SQL系列(一)快速掌握Hive查询的重难点
SQL系列(一)快速掌握Hive查询的重难点
作为一名数(取)据(数)分(工)析(具)师(人),不得不夸一下SQL,毕竟凭一己之力养活了80%的数据分析师,甚至更多。SQL语言短小精悍,简单易学,而且分析师重点只关注查询,使得学习成本和时间成本瞬间就下来了。
企业日常涉及的SQL很多,常见的如MySQL、Hive、Presto、ES(ElasticSearch)等。但分析师日常使用最多的还是Hive,因此本文就将日常工作的Hive查询重难点做个汇总,分享给大家~
⚠️注意:这里不是介绍SQL的基础,基础知识在上期【数据分析师的必要条件】已经提及。该系列的核心是学完即用,因此后续的所有分享都是建立在具有一定的数分基础上的。
建议:对于初学者或想转行数据分析的同学,可以先收藏,等具备一定数分基础后再跟随学习效果更佳。基础学习可以参照上期的【数据分析师的必要条件】。
语法
相信大家在都是以MySQL或者SQLite入门学习的,所以当开始转写Hive查询时,你会发现内心毫无波动,这就和会骑自行车的人一定会骑电动车是一样的。
当然,如果硬要找出一些差异,也是有的。最主要的还是函数上的差异,除此之外还有如下几点:
- Hive不支持不等值连接,但是可以通过开启MapJoin的参数以获得支持。当然目前Hive2版本已经支持不等值连接了。例如:
-- 开启MapJoin的参数
set hive.auto.convert.join = true; -- 自动转换为mapjoin
set hive.mapjoin.smalltable.filesize = 25000000; -- 小表的最大文件大小
set hive.auto.convert.join.noconditionaltask=true; -- 将多个mapjoin合并为一个
set hive.auto.convert.join.noconditionaltask.size=10000000; -- 多个mapjoin转换为1个时,所有小表的文件大小总和的最大值
-- 非等值连接情况 -- Hive2版本已经支持
select * from temp1 a left join temp2 b on a.id=b.id and a.age>b.age
- Hive子查询不支持跟在
in,not in等后面,不过在0.13版本后已经开始支持。不过习惯上更建议转成连接关系。
-- 跟在in后面的子查询 0.13版本后开始支持
select
*
from
temp1
where
id in (select id from temp2 where age>10)
-- 转为连接关系
select a.* from temp1 a left join temp2 b on a.id=b.id where b.age>10
- Hive汇总查询时,不支持查询非group by中的字段(除聚合函数计算字段),例如:
-- 错误情况
select
age
,gender -- gender未出现在group by中
,count(1) as cnt
from
temp1
group by
age
-- 正确使用
select
age
,gender -- gender需出现在group by中
,count(1) as cnt
from
temp1
group by
age
,gender
- 在进行等值判断时,SQL默认会将数值型字符串转为double型后判断,减少类型转换操作。但是Hive在处理非数值型字符串与MySQL是不一致的,具体如下:
-- 数值型字符串判断,两者一致
select
'1'=1 -- 返回结果true/1
,'1.5'=1.5 -- 返回结果true/1
-- 非数值型字符串判断,Hive会默认处理为null,由于null不参与计算,所以结果为null
select
''=1 -- 返回结果null
,'age'=1.5 -- 返回结果null
-- 非数值型字符串判断,MySQL会默认处理为''
select
''=1 -- 返回结果0
,'age'=1.5 -- 返回结果0
- Hive和MySQL在数据类型上有一定差异,因此在进行数值与字符串转换时,存在较大差异,具体如下:
-- MySQL数值与字符串的相互转化
select
cast('1' as unsigned integer) as str2int
,cast('1.3' as decimal(10,2)) as str2double
,cast(113 as char) as int2str
,cast(11.3 as char) as double2str
-- Hive数值与字符串的相互转化
select
cast('1' as int) as str2int
,cast('1.3' as double) as str2double
,cast(113 as string) as int2str
,cast(11.3 as string) as double2str
函数
前面指出Hive与MySQL在函数上有较多不同,但由于Hive的函数众多,且更适用于日常分析的查询。这里就只介绍Hive的函数,对MySQL函数感兴趣的可以参考菜鸟教程的MySQL函数大全。
虽然Hive函数众多,但很多函数的使用频率极低,因此本文也只介绍高频、重点的函数,其余函数在需要用到的时候可以在Hive UDF手册上查找使用,本文介绍的函数同样也是摘自于此,并对必须掌握的进行了加粗处理。中文版可以参照Hive函数大全中文版 。
数学函数
