关于golang里channel的一些问题的深究
前言
最近在学golang原理,于是就研究了一下channel和goroutine,了解golang底层是怎么操作的

channel
什么是channel,为什么它可以做到线程安全?
Channel是Go中的一个核心类型,可以把它看成一个管道,通过它并发核心单元就可以发送或者接收数据进行通讯(communication),Channel也可以理解是一个先进先出的队列,通过管道进行通信。
Golang的Channel,发送一个数据到Channel 和 从Channel接收一个数据 都是 原子性的。而且Go的设计思想就是:不要通过共享内存来通信,而是通过通信来共享内存,前者就是传统的加锁,后者就是Channel。也就是说,设计Channel的主要目的就是在多任务间传递数据的,这当然是安全的。

go语言的channel特性
A. 给一个 nil channel 发送数据,造成永远阻塞
B. 从一个 nil channel 接收数据,造成永远阻塞
C. 给一个已经关闭的 channel 发送数据,引起 panic
D. 从一个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
E. 无缓冲的channel是同步的,而有缓冲的channel是非同步的
channel无缓存和有缓存的区别
无缓冲的与有缓冲channel有着重大差别,那就是一个是同步的 一个是非同步的。
比如
c1:=make(chan int) 无缓冲
c2:=make(chan int,1) 有缓冲
c1<-1
-
无缓冲: 不仅仅是向 c1 通道放 1,而是一直要等有别的携程 <-c1 接手了这个参数,那么c1<-1才会继续下去,要不然就一直阻塞着。
-
有缓冲: c2<-1 则不会阻塞,因为缓冲大小是1(其实是缓冲大小为0),只有当放第二个值的时候,第一个还没被人拿走,这时候才会阻塞。
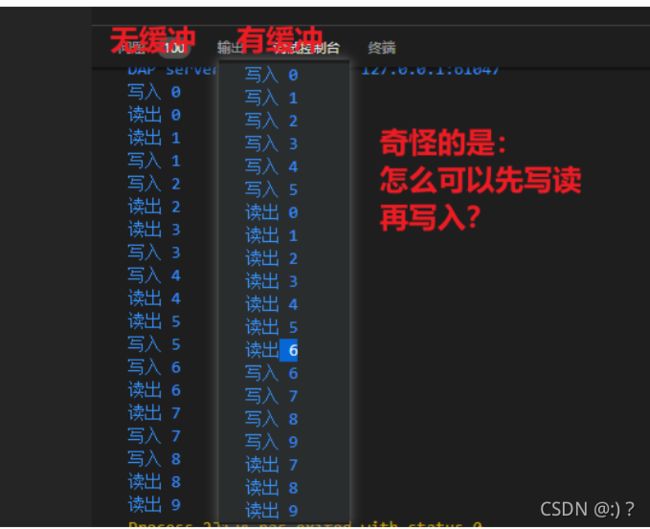
看代码实现:
package main
import "fmt"
func main(){
ch:=make(chan int) //这里就是创建了一个channel,这是无缓冲管道注意
// ch:=make(chan int,5) //这个是有缓冲的
go func(){ //创建子go程
for i:=0;i<6;i++{
ch<-i //循环写入管道
fmt.Println("写入",i)
}
}()
for i:=0;i<6;i++{ //主go程
num:=<-ch //循环读出管道
fmt.Println("读出",num)
}
}

协程,线程,进程的区别
- 进程
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。 由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
- 线程
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
- 协程(用户态)
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
-
进程是资源的分配和调度的一个独立单元,而线程是CPU调度的基本单元;同一个进程中可以包括多个线程;
-
进程结束后它拥有的所有线程都将销毁,而线程的结束不会影响同个进程中的其他线程的结束;线程共享整个进程的资源(寄存器、堆栈、上下文),一个进程至少包括一个线程;
-
一个应用程序一般对应一个进程,一个进程一般有一个主线程,还有若干个辅助线程,线程之间是平行运行的,在线程里面可以开启协程,让程序在特定的时间内运行。
-
协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。

