分布式多级缓存SDK设计的思考
分布式多级缓存SDK设计的思考
- 背景
- 整体架构
-
- 多层级组装
- 回调埋点
- 分区处理
- 一致性问题
-
- 缓存与数据库之间的一致性问题
- 不同层级缓存之间的一致性问题
- 不同微服务实例上,非共享缓存之间的一致性问题
- 小结
之前实习期间编写过一个简单的多级缓存SDK,后面了解到一些其他的开源产品,如J2Cache,京东的JdHotKey,有赞的多级缓存SDK实现,所以本文想来总结一下我对多级缓存SDK设计的考量和开发心得。
参考的相关开源实现链接:
- 有赞透明多级缓存解决方案(TMC)
- J2Cache
- hotkey
背景
编写这个SDK起因于部门各个服务缓存使用上的不统一,有些没有使用缓存,有些单独使用了本地缓存或者Redis集中式缓存,还有些使用了阿里的Tair缓存,因此为了结束缓存使用混乱的局面,就有了这个多级缓存SDK Demo 。
我们期望这个多级缓存SDK能够满足以下目标:
- 支持自定义缓存层级和缓存层级之间的顺序,例如: 可以是Caffeine+Redis的组合,也可以是Caffeine + Tair + Redis的组合
- 需要与链路追踪工具Cat结合,定时上报缓存工作状态,如: 全局缓存命中率,各级缓存命中率等
- 需要支持灰度与开关机制,灰度用于控制走缓存比例,开关用于上下线该SDK,或者单独上下线某一级缓存
- 需要处理好缓存穿透,缓存击穿,缓存与数据库一致性,多级缓存间的一致性,以及分布式环境下,各个实例上非共享的L1级缓存的一致性问题。
以上四点是我目前所能想到的内容,也是我所开发的SDK支持的功能,如果大家有补充欢迎在评论区留言。
下面我将从整体架构讲起,一直聊到以上所说的细节实现。
整体架构
多级缓存SDK整体架构如何所示:
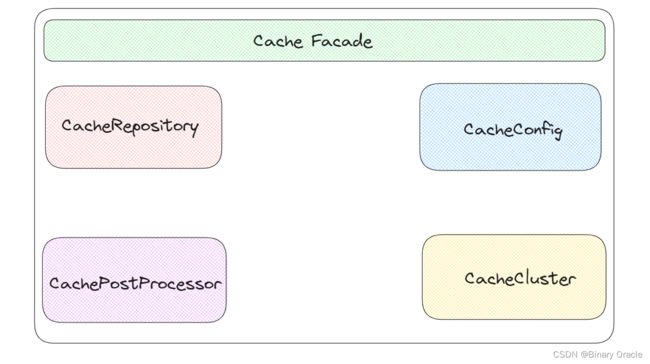
- CacheFacade 作为缓存门面对象,向用户屏蔽了内部多个模块协同工作的复杂性,同时负责编排多级缓存 get 和 set 的模版流程,并在相关位置进行回调埋点,方便后续扩展。
- CacheRepository 作为多级缓存实现,采用装饰器模式层级嵌套关系,缓存的 get 流程是先走低层级缓存,再走高层级缓存;set 和 del 流程是先走高层级缓存,再走低层级缓存。
- CacheConfig 作为配置模块,收拢了整个缓存SDK所有的配置项,同时采用SPI机制可以实现配置中心的动态切换,默认只提供了ApolloConfigProvider,用于支持Apollo作为配置中心。
- CachePostProcessor 顶层提供了相关默认接口实现,如果我们希望能够在缓存执行的某个流程处进行监听,可以重写相关接口实现,添加对应的拦截逻辑,然后将自身交于缓存后置处理模块管理即可。
- CacheCluster 负责实现多个实例之间的非共享L1级缓存的一致性,当有请求试图在某个实例上执行set或者del操作时,都需要广播告知其他实例,用于清除自身的L1级缓存。
整个缓存SDK的架构还是非常简单的,下面我将针对各处细节进行说明。
多层级组装
多级缓存SDK默认情况下会提供Caffeine+Redis的两级缓存,但是如果业务有特殊需求,不满足于此,我们也可以自定义缓存层级 :
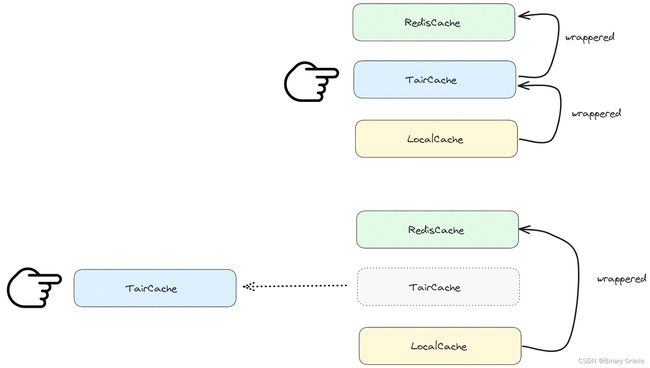
为了支持自定义缓存层级,这里采用装饰器模式的层层装饰来实现多级缓存的效果,伪代码如下图所示:
public abstract class AbstractCacheRepositoryWrapper implements CacheRepository {
private final CacheRepository wrappedCacheWrapper;
public AbstractCacheRepositoryWrapper(CacheRepository wrappedCacheWrapper) {
this.wrappedCacheWrapper = wrappedCacheWrapper;
}
...
