基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(三)
目录
- 前言
- 总体设计
- 运行环境
-
- Python环境
- 依赖库
- 模块实现
-
- 1. 疾病预测
- 2. 药物推荐
- 3. 模型测试
-
- 1)模型导入
- 2)相关代码
-
- (1)模型预测
- (2)模型应用创新
- (3)用户接口及界面可视化代码
- 系统测试
-
- 1. 训练准确度
- 2. 测试效果
- 3. 模型应用
- 其它相关博客
- 工程源代码下载
- 其它资料下载

前言
本项目基于Kaggle上公开的数据集,旨在对心脏病和慢性肾病进行深入的特征筛选和提取。它利用了随机森林机器学习模型,通过对这些特征进行训练,能够预测是否患有这些疾病。不仅如此,该项目还会根据患者的症状或需求,提供相关的药物推荐,从而实现了一款实用性强的智能医疗助手。
首先,项目收集了来自Kaggle的公开数据集,这些数据包含了与心脏病和慢性肾病相关的丰富信息。然后,通过数据预处理和特征工程,从这些数据中提取出最相关的特征,以用于机器学习模型的训练。
接下来,项目采用了随机森林机器学习模型,这是一种强大的分类算法。通过使用训练数据,模型能够学习不同特征与心脏病和慢性肾病之间的关联。一旦模型经过训练,它可以对新的患者数据进行预测,判断患者是否有这些疾病。
除了疾病预测,该项目还具备一个药物推荐系统。基于患者的症状、需求和疾病诊断,系统会推荐适合的药物和治疗方案,以提供更全面的医疗支持。
综合来看,这个项目不仅可以预测心脏病和慢性肾病,还可以提供个性化的治疗建议。这种智能医疗助手有望提高医疗决策的准确性,为患者提供更好的医疗体验,并对医疗资源的合理分配起到积极作用。
总体设计
本部分包括系统整体结构图和系统流程图。
运行环境
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
依赖库
使用下面命令安装:
pip install pandas
模块实现
本项目包括2个功能,每个功能有3个模块:疾病预测、药物推荐、模块应用,下面分别给出各模块的功能介绍及相关代码。
1. 疾病预测
本模块是一个小型健康预测系统,预测两种疾病心脏病和慢性肾病。
2. 药物推荐
本模块是一个小型药物推荐系统,对800余种症状提供药物推荐。
3. 模型测试
本部分包括模型导入及相关代码。
1)模型导入
输入数据包括两部分:如性别、年龄、食欲需要用户手动输入;心率、心电图波形参数,需要用户接入不同的传感器测量。考虑到应用的便捷性,直接从传感器读取所有的参数进行预测。
一位用户输入的数据如图11所示,判决结果如图12所示。


client_result=rf.predict(client_x)
print('这就是分类预测结果')
print(client_result )
根据数据和模型,首先判断病与非病;其次判断病情严重程度,不能只用是否有病,而是给病情不同程度的评价。将数据乘以每个因素的权重和有病的人平均值做对比。如果直接告诉-一个人,得病了,可能无法接受。如果说明情况不太严重,比大多数病人轻,量化后,容易接
受,如图所示。

之前平均值是病人比正常人的小,所以大于分界面更好。病情指数比平均数的四分之一还小,量化后督促病人抓紧时间治疗。
2)相关代码
本部分包括模型预测代码、模型应用创新代码、用户接口及界面可视化代码。
(1)模型预测
心脏病预测模型建模,相关代码如下:
#心脏病预测模型建模
#导入所用库函数及数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import os
#读入数据集中数据
df = pd.read_csv("C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/heart.csv")
#输出读入的数据
df.head()
#检查是否有缺省值
df.loc[(df['age'].isnull()) |
(df['sex'].isnull()) |
(df['cp'].isnull()) |
(df['trestbps'].isnull()) |
(df['chol'].isnull()) |
(df['fbs'].isnull()) |
(df['restecg'].isnull()) |
(df['thalach'].isnull()) |
(df['exang'].isnull()) |
(df['oldpeak'].isnull()) |
(df['slope'].isnull()) |
(df['ca'].isnull()) |
(df['target'].isnull())]
#通过绘图方式观察数据,能够更好的观察是否有错误
sns.pairplot(df.dropna(), hue='target')
#对血液中胆固醇含量绘制数据分布图
df['chol'].hist()
#对静息血压绘制数据分布图
df['trestbps'].hist()
#将类别变量转换为伪变量
a = pd.get_dummies(df['cp'], prefix = "cp")
b = pd.get_dummies(df['thal'], prefix = "thal")
c = pd.get_dummies(df['slope'], prefix = "slope")
frames = [df, a, b, c]
df = pd.concat(frames, axis = 1)
#数据集可视化
df.head()
#将原来的类别变量删掉,只保留伪变量
df = df.drop(columns = ['cp', 'thal', 'slope'])
#数据集可视化
df.head()
#数据预处理完成,选择、训练并保存模型
#target是标签
y = df.target.values
x_data = df.drop(['target'], axis = 1) #丢下最后一行target
#划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(x_data,y,test_size = 0.2,random_state=0)
x_train = x_train.T
y_train = y_train.T
x_test = x_test.T
y_test = y_test.T
#创建数组,带入随机森林模型中迭代
import numpy as np
num=np.zeros(20,int)
for i in range(0,20):
num[i]=i+990
print(num)
#寻找最优参数
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
tuned_parameters = [{'n_estimators':num,
'class_weight':[None,{0: 0.33,1:0.67},'balanced'],'random_state':[1]}]
rf = GridSearchCV(RandomForestClassifier(), tuned_parameters, cv=10,scoring='f1')
rf.fit(x_train.T, y_train.T)
#输出找到的最优参数
print('Best parameters:')
print(rf.best_params_)
rf_best = rf.best_estimator_
#带入最优参数的随机森林模型
accuracies = {}
rf_best.fit(x_train.T, y_train.T)
acc = rf.score(x_test.T,y_test.T)*100
accuracies['Random Forest'] = acc
#输出模型准确率
print("Random Forest Algorithm Accuracy Score : {:.2f}%".format(acc))
#绘制混淆矩阵
y_head_rf = rf_best.predict(x_test.T)
from sklearn.metrics import confusion_matrix
cm_rf = confusion_matrix(y_test,y_head_rf)
#图像大小4*4
plt.figure(figsize=(4,4))
plt.title("Random Forest Confusion Matrix")
sns.heatmap(cm_rf,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size": 24})
plt.show()
#绘制ROC曲线
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_head_rf)
fig, ax = plt.subplots()
ax.plot(fpr, tpr)
ax.plot([0, 1], [0, 1], transform=ax.transAxes, ls="--", c=".3")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.rcParams['font.size'] = 12
plt.title('ROC curve for diabetes classifier')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity)')
plt.grid(True)
#ROC曲线图的面积
auc(fpr, tpr)
慢性肾病数据集训练模型建模,相关代码如下:
#慢性肾病数据集训练模型建模
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import roc_curve, auc, confusion_matrix, classification_report,accuracy_score
from sklearn.ensemble import RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
#%matplotlib inline
#读入数据集并可视化
df = pd.read_csv('C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/kidney_disease.csv')
df.head()
#数据预处理,将类别变量转换为伪变量
df[['htn','dm','cad','pe','ane']] = df[['htn','dm','cad','pe','ane']].replace(to_replace={'yes':1,'no':0})