线程有几种模型
线程模型有3种
- 内核线程模型
- 用户级线程模型
- 混合型线程模型
Linux历史上线程的3种实现模型: 线程的实现曾有3种模型:(看内核线程和用户线程的对应关系)
- 多对一(M:1)的用户级线程模型
- 一对一(1:1)的内核级线程模型
- 多对多(M:N)的两级线程模型

goroutine
goroutine的GMP调度器

一图读懂GMP调度器
GMP之前用的是GM模型,为什么要替换掉?
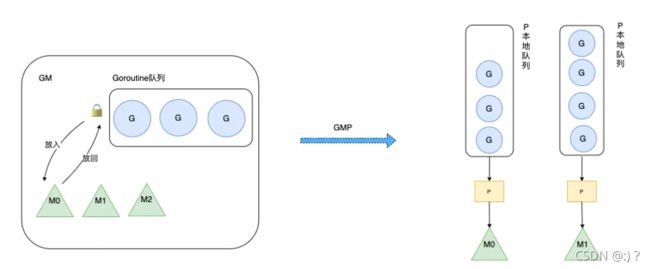
GM模型中的G全称为Goroutine协程,M全称为Machine内核级线程,调度过程如下

M(内核线程)从加锁的Goroutine队列中获取G(协程)执行,如果G在运行过程中创建了新的G,那么新的G也会被放入全局队列中。
很显然这样做有俩个缺点
- 一是调度,返回G都需要获取队列锁,形成了激烈的竞争。
- 二是M转移G没有把资源最大化利用。比如当M1在执行G1时,M1创建了G2,为了继续执行G1,需要把G2交给M2执行,因为G1和G2是相关的,而寄存器中会保存G1的信息,因此G2最好放在M1上执行,而不是其他的M。

GMP模型是怎么设计的吗?
G全称为Goroutine协程,M全称为Machine内核级线程,P全称为Processor协程运行所需的资源,他在GM的基础上增加了一个P层

全局队列:当P中的本地队列中有协程G溢出时,会被放到全局队列中。
P的本地队列:P内置的G队列,存的数量有限,不超过256个。这里有俩种特殊情况。
- 一是当队列P1中的G1在运行过程中新建G2时,G2优先存放到P1的本地队列中,如果队列满了,则会把P1队列中一半的G移动到全局队列。
- 二是如果P的本地队列为空,那么他会先到全局队列中获取G,如果全局队列中也没有G,则会尝试从其他线程绑定的P中偷取一半的G。
P和M数量是可以无限扩增的吗?
是不能无限扩增的,无限扩增系统也承受不了呀,哈哈

P的数量:由启动时环境变量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定。
M的数量:go程序启动时,会设置M的最大数量,默认10000。但是内核很难创建出如此多的线程,因此默认情况下M的最大数量取决于内核。也可以调用runtime/debug中的SetMaxThreads函数,手动设置M的最大数量。
那P和M都是在程序运行时就被创建好了吗?
P和M创建的时机是不同的
P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
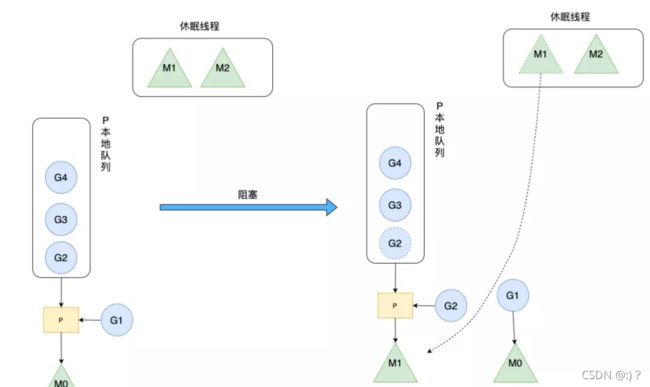
M何时创建:内核级线程的初始化是由内核管理的,当没有足够的M来关联P并运行其中的可运行的G时会请求创建新的M。比如M在运行G1时被阻塞住了,此时需要新的M去绑定P,如果没有在休眠的M则需要新建M。
当M0将G1执行结束后会怎样做
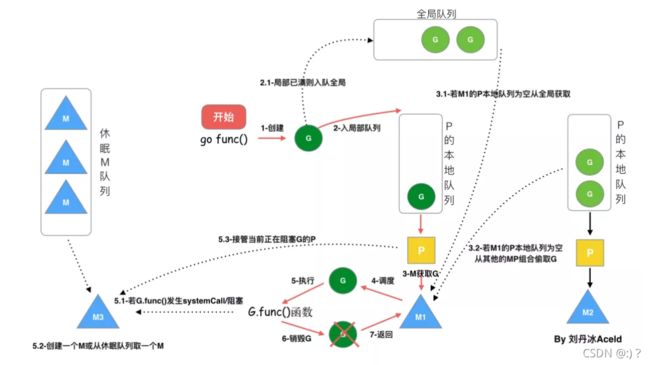
- 调用 go func()创建一个goroutine;
- 新创建的G优先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
- M需要在P的本地队列弹出一个可执行的G,如果P的本地队列为空,则先会去全局队列中获取G,如果全局队列也为空则去其他P中偷取G放到自己的P中
- G将相关参数传输给M,为M执行G做准备
- 当M执行某一个G时候如果发生了系统调用产生导致M会阻塞,如果当前P队列中有一些G,runtime会将线程M和P分离,然后再获取空闲的线程或创建一个新的内核级的线程来服务于这个P,阻塞调用完成后G被销毁将值返回;
- 销毁G,将执行结果返回
- 当M系统调用结束时候,这个M会尝试获取一个空闲的P执行,如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中。
GM与GMP的比较
GMP相对于GM做了哪些优化?
优化点有三个
-
一是每个 P 有自己的本地队列,而不是所有的G操作都要经过全局的G队列,这样锁的竞争会少的多的多。而 GM 模型的性能开销大头就是锁竞争。
-
二是P的本地队列平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行(通常是偷一半),减少空转,提高了资源利用率。