}
接入方只需要为接入的缓存提供一个CacheRepository实现,并且自行完成装饰层级的嵌套组装,最后将组装得到的对象实例交由CacheFacade管理即可;如果项目使用到了Spring ,这里可以将对象实例注入容器,CacheFacade 由容器中取得即可。
回调埋点
CacheFacade 作为缓存门面对象,向用户屏蔽了内部多个模块协同工作的复杂性,同时负责编排多级缓存 get 和 set 的模版流程,并在相关位置进行回调埋点,方便后续扩展。
因为 CacheFacade 拿到的其实是已经组装完毕的多级缓存对象,如下图所示:
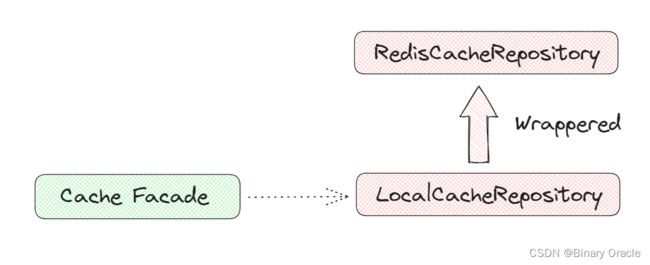
所以这里 get 和 set 请求要分为两段来看,一段是存在于缓存门面对象中设定好的模版流程,另一段是存在于AbstractCacheRepositoryWrapper中设定好的多级缓存间的get,set,del 流程。
我们先来看看缓存门面对象中设置设定好的模版流程和相关回调埋点的工作时机:
- get 流程
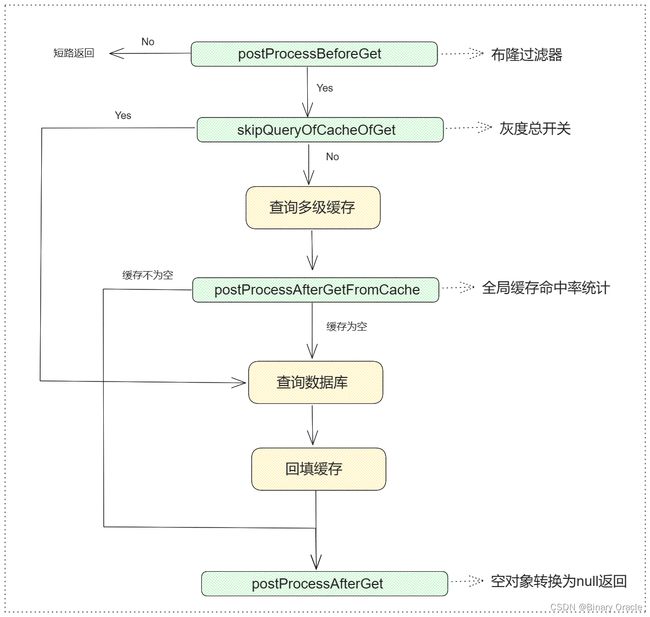
-
list 流程
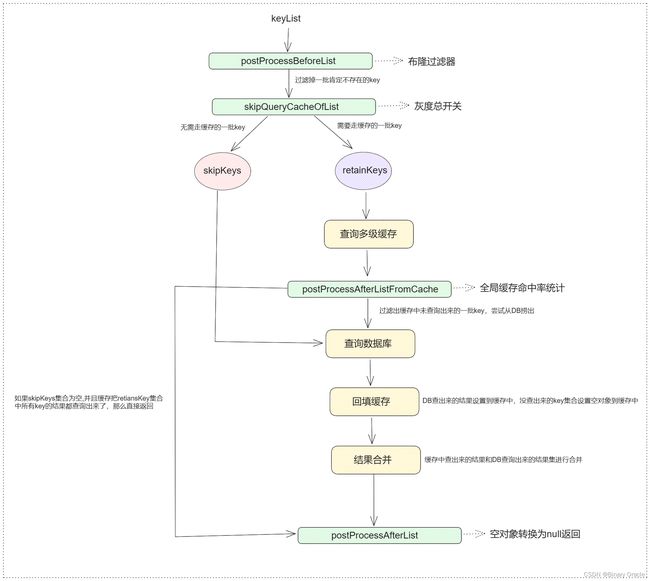
-
set 流程
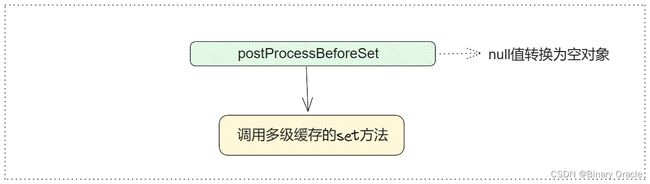
- del 流程

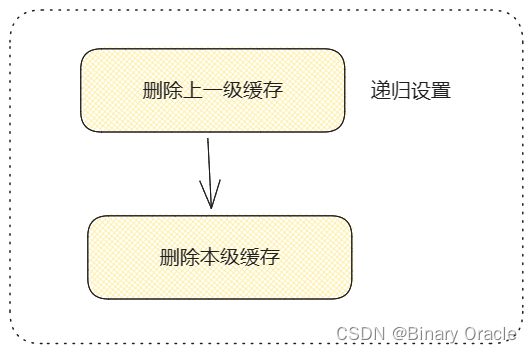
上面可以理解为全局缓存的执行流程,下面我们来看看存在于AbstractCacheRepositoryWrapper中设定好的多级缓存间的get,set,del 流程:
- get 流程
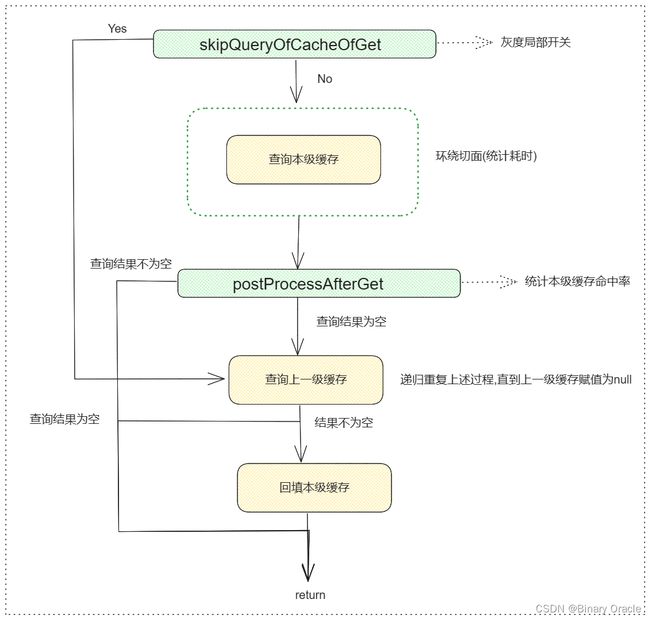
- list 流程
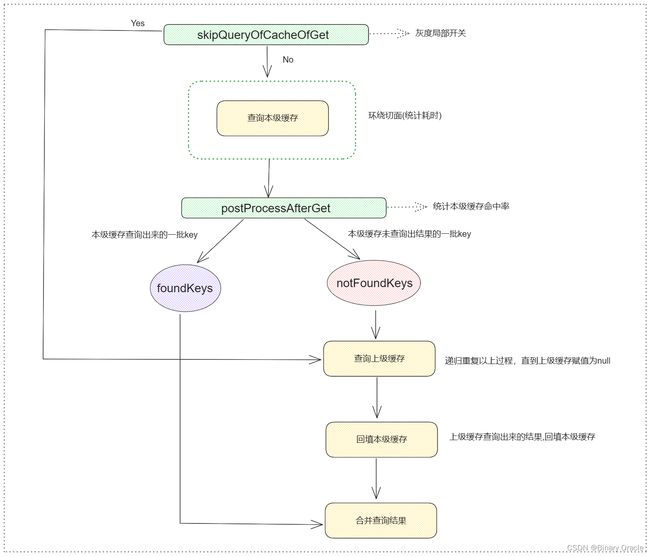
- set 流程
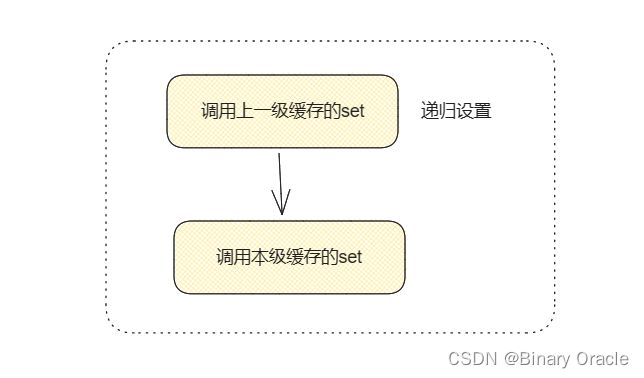
- del 流程
上述流程图中各处埋点均以绿色标出,每当执行到埋点处时,都会去调用后置处理器链,后置处理器又分为全局后置处理器和局部后置处理器,前者工作在缓存门面设定的全局流程中,后者工作在多级缓存的局部流程中。
如果后续有扩展需求,只需要自定义一个后置处理器,加入后置处理器链中即可。
分区处理
我是从J2Cache中了解到的分区Region的思想,也在随后添加到了我自己开发的多级缓存SDK中,这里简单介绍一下为什么我们需要分区:
- 在实际的缓存场景中,不同的数据会有不同的 TTL 策略,例如有些缓存数据可以永不失效,而有些缓存我们希望是 30 分钟的有效期,有些是 60 分钟等不同的失效时间策略。在 Redis 我们可以针对不同的 key 设置不同的 TTL 时间。但是一般的 Java 内存缓存框架(如 Ehcache、Caffeine、Guava Cache 等),它没法为每一个 key 设置不同 TTL,因为这样管理起来会非常复杂,而且会检查缓存数据是否失效时性能极差。所以一般内存缓存框架会把一组相同 TTL 策略的缓存数据放在一起进行管理。
- 通过分区可以将属于不同业务的缓存隔离开来,防止相互污染,比如我们使用LRU缓存,所有业务共用一个LRU缓存,如果业务A总是大批次查询,那么可能会将其他业务热点key给淘汰出去,造成污染问题。