df[['rbc','pc']]=df[['rbc','pc']].replace(to_replace={'abnormal':1,'normal':0})
df[['pcc','ba']]=df[['pcc','ba']].replace(to_replace={'present':1,'notpresent':0})
df[['appet']]=df[['appet']].replace(to_replace={'good':1,'poor':0,'no':np.nan})
df['classification']=df['classification'].replace(to_replace={'ckd':1.0,'ckd\t':1.0,'notckd':0.0,'no':0.0})
df.rename(columns={'classification':'class'},inplace=True)
#进一步清洗
df['pe'] = df['pe'].replace(to_replace='good',value=0)
df['appet']=df['appet'].replace(to_replace='no',value=0)
df['cad']=df['cad'].replace(to_replace='\tno',value=0)
df['dm']=df['dm'].replace(to_replace={'\tno':0,'\tyes':1,' yes':1, '':np.nan})
df.drop('id',axis=1,inplace=True)
df.head()
#列出所有null的数据
df.loc[(df['age'].isnull()) |
(df['bp'].isnull()) |
(df['sg'].isnull()) |
(df['al'].isnull()) |
(df['su'].isnull()) |
(df['rbc'].isnull()) |
(df['pc'].isnull()) |
(df['pcc'].isnull()) |
(df['ba'].isnull()) |
(df['bgr'].isnull()) |
(df['bu'].isnull()) |
(df['sc'].isnull()) |
(df['sod'].isnull()) |
(df['pot'].isnull()) |
(df['hemo'].isnull()) |
(df['htn'].isnull()) |
(df['dm'].isnull()) |
(df['cad'].isnull()) |
(df['appet'].isnull()) |
(df['pe'].isnull()) |
(df['ane'].isnull()) |
(df['class'].isnull())]
#出现空缺值,采用均值归一法,填补缺失值
#病人均值
average0_age = df.loc[df['class'] ==True, 'age'].mean()
average0_bp = df.loc[df['class'] == True, 'bp'].mean()
average0_sg = df.loc[df['class'] == True, 'sg'].mean()
average0_al = df.loc[df['class'] == True, 'al'].mean()
average0_su = df.loc[df['class'] == True, 'su'].mean()
average0_rbc = df.loc[df['class'] == True, 'rbc'].mean()
average0_pc = df.loc[df['class'] == True, 'pc'].mean()
average0_pcc = df.loc[df['class'] == True, 'pcc'].mean()
average0_ba = df.loc[df['class'] == True, 'ba'].mean()
average0_bgr = df.loc[df['class'] == True, 'bgr'].mean()
average0_bu = df.loc[df['class'] == True, 'bu'].mean()
average0_sc = df.loc[df['class'] == True, 'sc'].mean()
average0_sod = df.loc[df['class'] == True, 'sod'].mean()
average0_pot = df.loc[df['class'] == True, 'pot'].mean()
average0_hemo = df.loc[df['class'] == True, 'hemo'].mean()
average0_htn = df.loc[df['class'] == True, 'htn'].mean()
average0_dm = df.loc[df['class'] == True, 'dm'].mean()
average0_cad = df.loc[df['class'] == True, 'cad'].mean()
average0_appet = df.loc[df['class'] ==True, 'appet'].mean()
average0_pe = df.loc[df['class'] == True, 'pe'].mean()
average0_ane = df.loc[df['class'] == True, 'ane'].mean()
#正常人均值
average1_age = df.loc[df['class'] == False, 'age'].mean()
average1_bp = df.loc[df['class'] == False, 'bp'].mean()
average1_sg = df.loc[df['class'] == False, 'sg'].mean()
average1_al = df.loc[df['class'] == False, 'al'].mean()
average1_su = df.loc[df['class'] == False, 'su'].mean()
average1_rbc = df.loc[df['class'] == False, 'rbc'].mean()
average1_pc = df.loc[df['class'] == False, 'pc'].mean()
average1_pcc = df.loc[df['class'] == False, 'pcc'].mean()
average1_ba = df.loc[df['class'] == False, 'ba'].mean()
average1_bgr = df.loc[df['class'] == False, 'bgr'].mean()
average1_bu = df.loc[df['class'] == False, 'bu'].mean()
average1_sc = df.loc[df['class'] == False, 'sc'].mean()
average1_sod = df.loc[df['class'] == False, 'sod'].mean()
average1_pot = df.loc[df['class'] == False, 'pot'].mean()
average1_hemo = df.loc[df['class'] == False, 'hemo'].mean()
average1_htn = df.loc[df['class'] == False, 'htn'].mean()
average1_dm = df.loc[df['class'] == False, 'dm'].mean()
average1_cad = df.loc[df['class'] == False, 'cad'].mean()
average1_appet = df.loc[df['class'] == False, 'appet'].mean()
average1_pe = df.loc[df['class'] == False, 'pe'].mean()
average1_ane = df.loc[df['class'] == False, 'ane'].mean()
#如果为null,则取均值
df.loc[(df['class'] ==True) &(df['age'].isnull()),'age'] = average0_age
df.loc[(df['class'] ==True) &(df['bp'].isnull()),'bp'] = average0_bp
df.loc[(df['class'] ==True) &(df['sg'].isnull()),'sg'] = average0_sg
df.loc[(df['class'] ==True) &(df['al'].isnull()),'al'] = average0_al
df.loc[(df['class'] ==True) &(df['su'].isnull()),'su'] = average0_su
df.loc[(df['class'] ==True) &(df['rbc'].isnull()),'rbc'] = average0_rbc
df.loc[(df['class'] ==True) &(df['pc'].isnull()),'pc'] = average0_pc
df.loc[(df['class'] ==True) &(df['pcc'].isnull()),'pcc'] = average0_pcc
df.loc[(df['class'] ==True) &(df['ba'].isnull()),'ba'] = average0_ba
df.loc[(df['class'] ==True) &(df['bgr'].isnull()),'bgr'] = average0_bgr
df.loc[(df['class'] ==True) &(df['bu'].isnull()),'bu'] = average0_bu
df.loc[(df['class'] ==True) &(df['sc'].isnull()),'sc'] = average0_sc
df.loc[(df['class'] ==True) &(df['sod'].isnull()),'sod'] = average0_sod
df.loc[(df['class'] ==True) &(df['pot'].isnull()),'pot'] = average0_pot
df.loc[(df['class'] ==True) &(df['hemo'].isnull()),'hemo']=average0_hemo