-
三是hand off机制当M0线程因为G1进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程M1执行,同样也是提高了资源利用率。

队列和线程的优化可以做在G层和M层,为什么要加一个P层呢?
因为M层是放在内核的,我们无权修改,在前面协程的问题中回答过,内核级也是用户级线程发展成熟才加入内核中。所以在M无法修改的情况下,所有的修改只能放在用户层。将队列和M绑定,由于hand off机制M会一直扩增,因此队列也需要一直扩增,那么为了使Work Stealing 能够正常进行,队列管理将会变的复杂。因此设定了P层作为中间层,进行队列管理,控制GMP数量(最大个数为P的数量)。

goroutine的GMP调度器
基于CSP并发模型开发了GMP调度器,其中
- G(Goroutine) : 每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数
- M(Machine): 对OS内核级线程的封装,数量对应真实的CPU数(真正干活的对象).
- P (Processor): 逻辑处理器,即为G和M的调度对象,用来调度G和M之间的关联关系,其数量可通过 GOMAXPROCS()来设置,默认为核心数。
细说:
-
在单核情况下,所有Goroutine运行在同一个线程(M0)中,每一个线程维护一个上下文(P),任何时刻,一个上下文中只有一个Goroutine,其他Goroutine在runqueue中等待。
-
一个Goroutine运行完自己的时间片后,让出上下文,自己回到runqueue中(如下图所示)。
-
当正在运行的G0阻塞的时候(可以需要IO),会再创建一个线程(M1),P转到新的线程中去运行。
-
当M0返回时,它会尝试从其他线程中“偷”一个上下文过来,如果没有偷到,会把Goroutine放到Global runqueue中去,然后把自己放入线程缓存中。 上下文会定时检查Global runqueue。

goroutine的优势
乐观锁 和 线程与协程的空间
- 上下文切换代价小:从GMP调度器可以看出,避免了用户态和内核态线程切换,所以上下文切换代价小
- 内存占用少:线程栈空间通常是 2M,Goroutine(协程) 栈空间最小 2K;
goroutine 什么时候发生阻塞
- channel 在等待网络请求或者数据操作的IO返回的时候会发生阻塞
- 发生一次系统调用等待返回结果的时候
- goroutine进行sleep操作的时候

在GMP调度模型,goroutine 有哪几种状态?线程呢?
goroutine有9种状态

去抢占 G 的时候,会有一个自旋和非自旋的状态
如果 goroutine 一直占用资源怎么办,GMP模型怎么解决这个问题
如果有一个goroutine一直占用资源的话,GMP模型会从正常模式转为饥饿模式,通过信号协作强制处理在最前的 goroutine 去分配使用