采用分区之后,CacheFacade 门面对象内部也就不是简单持有一个多级缓存实例对象了,而是持有一个多级缓存实例映射集合,如下图所示:

此时,我们的 get 和 set 等方法也都需要改造,在方法参数处添加一个 region,指明要操作哪个 region。
一致性问题
一致性问题主要考虑三点:
- 缓存与数据库之间的一致性问题
- 不同层级缓存之间的一致性问题
- 不同微服务实例上,非共享缓存之间的一致性问题
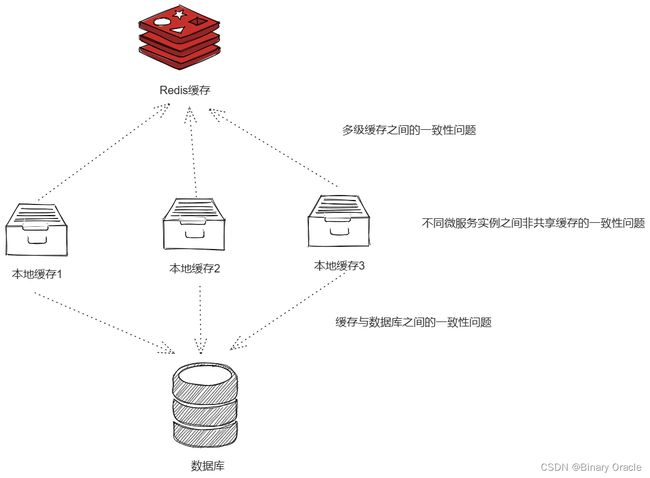
缓存与数据库之间的一致性问题
关于缓存与数据库之间的一致性问题,这里我简单介绍其中一种方案:
之前写过一篇文章讲述缓存与数据库一致性问题,这里就直接把图贴过来了
- 旁路缓存模式: 先更新数据库,再删除缓存
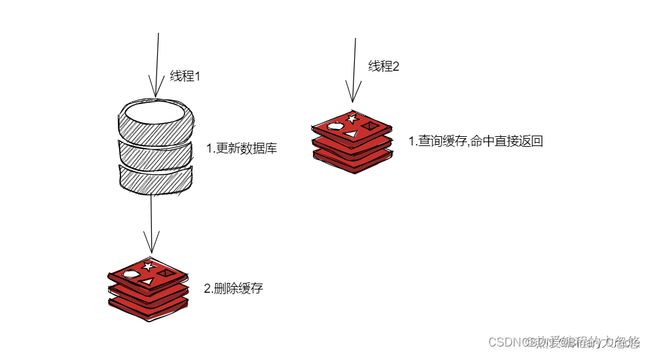
可能存在的问题是: 两个并发线程,一个读,一个写,读线程发现缓存失效,去数据库查询数据,查询完后更新redis,但是更新redis前,写线程率先完成了写入操作,导致读线程最终放入redis的还是旧数据
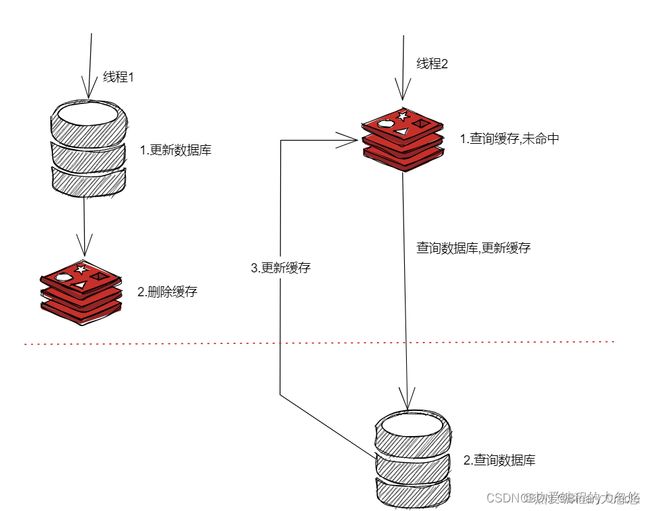
不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
为了避免旁路缓存出现这个问题,我们可以采用缓存双删策略:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存。
这个休眠一会,一般多久呢?都是1秒?