df.loc[(df['class'] ==True) &(df['htn'].isnull()),'htn'] = average0_htn
df.loc[(df['class'] ==True) &(df['dm'].isnull()),'dm'] = average0_dm
df.loc[(df['class'] ==True) &(df['cad'].isnull()),'cad'] = average0_cad
df.loc[(df['class'] ==True) &(df['appet'].isnull()),'appet'] = average0_appet
df.loc[(df['class'] ==True)&(df['pe'].isnull()),'pe'] = average0_pe
df.loc[(df['class'] ==True) &(df['ane'].isnull()),'ane'] = average0_ane
df.loc[(df['class'] ==False) &(df['age'].isnull()),'age'] = average1_age
df.loc[(df['class'] ==False) &(df['bp'].isnull()),'bp'] = average1_bp
df.loc[(df['class'] ==False) &(df['sg'].isnull()),'sg'] = average1_sg
df.loc[(df['class'] ==False) &(df['al'].isnull()),'al'] = average1_al
df.loc[(df['class'] ==False) &(df['su'].isnull()),'su'] = average1_su
df.loc[(df['class'] ==False) &(df['rbc'].isnull()),'rbc'] = average1_rbc
df.loc[(df['class'] ==False) &(df['pc'].isnull()),'pc'] = average1_pc
df.loc[(df['class'] ==False) &(df['pcc'].isnull()),'pcc'] = average1_pcc
df.loc[(df['class'] ==False) &(df['ba'].isnull()),'ba'] = average1_ba
df.loc[(df['class'] ==False) &(df['bgr'].isnull()),'bgr'] = average1_bgr
df.loc[(df['class'] ==False) &(df['bu'].isnull()),'bu'] = average1_bu
df.loc[(df['class'] ==False) &(df['sc'].isnull()),'sc'] = average1_sc
df.loc[(df['class'] ==False) &(df['sod'].isnull()),'sod'] = average1_sod
df.loc[(df['class'] ==False) &(df['pot'].isnull()),'pot'] = average1_pot
df.loc[(df['class'] ==False) &(df['hemo'].isnull()),'hemo'] = average1_hemo
df.loc[(df['class'] ==False) &(df['htn'].isnull()),'htn'] = average1_htn
df.loc[(df['class'] ==False) &(df['dm'].isnull()),'dm'] = average1_dm
df.loc[(df['class'] ==False) &(df['cad'].isnull()),'cad'] = average1_cad
df.loc[(df['class'] ==False) &(df['appet'].isnull()),'appet'] = average1_appet
df.loc[(df['class'] ==False) &(df['pe'].isnull()),'pe'] = average1_pe
df.loc[(df['class'] ==False) &(df['ane'].isnull()),'ane'] = average1_ane
#重新检查是否有缺省值
df.loc[(df['age'].isnull()) |
(df['bp'].isnull()) |
(df['sg'].isnull()) |
(df['al'].isnull()) |
(df['su'].isnull()) |
(df['rbc'].isnull()) |
(df['pc'].isnull()) |
(df['pcc'].isnull()) |
(df['ba'].isnull()) |
(df['bgr'].isnull()) |
(df['bu'].isnull()) |
(df['sc'].isnull()) |
(df['sod'].isnull()) |
(df['pot'].isnull()) |
(df['hemo'].isnull()) |
(df['htn'].isnull()) |
(df['dm'].isnull()) |
(df['cad'].isnull()) |
(df['appet'].isnull()) |
(df['pe'].isnull()) |
(df['ane'].isnull()) |
(df['class'].isnull())]
#划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:,:-1], df['class'], test_size = 0.33, random_state=44,stratify= df['class'] )
print(X_train.shape)
print(X_test.shape)
#寻找随机森林最优参数
tuned_parameters = [{'n_estimators':[7,8,9,10,11,12,13,14,15,16],'max_depth':[2,3,4,5,6,None],'class_weight':[None,{0: 0.33,1:0.67},'balanced'],'random_state':[42]}]
clf = GridSearchCV(RandomForestClassifier(), tuned_parameters, cv=10,scoring='f1')
clf.fit(X_train, y_train)
#输出最佳参数
print('Best parameters:')
print(clf.best_params_)
clf_best = clf.best_estimator_
#将最优参数代入随机森林模型
accuracies = {}
rf = RandomForestClassifier(class_weight=None, max_depth= 6,n_estimators = 7, random_state = 42)
rf.fit(X_train, y_train)
#计算模型准确率
acc = rf.score(X_test, y_test)*100
accuracies['Random Forest'] = acc
print("Random Forest Algorithm Accuracy Score : {:.2f}%".format(acc))
药物评论情感分析建模,相关代码如下:
#药物评论情感分析建模
#导入库函数
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style; style.use('ggplot')
import re
import xgboost as xgb
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score
from sklearn.naive_bayes import MultinomialNB, GaussianNB
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.feature_selection import chi2, SelectKBest
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from wordcloud import WordCloud, STOPWORDS
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.utils import to_categorical
#读入训练集和测试集
train = pd.read_csv('C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/drugsComTrain_raw.csv')
test = pd.read_csv('C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/drugsComTest_raw.csv')
#输出可视化
print('全部评论数:')
print(len(train))
print(len(test))
#仅保留评分为1和10分两端的评论
X_train=train[train.rating.isin([1,10])]
X_train.head()
X_test=test[test.rating.isin([1,10])]
X_test.head()
#编写去除评论中引号的函数
def remove_enclosing_quotes(s):
if s[0] == '"' and s[-1] == '"':
return s[1:-1]
else:
return s
#调用函数
train.review = train.review.apply(remove_enclosing_quotes)
test.review = test.review.apply(remove_enclosing_quotes)
#用正则表达式去除乱码,防止对后续分隔句子造成影响
import re
train.review = train.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
test.review = test.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
#编写函数,将症状,药物写进评论中,拼成一个整体
def combine_text_columns(data_frame, text_cols):