| 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|
| DOUBLE | round(DOUBLE a, INT d) | 保留d位小数 | |
| BIGINT | floor(DOUBLE a) | 向下取整 | |
| BIGINT | ceil(DOUBLE a), ceiling(DOUBLE a) | 向上取整 | |
| DOUBLE | rand(), rand(INT seed) | (0,1)间的随机数,seed为随机种子 | |
| DOUBLE | pow(DOUBLE a, DOUBLE p), power(DOUBLE a, DOUBLE p) | a p a^p ap | |
| DOUBLE | abs(DOUBLE a) | a的绝对值 | |
| INT or DOUBLE | pmod(INT a, INT b), pmod(DOUBLE a, DOUBLE b) | a对b取模,即余数 | pmod(10,3) – 1 |
| DOUBLE or INT | sign(DOUBLE a), sign(DECIMAL a) | 符号函数,正数返回1,负数返回-1,0返回0 | |
| T | greatest(T v1, T v2, …) | 横向求最大值,计算多列的最值 | greatest(1,2,3) – 3 |
| T | least(T v1, T v2, …) | 横向求最小值,计算多列的最值 | least(1,2,3) – 1 |
聚合函数
聚合函数除了常规的统计外,还可以按照条件聚合,这也是业务最常见的使用场景。以count函数为例,函数表达式为count(expr)。例如汇总所有年龄在18-35岁间的程序员数量:count(distinct if(age between 18 and 35,id,null))
| 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|
| BIGINT | count(*), count(col),count(DISTINCT col) | 计数 | count(*)统计所有行,包含NULL值。 日常也习惯使用count(1)统计所有行 |
| DOUBLE | sum(col), sum(DISTINCT col) | 求和 | |
| DOUBLE | avg(col), avg(DISTINCT col) | 平均值 | |
| DOUBLE | min(col) | 最小值 | |
| DOUBLE | max(col) | 最大值 | |
| DOUBLE | percentile(BIGINT col, p) | p分位数-整数列 | |
| array | percentile(BIGINT col, array(p1 [, p2]…)) | 同上,支持返回多个分位数 | |
| DOUBLE | percentile_approx(DOUBLE col, p [, B]) | p分位数-支持浮点数 | |
| array |
percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B]) | 同上,支持返回多个分位数 | |
| array | collect_set(col) | 不含重复元素的数组集 | |
| array | collect_list(col) | 含重复元素的数组集 |
条件函数
| 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 二元表达式,如果testCondition为True则返回valueTrue,否则返回valueFalseOrNull | |
| T | nvl(T value, T default_value) | 返回首个不为空的值,都为空则返回NULL。限定为两个字段。 | |
| T | COALESCE(T v1, T v2, …) | 返回首个不为空的值,都为空则返回NULL。不限制字段个数 | |
| T | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 多元表达式 | |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 多元表达式的第二种写法 | |
| boolean | isnull( a ) | 判断是否为NULL | |
| boolean | isnotnull ( a ) | 判断是否不为NULL |
字符串函数
字符串函数中比较复杂的是json操作和正则操作。尤其是正则替换和正则提取,在日常业务中使用频率极高,所以掌握一定的正则知识是必要的。限于篇赋,这两点在后续的SQL实战中再做详细介绍。
| 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|
| string | concat(string|binary A, string|binary B…) | 字符串拼接 | |
| string | concat_ws(string SEP, string A, string B…) | 与concat()类似,但使用指定的分隔符 | concat_ws(‘;’, ‘1’, ‘2’, ‘3’) – ‘1;2;3’ |
| string | concat_ws(string SEP, array) | 可用于拼接array里的字符串 | concat_ws(‘;’, array(‘1’, ‘2’, ‘3’)) – ‘1;2;3’ |
