支持文件的随机修改。
Ceph
优点
- 高性能。针对并发量大的异步IO场景,随着集群规模的扩大,Ceph可提供近线性的性能增长。
- 高可扩展性。Ceph通过CRUSH算法来实现数据寻址。这种方法避免了元数据访问的瓶颈,使集群的存储容量可以轻易扩展至PB级,甚至EB级。
- 统一存储,适用范围广。Ceph支持块、文件和对象存储,可满足多种不同的需求。底层的RADOS可扩展并支持不同类型的存储服务。
- 支持范围广。 自2012年起,Linux内核开始支持Ceph,目前Ceph可以在几乎所有主流的Linux发行版和其他类UNIX系统上运行。自2016年起,Ceph开始支持ARM架构,同时也可适用于移动、低功耗等领域,其应用场景覆盖了当前主流的软硬件平台。
缺点
- Ceph的数据分布算法CRUSH在实际环境中存在一些问题,包括扩容时数据迁移不可控、数据分布不均衡等。这些问题影响了Ceph性能的稳定性。
- Ceph的架构复杂,抽象层次多,时延较大。虽然Ceph采用面向对象的设计思想,但其代码内对象间的耦合严重,导致不同版本间的接口不兼容。针对不同版本的性能优化技术和方法也互相不兼容。
- Ceph是一个通用的分布式存储系统,可应用于云计算、大数据和高性能计算等领域。针对不同的访问负载特征,Ceph还有较大的性能提升和优化空间。
参考
- 《基于HDFS分布式存储技术研究与优化》
- 《Ceph分布式存储系统性能优化技术研究综述》
- 《Ceph企业级分布式存储:原理与工程实践》
- https://zhuanlan.zhihu.com/p/186024598
- https://zhuanlan.zhihu.com/p/524792408