text_data = data_frame[text_cols]
text_data.fillna("", inplace=True)
return text_data.apply(lambda x: " ".join(x), axis=1)
#调用函数
text_cols = ['drugName', 'condition', 'review']
train['text'] = combine_text_columns(train, text_cols)
test['text'] = combine_text_columns(test, text_cols)
#过滤规则,token的正则表达式
TOKENS_ALPHANUMERIC = '[A-Za-z0-9]+(?=\\s+)'
#CountVectorizer 类将文本中的词语转换为词频矩阵
vec_alphanumeric = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC, ngram_range=(1,2), lowercase=True, stop_words='english', min_df=2, max_df=0.99)
#转换transform,从而实现数据的标准化、归一化
X = vec_alphanumeric.fit_transform(train.text)
#将1和10分评论二分类,归位两堆
train['binary_rating'] = train['rating'] > 5
y = train.binary_rating
#划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, stratify=y, test_size=0.1)
#逻辑回归训练模型
clf_lr = LogisticRegression(penalty='l2', C=100).fit(X_train, y_train)
pred = clf_lr.predict(X_test)
#模型在训练集准确率
print("Accuracy on training set: {}".format(clf_lr.score(X_train, y_train)))
#模型在测试集准确率
print("Accuracy on test set: {}".format(clf_lr.score(X_test, y_test)))
#绘制混淆矩阵
print("Confusion Matrix")
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
(2)模型应用创新
相关代码如下:
#得到心脏病数据集中特征重要性
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(rf, random_state=1).fit(x_test.T, y_test.T)
eli5.show_weights(perm, feature_names = x_test.T.columns.tolist())
#得到正常人和患者均值
df.groupby('target').mean()
#正常人平均水平
average0_count=np.multiply(average0,w)
average0_sum=sum(average0_count)
#病人平均水平
average1_count=np.multiply(average1,w)
average1_sum=sum(average1_count)
#得到慢性肾病数据集中特征重要性
import eli5 #for purmutation importance
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(rf, random_state=1).fit(X_test, y_test)
eli5.show_weights(perm, feature_names = X_test.columns.tolist())
df.groupby('class').mean()
#病人平均水平
average0_count=np.multiply(average0,w)
average0_sum=sum(average0_count)
#正常人平均水平
average1_count=np.multiply(average1,w)
average1_sum=sum(average1_count)
#对感情不明确的进行情感分析
train_0 = pd.read_csv('C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/drugsComTrain_raw.csv')
test_0 = pd.read_csv('C:/Users/Administrator/Desktop/dasanxia/Thursday9 10 11/drugsComTest_raw.csv')
#仅读入打分为2~9的评论
train_0=train_0[train_0.rating.isin([2,3,4,5,6,7,8,9])]
test_0=test_0[test_0.rating.isin([2,3,4,5,6,7,8,9])]
#去除双引号
train_0.review = train_0.review.apply(remove_enclosing_quotes)
test_0.review = test_0.review.apply(remove_enclosing_quotes)
#去除特殊字符
train_0.review = train_0.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
test_0.review = test_0.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
#将症状、药物与评论三者融为一段文字
train_0['text'] = combine_text_columns(train_0, text_cols)
test_0['text'] = combine_text_columns(test_0, text_cols)
#数据归一化
X_0 = vec_alphanumeric.fit_transform(train.text)
#调用模型进行预测
pred_0 = clf_lr.predict(X_0)
#输出预测结果
print(pred_0)
(3)用户接口及界面可视化代码
本部分为主界面GUI设计及子界面调用。
#导入库函数
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtCore import QCoreApplication
#GUI界面大小,按键设置
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(1600, 1000)
Dialog.setFixedSize(1600, 1000)
self.label = QtWidgets.QLabel(Dialog)
self.label.setGeometry(QtCore.QRect(680, 60, 250, 61))
self.label.setObjectName("label")
self.label.setStyleSheet('font-size:40px')
self.pushButton = QtWidgets.QPushButton(Dialog)
self.pushButton.setGeometry(QtCore.QRect(720, 300, 150, 50))
self.pushButton.setObjectName("pushButton")
self.pushButton.setStyleSheet('font-size:30px')
self.pushButton_2 = QtWidgets.QPushButton(Dialog)
self.pushButton_2.setGeometry(QtCore.QRect(720, 500, 150, 50))
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_2.setStyleSheet('font-size:30px')
self.pushButton_3 = QtWidgets.QPushButton(Dialog)
self.pushButton_3.setGeometry(QtCore.QRect(720, 800, 150, 50))
self.pushButton_3.setObjectName("pushButton_3")
self.pushButton_3.setStyleSheet('font-size:30px')
self.pushButton_3.clicked.connect(QCoreApplication.instance().quit)
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
#为按键起名字
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "智能健康助手"))
self.label.setText(_translate("Dialog", "智能健康助手"))
self.pushButton.setText(_translate("Dialog", "健康预测"))
self.pushButton_2.setText(_translate("Dialog", "药物推荐"))
self.pushButton_3.setText(_translate("Dialog", "退出程序"))
调用机器学习模型,对用户的数据进行分析,相关代码如下:
#调用机器学习模型,对用户的数据进行分析
#导入库函数
import csv
import pandas as pd
import pickle
import numpy as np
from PyQt5 import QtCore, QtGui, QtWidgets
from databank import result
#GUI界面大小,按键设置
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(1600, 1000)
Dialog.setFixedSize(1600,1000)
self.label = QtWidgets.QLabel(Dialog)
self.label.setGeometry(QtCore.QRect(650,40,300,80)) #标签位置及大小
self.label.setTextFormat(QtCore.Qt.AutoText)