| string | get_json_object(string json_string, string path) | 形如json的字符串中提取value,如果该字符串是非法的json,则返回NULL | |
| int | length(string A) | 返回字符串的长度 | |
| string | lower(string A) lcase(string A) | 转为小写 | |
| string | lpad(string str, int len, string pad) | 左填充至指定长度,如果字符串长度大于制定长度,则剔除尾部多余部分。 | |
| string | ltrim(string A) | 去除头部空格 | |
| string | regexp_extract(string subject, string pattern, int index) | 正则提取 | |
| string | regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) | 正则替换 | |
| string | reverse(string A) | 反转字符串 | |
| string | rpad(string str, int len, string pad) | 右填充至指定长度,如果字符串长度大于制定长度,则剔除尾部多余部分。 | |
| string | rtrim(string A) | 去除尾部空格 | |
| array | split(string str, string pat) | 按指定分隔符(或者正则分隔)分隔字符串,返回数组。 | |
| string | substr(string|binary A, int start) substring(string|binary A, int start) | 字符串截取-从指定位截取到最后 | |
| string | substr(string|binary A, int start, int len) substring(string|binary A, int start, int len) | 字符串截取-从指定位截取到指定长度 | |
| string | substring_index(string A, string delim, int count) | count为正,从左开始截取到第count个分隔符前的字符串count为负,从右开始截取到第 count个分隔符前的字符串 |
substring_index(‘ab,cd,efg’, ‘,’, 2) – ab,cd substring_index(‘ab,cd,efg’, ‘,’, -2) – cd,efg |
| string | trim(string A) | 去除首尾空格 | |
| string | upper(string A) ucase(string A) | 转为大写 | |
| string | initcap(string A) | 首字母大写 |
日期函数
部分日期函数需要较高的版本支持,因此有的函数虽然好用,但需要先校验一下是否可用。
在做日期计算时,建议先将日期转为月初/年初计算(使用trunc函数即可),最后再进行截取操作,因为截取后的日期无法被识别为日期,在后续计算又得concat回来。
| 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|
| string | from_unixtime(bigint unixtime[, string format]) | 时间戳转换为指定格式的日期 | 13位的时间戳为毫秒,转为日期时间时需要除以1000 |
| bigint | unix_timestamp() | 获取当前地区的时间戳 | |
| bigint | unix_timestamp(string date) | 将日期转为时间戳 | |
| bigint | unix_timestamp(string date, string pattern) | 同上,需指定日期格式 | |
| string | to_date(string timestamp) | 转为日期 | |
| int | datediff(string enddate, string startdate) | 计算两日期天数差 | |
| string | date_add(string startdate, int days) | 计算日期增加days天后的日期 |
|
| string | date_sub(string startdate, int days) | 计算日期减去days天后的日期 |
|
| date | current_date | 当天日期 | |
| timestamp | current_timestamp | 当天时间戳 | |
| string | add_months(string start_date, int num_months) | 计算日期增加num_months月后的日期 |
当start_date为月末时,计算结果同样为月末,而不是对应的日期。例如add_months(‘2022-02-28’, 1) – 2022-03-31 |
| string | last_day(string date) | 返回当月的最后一天 | |
| string | next_day(string start_date, string day_of_week) | 返回当前时间的下一个星期几所对应的日期 | |