- 这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败呢,删除失败会导致脏数据产生,因此为了保险起见,我们需要增加删除失败的重试逻辑:
- 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放到消息队列
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作
上述逻辑可能会造成业务代码入侵,我们可以考虑使用canal监听binlog的修改变更,将所有修改消息发送到MQ,然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性。
不同层级缓存之间的一致性问题
假设此时我的多级缓存层级是两层: Caffeine+Redis ,那么如何确保这两者之间的数据一致性呢 ?
首先,我们要明白一点:
- 离服务越近的缓存源,其存储容量越小,速度越快,过期时间越短
- 离服务越远的缓存源,其存储容量越大,速度越慢,过期时间越长
这里其实很像CPU多级缓存体系,为了保证多级缓存之间的数据一致性,需要分以下几个方面讨论:
- 查询先从L1级缓存查起,如果L1没有,再查询L2,如果L2也没有,那么查询DB;返回阶段,会依次把上一级查询得到的结果回填到本级缓存,最终返回结果给到调用方。
- set 操作是先设置L2级缓存,再设置L1级缓存,因为L2级缓存是共享的,设置完L2后,确保立刻对其他所有实例可见
- del 操作是先删除L2级缓存,再删除L2级缓存,也是因为L2级缓存是共享的,删除完L2后,确保立刻对其他所有实例可见
这里是否还需要考虑其他的点,欢迎各位在评论区留言。