self.label.setAlignment(QtCore.Qt.AlignCenter)
self.label.setObjectName("label")
self.label.setStyleSheet('font-size:40px')
self.age = QtWidgets.QLabel(Dialog)
self.age.setGeometry(QtCore.QRect(700, 200, 200, 40))
self.age.setObjectName("age")
self.age.setStyleSheet('font-size:30px')
self.ageinput = QtWidgets.QLineEdit(Dialog)
self.ageinput.setGeometry(QtCore.QRect(850, 200, 50, 40))
self.ageinput.setObjectName("ageinput")
agelimit = QtCore.QRegExp("[1-9][0-9]{1,2}")
age_validator = QtGui.QRegExpValidator(agelimit, self.ageinput)
self.ageinput.setValidator(age_validator)
font = QtGui.QFont()
font.setPointSize(20)
self.ageinput.setFont(font)
self.sex = QtWidgets.QLabel(Dialog)
self.sex.setGeometry(QtCore.QRect(700, 300, 200, 40))
self.sex.setObjectName("sex")
self.sex.setStyleSheet('font-size:30px')
self.sexinput = QtWidgets.QComboBox(Dialog)
self.sexinput.setGeometry(QtCore.QRect(850, 300, 60, 45))
self.sexinput.setObjectName("sexinput")
self.sexinput.addItem("")
self.sexinput.addItem("")
self.sexinput.setStyleSheet('font-size:30px')
self.taste = QtWidgets.QLabel(Dialog)
self.taste.setGeometry(QtCore.QRect(700, 400, 200, 40))
self.taste.setObjectName("taste")
self.taste.setStyleSheet('font-size:30px')
self.tasteinput = QtWidgets.QComboBox(Dialog)
self.tasteinput.setGeometry(QtCore.QRect(850, 400, 100, 45))
self.tasteinput.setObjectName("tasteinput")
self.tasteinput.addItem("")
self.tasteinput.addItem("")
self.tasteinput.setStyleSheet('font-size:30px')
self.pushButton = QtWidgets.QPushButton(Dialog)
self.pushButton.setGeometry(QtCore.QRect(750, 800, 100, 40))
self.pushButton.setObjectName("pushButton")
self.pushButton.setStyleSheet('font-size:30px')
self.pushButton.clicked.connect(self.do)
self.Button = QtWidgets.QPushButton(Dialog)
self.Button.setGeometry(QtCore.QRect(700, 700, 200, 40))
self.Button.setObjectName("Button")
self.Button.setStyleSheet('font-size:30px')
self.Button.clicked.connect(self.get)
self.Button2 = QtWidgets.QPushButton(Dialog)
self.Button2.setGeometry(QtCore.QRect(750, 950, 100, 40))
self.Button2.setObjectName("Button")
self.Button2.setStyleSheet('font-size:30px')
self.label_2 = QtWidgets.QLabel(Dialog)
self.label_2.setGeometry(QtCore.QRect(900, 700, 200, 40))
self.label_2.setStyleSheet('font-size:30px')
self.label_2.setObjectName("label_2")
self.progressBar = QtWidgets.QProgressBar(Dialog)
self.progressBar.setGeometry(QtCore.QRect(760, 900, 118, 23))
self.progressBar.setProperty("value", 0)
self.progressBar.setObjectName("progressBar")
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
#读入用户输入数据
def get(self):
age = self.ageinput.text()
sex = self.sexinput.currentIndex()
taste = self.tasteinput.currentIndex()
a = [age,sex,145,233,1,0,150,0,2.3,0,0,0,0,1,0,1,0,0,1,0,0]
b=[age,80,1.02,1,0,0.439252336,0,0,0,121,36,1.2,133.9017857,4.878443114,15.4,1,1,0,taste,0,0]
#将用户数据输出到csv文件,并进行定性化分析
with open('./databank/test.csv', "a",newline='') as file:
csv_file = csv.writer(file)
csv_file.writerow(a)
file.close()
with open('./databank/test2.csv', "a",newline='') as file:
csv_file = csv.writer(file)
csv_file.writerow(b)
file.close()
self.label_2.setText(QtCore.QCoreApplication.translate("Dialog", "写入成功"))
self.progressBar.setProperty("value", 0)
#对用户数据定量化分析
def caculate1(self,client1,client_result1,):
#判断病情,数据来源于模型
average1_sum = 2.94673976 #病人
average0_sum = 3.12316913 #正常人
#权重矩阵
w = np.ones((21, 1))
w[0, 0] = 0.0066 #client_x['age']
w[1, 0] = 0.059 #client_x['ca']
w[2, 0] = 0.0033 #client_x['chol']
w[3, 0] = 0.0590 #client_x['cp_0']
w[4, 0] = 0 #client_x['cp_1']
w[5, 0] = 0.0197 #client_x['cp_2']
w[6, 0] = 0.0131 #client_x['cp_3']
w[7, 0] = -0.0033 #client_x['exang']
w[8, 0] = -0.0033 #client_x['fbs']
w[9, 0] = 0.0098 #client_x['oldpeak']
w[10, 0] = 0.0131 #client_x['restecg']
w[11, 0] = 0.0131 #client_x['trestbps']
w[12, 0] = 0.0098 #client_x['sex']
w[13, 0] = 0 #client_x['slope_0']
w[14, 0] = 0.0033 #client_x['slope_1']
w[15, 0] = 0.0066 #client_x['slope_2']
w[16, 0] = 0 #client_x['thal_0']
w[17, 0] = 0 #client_x['thal_1']
w[18, 0] = 0.0361 #client_x['thal_2']
w[19, 0] = 0.0131 #client_x['thal_3']
w[20, 0] = 0 #client_x['thalach']
#用户数据转化为矩阵
client_message = np.ones((21, 1))
client_message[0, 0] = client1['age']
client_message[1, 0] = client1['ca']
client_message[2, 0] = client1['chol']
client_message[3, 0] = client1['cp_0']
client_message[4, 0] = client1['cp_1']
client_message[5, 0] = client1['cp_2']
client_message[6, 0] = client1['cp_3']
client_message[7, 0] = client1['exang']
client_message[8, 0] = client1['fbs']
client_message[9, 0] = client1['oldpeak']
client_message[10, 0] = client1['restecg']
client_message[11, 0] = client1['trestbps']
client_message[12, 0] = client1['sex']