| string | trunc(string date, string format) | 计算日期的月初/季度初/年初 | |
| double | months_between(date1, date2) | 计算月份差 | |
| string | date_format(date/timestamp/string ts, string fmt) | 日期格式转化 | date_format(‘2022-02-28’, ‘yyyyMMdd’) – 20220228 |
其他重点函数
| 函数类型 | 返回类型 | 函数 | 描述 | 备注 |
|---|---|---|---|---|
| 类型转换函数 | Expected “=” to follow “type” | cast(expr as ) | 类型转换 | |
| 表生成函数 | T | explode(ARRAY a) | 将一列的数组各元素转为多行 | 列转多行 |
| 表生成函数 | Tkey,Tvalue | explode(MAP |
将一列的map各键-值转为多行 | |
| 表生成函数 | int,T | posexplode(ARRAY a) | 将一列的数组各元素位置-元素转为多行 |
窗口函数
窗口函数是Hive的灵魂,因为它让分析型数据查询变得简单,能解决大多数复杂的业务需求。
窗口函数主要由函数+窗口两部分组成,窗口又由分组+排序+范围组成。具体的表现形式为:
Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
-
函数
函数类型 函数 描述 备注 聚合函数 count(col) over() 按窗口计数 聚合函数 avg(col) over() 按窗口求均值 聚合函数 sum(col) over() 按窗口求和 聚合函数 min(col) over() 按窗口求最小值 聚合函数 max(col) over() 按窗口求最大值 排序函数 row_number() over() 不重复排序 1,2,3,4 排序函数 rank() over() 重复排序,跳数字排序 1,2,2,4 排序函数 dense_rank() over() 重复排序,不跳数字排序
dense意为密度,表示紧密的意思,可协助记忆1,2,2,3 排序函数 percent_rank() over() 百分比排名,返回[0,1]之间的数。首位永远为0,跳数字排序
计算逻辑:(x-1)/(len(windows)-1)。就是将rank()结果按[0,1]标准化了0,0.33,0.33,1 排序函数 cume_dist() over() 累积分布,结果按[0,1]标准化 0.25,0.5,0.75,1 排序函数 ntile(n) over() 分组排名,将结果均匀分为 n个组,返回当前行所在组的排名分析函数 lag(col, n, DEFAULT) over() 将col当前行向上取n个数,没有则为DEFAULT
其中n缺省时默认为1,DEFAULT缺省时默认为NULL操作上理解为:将col向下滞后n行 分析函数 lead(col, n, DEFAULT) over() 与lag相反 操作上可理解为:将col向上滞前n行 分析函数 first_value(col) over() 首个取值 分析函数 last_value(col) over() 末个取值。注意,由于不指定窗口范围,会默认为截至当前行,所以经常会出现末个取值为当前值。 指定窗口范围
使用first_value,降序 -
窗口
窗口即为上面函数的
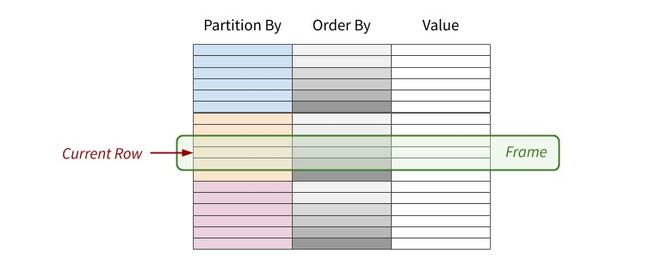
over(),也是窗口函数的核心。partition by col1,col2...对指定字段进行分区,缺省时默认为不分区。order by col1,col2 ...对各分区按指定字段排序,缺省时默认为不排序。具体如下图:
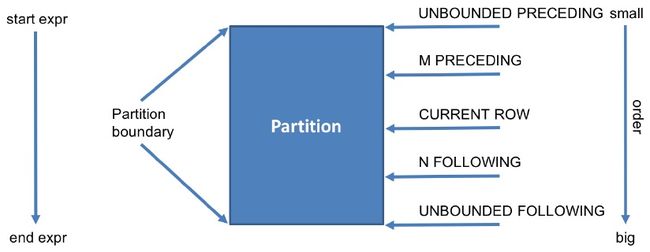
[用于确定窗口边界,即范围。写法为:rows between A and B
其A和B的关键词有:
| 关键词 | 含义 |
|---|---|
| preceding | 往前 |
| following | 往后 |
| current row | 当前行 |
| unbounded | 起点 |
关键词可以组合:如A的常见关键词有
| 关键词 | 含义 |
|---|---|
| m preceding | 往前m行 |
| unbounded preceding | 往后到起点 |
| current row | 当前行 |
B的常见关键词有
| 关键词 | 含义 |
|---|---|
| n following | 往后n行 |
| unbounded following | 往后到终点 |
| current row | 当前行 |
窗口边界详细如下图:
现在再重新回到窗口函数的整体上来,你会发现它实际上是先将数据分为多个分区,每个区按指定字段排序,最后对排序好的 分区数据选定边界进行函数计算。举几个简单的例子:
- 查看每个商店
shop近三个月mon的收入sales和:sum(sales) over(partition by shop order by mon rows between 3 preceding and unbounded preceding)
- 查看每个商店