不同微服务实例上,非共享缓存之间的一致性问题
这里也是参考的L2Cache的思路,当我们对某个实例的非共享缓存层级执行修改或者删除操作的时候,我们需要借助消息广播,告知其他所有实例删除自己本地对应的缓存,以此确保多个实例之间的非共享缓存的一致性。
假设此时我们的多级缓存层级为: Caffeine+Redis , 当我们对实例1的本地缓存进行修改或者删除操作时,我们需要将操作涉及到的keys广播给其他所有实例;对应的实例接收到广播消息后,需要删除本地缓存中对应的keys,确保一致性。
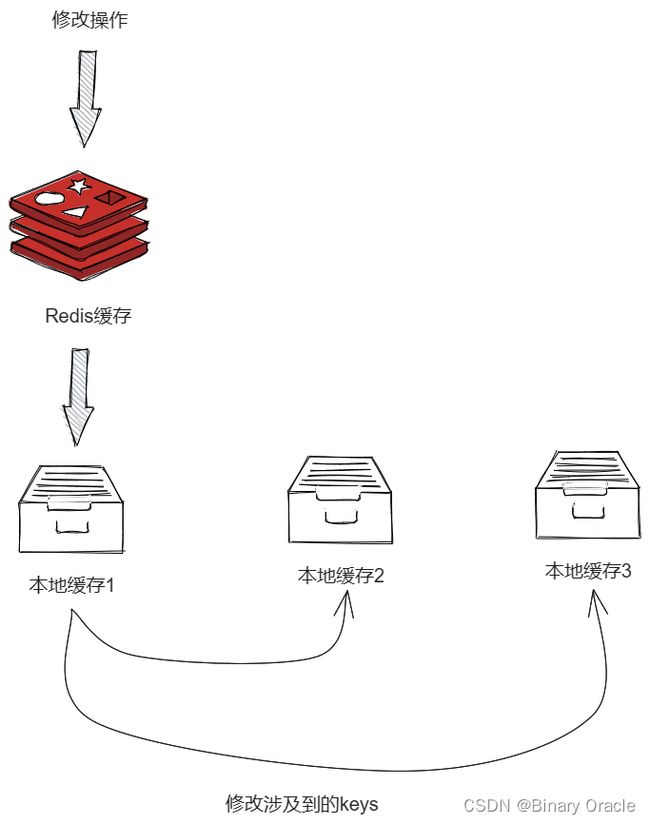
Redis是集中式缓存,所以无需担心一致性问题。
这里其实和CPU多级缓存的一致性问题解决思路类似,因为CPU多级缓存中通常L1和L2级缓存都是单个核私有的,L3是共享的,所以同样存在如何实现一致性的问题。
这里消息广播可以借助于消息队列,或者Redis的pub/sub,或者在SDK中引入netty进行通信。
小结
这里有一点没提到,就是关于京东的JdHotKey和有赞的TMC,他们的缓存SDK设计思路更多是为了解决热点key探测与即时缓存到LocalCache,因此他们整体的架构设计就和文本不太一样了,简单来说如下图所示:
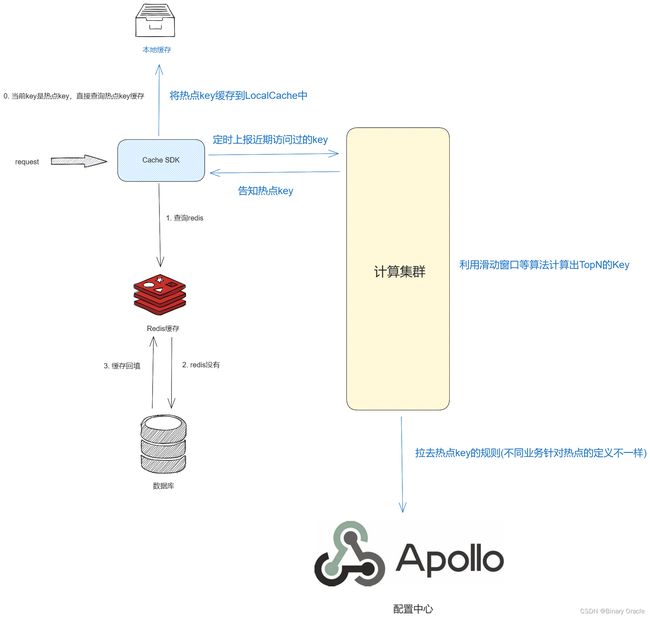
他们只使用到了集中式缓存Redis,只使用本地缓存进行热点key的缓存,而非全量缓存;同时为了确保强一致性,会监听redis过期key事件,当发生key过期事件时,会广播给所有实例,删除所有实例热点缓存中对应的key,确保强一致性。
本文仅为笔者个人拙见,如有理解错误,欢迎各位大佬在评论区留言指出。