client_message[13, 0] = client1['slope_0']
client_message[14, 0] = client1['slope_1']
client_message[15, 0] = client1['slope_2']
client_message[16, 0] = client1['thal_0']
client_message[17, 0] = client1['thal_1']
client_message[18, 0] = client1['thal_2']
client_message[19, 0] = client1['thal_3']
client_message[20, 0] = client1['thalach']
client_count = np.multiply(client_message, w)
client_sum = sum(client_count)
#判断用户是否为病人
if client_result1 == 1:
client_index = client_sum / average1_sum
return(client_index)
else:
client_index = client_sum / average0_sum
return(client_index)
#在判断用户是否为病人后继续定量化分析
def caculate2(self,client2,client_result2,):
#判断病情,数据来源于模型
average1_sum = 10.06672071 #病人
average0_sum = 12.62982294 #正常人
#权重矩阵
w = np.ones((21, 1))
w[0, 0] = 0.002 #client_x['age']
w[1, 0] = 0.051 #client_x['bp']
w[2, 0] = 0.0545 #client_x['sg']
w[3, 0] = 0.024 #client_x['al']
w[4, 0] = 0 #client_x['su']
w[5, 0] = 0.179 #client_x['rbc']
w[6, 0] = 0 #client_x['pc']
w[7, 0] = 0 #client_x['pcc']
w[8, 0] = 0 #client_x['ba']
w[9, 0] = 0.028 #client_x['bgr']
w[10, 0] = 0.019 #client_x['bu']
w[11, 0] = 0 #client_x['sc']
w[12, 0] = 0.0025 #client_x['sod']
w[13, 0] = 0 #client_x['pot']
w[14, 0] = 0.1505 #client_x['hemo']
w[15, 0] = 0.08 #client_x['htn']
w[16, 0] = 0.025 #client_x['dm']
w[17, 0] = 0 #client_x['cad']
w[18, 0] = -0.0005 #client_x['appet']
w[19, 0] = 0 #client_x['pe']
w[20, 0] = -0.0005 #client_x['ane']
client_message = np.ones((21, 1))
client_message[0, 0] = client2['age']
client_message[1, 0] = client2['bp']
client_message[2, 0] = client2['sg']
client_message[3, 0] = client2['al']
client_message[4, 0] = client2['su']
client_message[5, 0] = client2['rbc']
client_message[6, 0] = client2['pc']
client_message[7, 0] = client2['pcc']
client_message[8, 0] = client2['ba']
client_message[9, 0] = client2['bgr']
client_message[10, 0] = client2['bu']
client_message[11, 0] = client2['sc']
client_message[12, 0] = client2['sod']
client_message[13, 0] = client2['pot']
client_message[14, 0] = client2['hemo']
client_message[15, 0] = client2['htn']
client_message[16, 0] = client2['dm']
client_message[17, 0] = client2['cad']
client_message[18, 0] = client2['appet']
client_message[19, 0] = client2['pe']
client_message[20, 0] = client2['ane']
client_count = np.multiply(client_message, w)
client_sum = sum(client_count)
#print(client_sum)调试代码
if client_result2 == 1:
client_index = client_sum / average1_sum
return(client_index)
else:
client_index = client_sum / average0_sum
return(client_index)
#输出模型结果,可视化
def do(self):
self.label_2.setText(QtCore.QCoreApplication.translate("Dialog", ""))
#QtWidgets.QMessageBox.about(None, "Warning", "跳转成功")调试代码
client = pd.read_csv("./databank/test.csv")
#QtWidgets.QMessageBox.about(None, "Warning", "打开csv成功")调试代码
with open("./databank/model.pkl", "rb") as f:
rf = pickle.load(f)
list = []
#QtWidgets.QMessageBox.about(None, "Warning", "打开模型成功")调试代码
print(client.shape[0] - 1)
for i in range(0, client.shape[0] - 1):
list.append(i)
client = client.drop(list)
print(client)
#QtWidgets.QMessageBox.about(None, "Warning", "数据载入成功")调试代码
client_result = rf.predict(client)
#QtWidgets.QMessageBox.about(None, "Warning", "预测成功")调试代码
print('这就是分类预测结果')
print(client_result)
self.progressBar.setProperty("value", 25)
self.score1 = self.caculate1(client,client_result)
print("得分结果:", self.score1)
self.progressBar.setProperty("value", 50)
client2 = pd.read_csv("./databank/test2.csv")
with open("./databank/model_kidney.pkl", "rb") as f:
rf2 = pickle.load(f)
list2 = []
for i in range(0, client2.shape[0] - 1):
list2.append(i)
client2 = client2.drop(list)
client2_result = rf.predict(client2)
print('这就是分类预测结果')
print(client2_result)
self.progressBar.setProperty("value", 75)
self.score2 = self.caculate2(client2, client2_result)
print("得分结果:",self.score2)
self.progressBar.setProperty("value", 100)
self.c_widget = QtWidgets.QWidget()
self.c = result.Ui_Dialog() self.c.setupUi(client_result[0],client2_result[0],self.score1[0],self.score2[0],self.c_widget)
self.c.pushButton.clicked.connect(self.c_widget.close)
self.c_widget.show()
#子界面文字设计
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "健康预测系统"))
self.label.setText(_translate("Dialog", "健康预测系统"))
self.age.setText(_translate("Dialog", "您的年龄:"))
self.sex.setText(_translate("Dialog", "您的性别:"))
self.sexinput.setItemText(0, _translate("Dialog", "男"))
self.sexinput.setItemText(1, _translate("Dialog", "女"))
self.taste.setText(_translate("Dialog", "最近食欲:"))
self.tasteinput.setItemText(0, _translate("Dialog", "good"))
self.tasteinput.setItemText(1, _translate("Dialog", "pure"))
self.pushButton.setText(_translate("Dialog", "检测"))
self.Button.setText(_translate("Dialog", "一键获取"))
self.Button2.setText(_translate("Dialog", "返回"))