shop从现在到最后日期mon的收入sales和:sum(sales) over(partition by shop order by mon rows between current row and unbounded following)
- 查看每个商店
shop截止当前日期mon的收入sales和:即累积收入计算sum(sales) over(partition by shop order by mon rows between unbounded preceding and current row)
- 查看每个商店
shop所有日期mon的收入sales和:即总收入计算sum(sales) over(partition by shop order by mon rows between unbounded preceding and unbounded following)
是不是发现你已经可以任意的进行窗口操作了,但是你也会发现,每次都写窗口边界很繁琐,能不能像partition by和 order by一样缺省操作呢。
当然可以,事实上使用场景最多的就是上面的3和4,即cume累积和total总体。因此当不写[时,如 果指定了order by,则相当于rows between unbounded preceding and current row,这就解释了上面last_value 函数的使用问题;如果缺省了order by,则相当于rows between unbounded preceding and unbounded following。现在再改写下3和4如下:
- 查看每个商店
shop截止当前日期mon的收入sales和:即累积收入计算sum(sales) over(partition by shop order by mon)
- 查看每个商店
shop所有日期mon的收入sales和:即总收入计算sum(sales) over(partition by shop)
- 查看所有
shop所有日期mon的收入sales和sum(sales) over()
- 查看所有
shop截止当前日期mon的累积收入sales和sum(sales) over(order by mon)
自定义函数UDF
虽然Hive函数众多,但面对日益复杂的数据需求也有不够用的时候。例如截尾平均数、众数等,虽然可以按照统计逻辑计算出来,但如果需要频繁使用,或者与全局汇总(下面的group 强化)一起连用时就会比较麻烦,因此就可以选择自定义一个所需的函数了。
当然,开发UDF是需要找数仓帮忙的。有问题,找数仓准行~
group强化
相信大家在Excel(或Tableau)中做数据透视表的时候,可以对任意维度的数据进行聚合。有时候业务也希望能拿到逐级汇总好的数据,这样就不用在拿到数据后再做一次数据透视了,尤其是需要去重后计数的指标是没法再做数据透视的。
Hive根据日常使用场景开发了三种group 强化功能,自由维度聚合的grouping sets;全维度聚合的cube;维度递减聚合的rollup。其中最常用的则是cube。
⚠️注意:Hive在做group 强化时,会将不参与聚合的字段默认置为NULL。如果不参与聚合的字段本身也含有NULL,那group 强化后的结果就会出现两行NULL,很多同学看到结果后就开始怀疑人生了。
因此在实际操作中,在做group 强化之前,应将明细数据中每个维度的NULL值进行替换为’未知’,用于标记维度本身的取值;group 强化之后,应将每个维度的NULL值再进行替换为’全部’,用以标记group 强化后的维度取值。
为便于介绍三种group 强化,以下示例的数据均为temp:
| a | b | c | d |
|---|---|---|---|
| a1 | b1 | c1 | 1 |
| a1 | b2 | c1 | 2 |
| a2 | b3 | null | 3 |
| null | b3 | c2 | null |
自由维度聚合(grouping sets)
select
coalesce(a,'全部') as a
,coalesce(b,'全部') as b
,coalesce(c,'全部') as c
,sum(d) as d
from
(
select
coalesce(a,'未知') as a -- 对所有参与强化聚合的维度进行null替换
,coalesce(b,'未知') as b -- 虽然b字段本身没有null值,但为了防止异常数据,也需要进行null替换
,coalesce(c,'未知') as c -- 对所有参与强化聚合的维度进行null替换
,d -- 聚合计算的字段(非维度)无需处理
from
temp
)a
group by -- 所有参与强化聚合的维度
a
,b
,c
grouping sets -- 任意组合维度
(
(a,b,c) -- 对a,b,c进行group by
,(a) -- 对a进行group by
,(a,b) -- 对对a,b进行group by
,(a,c) -- 对a,c进行group by
,() -- 对整体进行group by
)
上述可以理解为对不同组合的group by结果进行了union all。其结果如下:其中’未知’为维度自身的NULL,'全部’为group 强化后的NULL

全维度组合(cube)
select
coalesce(a,'全部') as a
,coalesce(b,'全部') as b
,coalesce(c,'全部') as c
,sum(d) as d
from
(
select
coalesce(a,'未知') as a -- 对所有参与强化聚合的维度进行null替换