预测结果可视化,对用户的数据定性+定量进行化分析,相关代码如下:
#预测结果可视化,对用户的数据定性+定量进行化分析
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtCore import QCoreApplication
from PyQt5.QtWidgets import QMessageBox
#疾病预测结果展示子界面GUI设计,大小按键设计
class Ui_Dialog(object):
def setupUi(self, result1,result2,score1,score2,Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(1600, 1000)
Dialog.setFixedSize(1600, 1000)
self.label = QtWidgets.QLabel(Dialog)
self.label.setGeometry(QtCore.QRect(150, 240, 300, 40))
self.label.setObjectName("label")
self.label.setStyleSheet('font-size:35px')
self.label_2 = QtWidgets.QLabel(Dialog)
self.label_2.setGeometry(QtCore.QRect(420, 240, 100, 40))
self.label_2.setObjectName("label_2")
self.label_2.setStyleSheet('font-size:35px')
self.label_3 = QtWidgets.QLabel(Dialog)
self.label_3.setGeometry(QtCore.QRect(100, 400, 537, 213))
self.label_3.setObjectName("label_3")
self.label_4 = QtWidgets.QLabel(Dialog)
self.label_4.setGeometry(QtCore.QRect(950, 240, 300, 40))
self.label_4.setObjectName("label_4")
self.label_4.setStyleSheet('font-size:35px')
self.label_5 = QtWidgets.QLabel(Dialog)
self.label_5.setGeometry(QtCore.QRect(1220, 240, 100, 40))
self.label_5.setObjectName("label_5")
self.label_5.setStyleSheet('font-size:35px')
self.label_6 = QtWidgets.QLabel(Dialog)
self.label_6.setGeometry(QtCore.QRect(900, 400, 537, 213))
self.label_6.setObjectName("label_6")
self.pushButton = QtWidgets.QPushButton(Dialog)
self.pushButton.setGeometry(QtCore.QRect(700, 800, 200, 40))
self.pushButton.setObjectName("pushButton")
self.pushButton.setStyleSheet('font-size:30px')
#需要用到的图片调用地址
self.png1 = QtGui.QPixmap('./databank/healthy1.png')
self.png2 = QtGui.QPixmap('./databank/healthy2.png')
self.png3 = QtGui.QPixmap('./databank/weak1.png')
self.png4 = QtGui.QPixmap('./databank/weak2.png')
self.result1 = result1
self.result2 = result2
self.score1 = score1
self.score2 = score2
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
#对疾病预测结果进行分析,是轻度或重度中毒
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "预测结果"))
self.label.setText(_translate("Dialog", "您心脏的状态是:"))
self.label_4.setText(_translate("Dialog", "您肾脏的状态是:"))
self.pushButton.setText(_translate("Dialog", "退出"))
print(self.score1,self.score2)
if self.result1 == 0:
self.label_2.setText(_translate("Dialog", "健康"))
if self.score1 < 1:
self.label_3.setPixmap(self.png1)
#print函数仅在编译时输出,用于检测程序debug
print("ok")
else :
self.label_3.setPixmap(self.png2)
print("ok")
if self.result2 == 0:
self.label_5.setText(_translate("Dialog", "健康"))
if self.score2 < 1:
self.label_6.setPixmap(self.png1)
print("ok")
else :
self.label_6.setPixmap(self.png2)
print("ok")
if self.result1 == 1:
self.label_2.setText(_translate("Dialog", "虚弱"))
if self.score1 < 1:
self.label_3.setPixmap(self.png3)
print("ok")
else :
self.label_3.setPixmap(self.png4)
print("ok")
if self.result2 == 1:
self.label_5.setText(_translate("Dialog", "虚弱"))
if self.score2 < 1:
self.label_6.setPixmap(self.png3)
print("ok")
else :
self.label_6.setPixmap(self.png4)
print("ok")
药物查询,相关代码如下:
#药物查询
#导入库函数
from PyQt5 import QtCore, QtGui, QtWidgets
from databank import medicineres
#GUI界面大小,按键设置
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(1600, 1000)
Dialog.setFixedSize(1600, 1000)
self.label = QtWidgets.QLabel(Dialog)
self.label.setGeometry(QtCore.QRect(680, 60, 250, 61))
self.label.setObjectName("label")
self.label.setStyleSheet('font-size:40px')
self.label_2 = QtWidgets.QLabel(Dialog)
self.label_2.setGeometry(QtCore.QRect(640, 200, 450, 400))
self.label_2.setObjectName("label_2")
self.label_2.setStyleSheet('font-size:25px')
self.pushButton_3 = QtWidgets.QPushButton(Dialog)
self.pushButton_3.setGeometry(QtCore.QRect(720, 800, 150, 50))
self.pushButton_3.setObjectName("pushButton_3")
self.pushButton_3.setStyleSheet('font-size:30px')
self.pushButton_3.clicked.connect(self.getresult)
self.textEdit = QtWidgets.QTextEdit(Dialog)
self.textEdit.setGeometry(QtCore.QRect(660, 500, 291, 201))
self.textEdit.setObjectName("textEdit")
self.textEdit.setStyleSheet('font-size:30px')
self.pushButton_2 = QtWidgets.QPushButton(Dialog)
self.pushButton_2.setGeometry(QtCore.QRect(720, 900, 150, 50))
self.pushButton_2.setObjectName("pushButton_3")
self.pushButton_2.setStyleSheet('font-size:30px')
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
#接收用户输入,调用数据库
def getresult(self):
condition = self.textEdit.toPlainText()
self.a_widget = QtWidgets.QWidget()
self.a = medicineres.Ui_Dialog()
self.a.setupUi(self.a_widget,condition)
self.a.pushButton.clicked.connect(self.a_widget.close)
self.a_widget.show()
#输出匹配到数据库中的数据
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "Dialog"))
self.label.setText(_translate("Dialog", "药物推荐助手"))
self.label_2.setText(_translate("Dialog","请输入您的症状以#作为间隔"))
self.pushButton_3.setText(_translate("Dialog", "查询"))
self.pushButton_2.setText(_translate("Dialog", "返回"))
将匹配到的数据库结果可视化,相关代码如下:
#将匹配到的数据库结果可视化
#导入库函数
from PyQt5 import QtCore, QtGui, QtWidgets
import pandas as pd
#GUI界面设计,大小和按钮
class Ui_Dialog(object):
def setupUi(self, Dialog,condition):
_translate = QtCore.QCoreApplication.translate
Dialog.setObjectName("Dialog")
Dialog.setWindowTitle(_translate("Dialog", "查询结果"))
Dialog.resize(600, 400)
Dialog.setFixedSize(600, 400)
self.pushButton = QtWidgets.QPushButton(Dialog)
self.pushButton.setGeometry(QtCore.QRect(200, 300, 200, 40))
self.pushButton.setObjectName("pushButton")
self.pushButton.setStyleSheet('font-size:30px')
self.pushButton.setText(_translate("Dialog", "退出"))
self.tableWidget = QtWidgets.QTableWidget(Dialog)
self.tableWidget.setGeometry(QtCore.QRect(0, 0, 600, 300))
self.tableWidget.setObjectName("tableWidget") self.tableWidget.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)
self.tableWidget.setColumnCount(3)
item = QtWidgets.QTableWidgetItem()
#接收输入的用户症状
item.setText(_translate("Dialog", "medicine_1"))
self.tableWidget.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
item.setText(_translate("Dialog", "medicine_2"))
self.tableWidget.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
item.setText(_translate("Dialog", "medicine_3"))
print(item)
self.tableWidget.setHorizontalHeaderItem(2, item)
self.condition = condition.split("#")
#读数据库
df = pd.read_csv("./databank/cure_clean.csv")
self.tableWidget.setRowCount(len(self.condition))
for i in self.condition :
medicine = []
medicine_1 = df.loc[df['condition'] == i, 'medicine_1']
medicine_2 = df.loc[df['condition'] == i, 'medicine_2']
medicine_3 = df.loc[df['condition'] == i, 'medicine_3']
if len(medicine_1) == 0 or len(medicine_2) == 0 or len(medicine_3) == 0 :
info = " %s Not Found" % (i)
QtWidgets.QMessageBox.about(None,"Warning",info) self.tableWidget.setVerticalHeaderItem(self.condition.index(i), QtWidgets.QTableWidgetItem(i))
else : self.tableWidget.setVerticalHeaderItem(self.condition.index(i), QtWidgets.QTableWidgetItem(i))
#输出排名前三的药物
medicine_1 = medicine_1.values[0]
medicine_2 = medicine_2.values[0]
medicine_3 = medicine_3.values[0]
medicine_1= medicine_1.strip().replace('Series([], )', ' ')
medicine_2= medicine_2.strip().replace('Series([], )', ' ')
medicine_3= medicine_3.strip().replace('Series([], )', ' ')
medicine.append(medicine_1)
medicine.append(medicine_2)
medicine.append(medicine_3)
for j in medicine:
self.tableWidget.setItem(self.condition.index(i), medicine.index(j),
QtWidgets.QTableWidgetItem(j))
QtWidgets.QTableWidget.resizeColumnsToContents(self.tableWidget)
QtCore.QMetaObject.connectSlotsByName(Dialog)
测试文件相关代码如下:
#测试文件代码
#导入库函数
import PyQt5
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtCore import QCoreApplication
import sys,xlsxwriter,csv,os
from databank import jiance,mainwindow,medicine,medicineres
#打开疾病预测模块,预测疾病;创建或打开疾病记录,记录用户数据
with open("./databank/test.csv", 'w') as f:
csv_write = csv.writer(f)
data_row = ["age", "sex","trestbps","chol","fbs","restecg","thalach","exang","oldpeak","ca","cp_0","cp_1","cp_2","cp_3","thal_0","thal_1","thal_2","thal_3","slope_0","slope_1","slope_2"]
csv_write.writerow(data_row)
f.close()
with open("./databank/test2.csv", 'w') as f:
csv_write = csv.writer(f)
data_row = ["age", "bp","sg","al","su","rbc","pc","pcc","ba","bgr","bu","sc","sod","pot","hemo","htn","dm","cad","appet","pe","ane"]
csv_write.writerow(data_row)
f.close()
#打开药物推荐模块,推荐药物
app = QtWidgets.QApplication(sys.argv)
a_widget = QtWidgets.QWidget()
b_widget = QtWidgets.QWidget()
c_widget = QtWidgets.QWidget()
#界面GUI设计及输出
a = mainwindow.Ui_Dialog()
a.setupUi(a_widget)
a_widget.show()
b = jiance.Ui_Dialog()
b.setupUi(b_widget)
c = medicine.Ui_Dialog()
c.setupUi(c_widget)
a.pushButton.clicked.connect(b_widget.show)
c.pushButton_2.clicked.connect(c_widget.close)
b.Button2.clicked.connect(b_widget.close)
a.pushButton_2.clicked.connect(c_widget.show)
sys.exit(app.exec_())
系统测试
本部分包括训练准确度、测试效果和模型应用。
1. 训练准确度
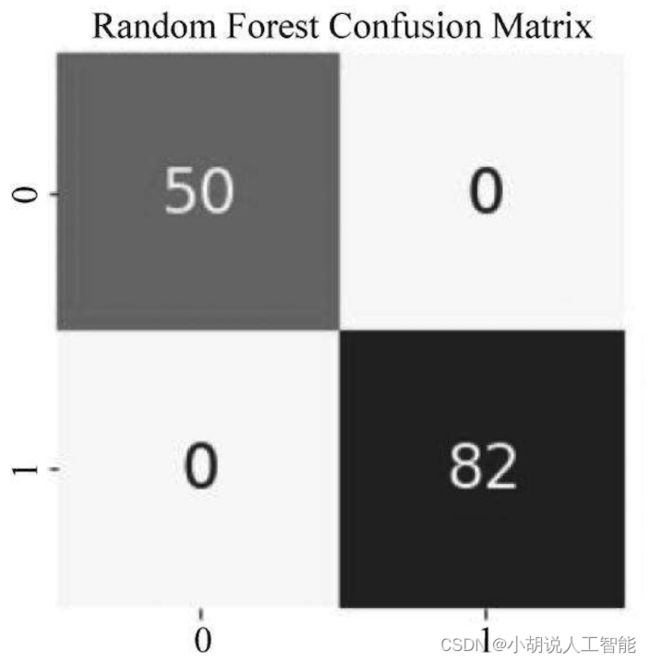
心脏病预测准确率达到89%以上,模型训练比较成功,如图13~图16所示。




慢性肾病预测准确率达到100%,如图17~图20所示。
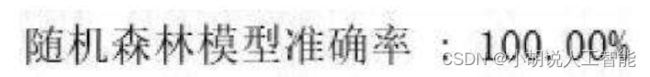

2. 测试效果
将数据代入模型进行测试,分类的标签与原始数据进行显示和对比,可以得到验证:模型可以实现疾病预测和药物推荐。
模型训练效果如图所示。

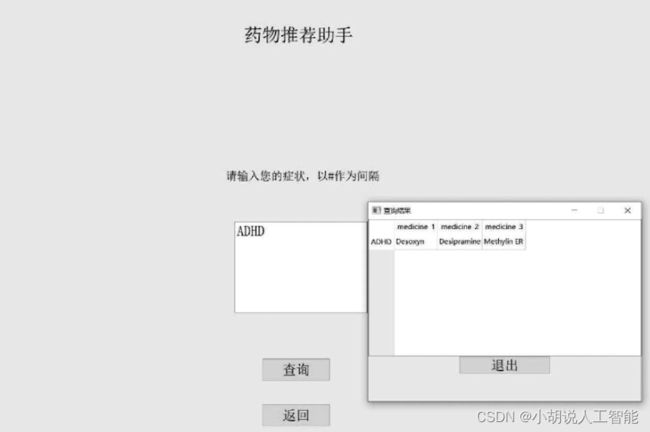
药物推荐效果如图所示。
3. 模型应用
打开cmd命令,到程序所在文件夹;输入python test.py开始测试;打开应用,初始界面如图所示。

界面从上至下,分别有三个按钮。单击第一个按钮“健康预测”,可以看到界面跳转到疾病预测界面,如图所示。

返回主界面后,单击第二个按钮“药物推荐”,看到界面跳转到药物推荐界面,如图所示;

药物推荐助手如图21所示,对不在数据库中的症状,提示不存在,不输出任何疾病信息,如图22所示。


其它相关博客
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(一)
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(二)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。