,coalesce(b,'未知') as b -- 虽然b字段本身没有null值,但为了防止异常数据,也需要进行null替换
,coalesce(c,'未知') as c -- 对所有参与强化聚合的维度进行null替换
,d -- 聚合计算的字段(非维度)无需处理
from
temp
)a
group by -- 所有参与强化聚合的维度
a
,b
,c
with cube
其结果可理解为对[a,b,c]的所有组合。然后将所有组合写入grouping sets里。例如这里就可以看作:
grouping sets -- 任意组合维度
(
()
,(a)
,(b)
,(c)
,(a,b)
,(a,c)
,(b,c)
,(a,b,c)
)
维度递减聚合(rollup)
select
coalesce(a,'全部') as a
,coalesce(b,'全部') as b
,coalesce(c,'全部') as c
,sum(d) as d
from
(
select
coalesce(a,'未知') as a -- 对所有参与强化聚合的维度进行null替换
,coalesce(b,'未知') as b -- 虽然b字段本身没有null值,但为了防止异常数据,也需要进行null替换
,coalesce(c,'未知') as c -- 对所有参与强化聚合的维度进行null替换
,d -- 聚合计算的字段(非维度)无需处理
from
temp
)a
group by -- 所有参与强化聚合的维度
a
,b
,c
with rollup
其结果可理解为对[a,b,c]的逐级递减的所有组合。然后将所有组合写入grouping sets里。例如这里就可以看作
grouping sets -- 任意组合维度
(
(a,b,c)
,(a,b)
,(a)
,()
)
⚠️注意:Hive默认只支持值四个维度的group 强化,如果超过四个,则需要设置参数进行自定义:
set hive.new.job.grouping.set.cardinality=256; -- 8个维度,256为2的8次方。
创建临时表小妙招
最后,分享给大家一个创建临时表的小妙招。相信大家在日常中都会构建临时数据来做一些校验,例如验证函数是否符合要求,正则是否符合预期,逻辑是否正确等。那常见的方法就是creat table temp,然后用insert、as select、上传文件等方式构建自己想要的数据。但是如果只是做简单的校验数据就显得大材小用了,而且频繁creat table temp不仅麻烦,还一点都不Geek。
Hive的wih table_name as 主要是用来优化SQL的。因为在业务中,有些SubQuery需要被反复使用,但使用场景也仅限于当前SQL,为此开发中间表就显得不值当。因此就可以通过wih table_name as在SQL中构建临时表(类似于函数),方便后续调用,这样就极大的提升了代码的整洁性和可读性。
例如上面的group 强化就可以用以下代码简单验证
with temp as
(
select 'a1' as a, 'b1' as b, 'c1' as c, 1 as d -- 一个select代表一行数据
union all -- 一个union all类似于一个inser into
select 'a1' as a, 'b2' as b, 'c1' as c, 2 as d
union all
select 'a2' as a, 'b3' as b, null as c, 3 as d
union all
select null as a, 'b3' as b, 'c2' as c, null as d
)
select
coalesce(a,'全部') as a
,coalesce(b,'全部') as b
,coalesce(c,'全部') as c
,sum(d) as d
from
(
select
coalesce(a,'未知') as a -- 对所有参与强化聚合的维度进行null替换
,coalesce(b,'未知') as b -- 虽然b字段本身没有null值,但为了防止异常数据,也需要进行null替换
,coalesce(c,'未知') as c -- 对所有参与强化聚合的维度进行null替换
,d -- 聚合计算的字段(非维度)无需处理
from
temp -- 调用上面生成的临时表temp
)a
group by -- 所有参与强化聚合的维度
a
,b
,c
with cube
如果需要生成两张或多张表,只需要些多个table_name即可。注意每个临时表需要用括号框住,之间用,分隔开,最后一个临时表后不需要,,直接跟select语句即可(必须要跟select语句,否则会报错)。示例如下:
with `user` as -- 当别名与内部关键字冲突,需要用反引号``转义
(
select 1 as id
union all
select 2 as id
),
user_active_info as
(
select 1 as id, 'a' as exercise
union all
select 1 as id, 'b' as exercise
)
select * from `user` ui left join user_active_info uai on ui.id=uai.id
总结
本文看似很多,实则只介绍了Hive的几个语法差异,一些常见的函数,对重点高频函数也加粗标记了。并且介绍了几个group 强化,并建议尝试用wih table_name as构建简单临时表。当这些已经了然于胸的时候,相信你做需求的效率肯定杠杠滴~
共勉~