反汇编算法介绍和应用——线性扫描算法分析
做过逆向的朋友应该会很熟悉IDA和Windbg这类的软件。IDA的强项在于静态反汇编,Windbg的强项在于动态调试。往往将这两款软件结合使用会达到事半功倍的效果。可能经常玩这个的朋友会发现IDA反汇编的代码准确度要高于Windbg,深究其原因,是因为IDA采用的反汇编算法和Windbg是不同的。下面我来说说我所知道的两种反汇编算法。(转载请指明来自breaksoftware的csdn博客)
1 线性扫描(Linear sweep)
线性扫描是一种非常基础的反汇编算法。看到“线性”二字,我们脑海里可能会立马浮现出一个指针对一段内存中数据从开始到最后进行一次遍历的场景。而实际上这种算法的确是如此执行的。像windbg就是使用这种反汇编算法的。反汇编步骤是:
A 位置指针lpStart指向代码段开始处
B 从lpStart位置开始尝试匹配指令,并得到指令长度n
C 如果B成功,则反汇编(Intel风格或者AT&T风格)从lpStart之后n个数据;如果失败,则退出
D 位置指针lpStart赋值为lpStart+n,即上条指令的结尾
E 判断lpStart是否超过了代码段结尾处,如果超出则结束。如果不超出则进入B流程。
在A、E这两个过程中,我们需要提前确定代码开始处和结束处。一般来说,在windows平台上,我们可以根据PE文件的可选头标准域中BaseOfCode结合DataDirectory中相关信息可以算出来代码开始位置,从PE文件可选头标准域中SizeOfCode得到代码段总大小,从而确定结尾位置。
在B这个过程,对于不同指令集存在细微的差别。现在简要说下主要两种指令集:
RISC全称是Reduced Instruction Set Computing,即精简指令集。该指令集有个非常重要的特定——指令长度相同,这样反汇编匹配不会出现回溯现象。
CISC全称是Complex Instruction Set Computer,即复杂指令集。该指令集一个重要的特点是和RISC正好相反的——指令长度可变,这样反汇编匹配会出现回溯现象。
可以发现线性扫描的一大特点就是简单方便,但是它存在一个问题:它无法知道整个程序的执行流。使用过IDA的朋友会发现,在我们使用IDA打开一个PE文件时,IDA会给我们显示一个UML类型的执行流程图。而Windbg就没有这样的功能。为什么?就是因为线性扫描有不知执行流这个缺陷。
既然知道了缺陷,那么在充满极客的安全领域,自然有人会去研究和利用。我们可以利用这个缺陷,让Windbg这类使用线性反汇编算法的工具分析出错误的结果。
我们开始一个思考个过程:看如上ABCDE流程,我们可以发现特别“悬”的一个操作就是确定lpStart。因为只要lpStart确定错误,那么分析出来的结果肯定是不对的。的确,线性扫描算法就是存在这样一个致命的问题。那如何利用呢?
a 在一条可以改变执行流的有效指令后插入无效信息
这儿所说的指令包括jmp,ja等跳转,以及ret等改变EIP的指令。
我们先看个跳转指令例子
int _tmain(int argc, _TCHAR* argv[])
{
int i = argc;
if ( argc > 1 ) {
i++;
}
__asm
{
jz position
jnz position
_emit 0xE8
position:
}
i++;
return 0;
}
我们使用jz position、jnz position使程序的执行流肯定走到position处,从而我们在jnz position这条有效指令后插入的0xE8是个无效数据。这样我们将触发线性扫描出错
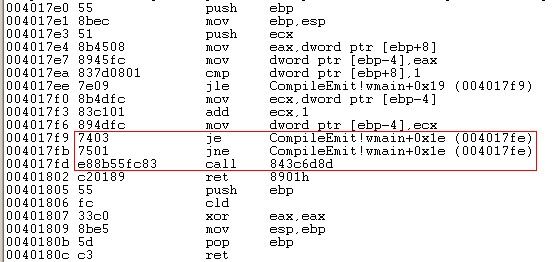
我们可以看到插入的0xE8(call指令)影响了分析结果,因为线性扫描在扫描004017fb~004017fc时发现是有效的jne指令,于是它傻乎乎的认为004017fd开始的就是下一条指令开始处。正确的结果我们看IDA的反汇编结果

我们再看一个ret的例子
int _tmain(int argc, _TCHAR* argv[])
{
__asm
{
push xxx
ret
_emit 0xE8
xxx:
}
printf("1");
return 0;
}
因为push xxx使得栈顶为xxx,而ret将pop出xxx,并将EIP改成xxx,让程序从xxx初开始执行。这样我们又构造了一个无效数据0xE8。我们看看Windbg和IDA的反汇编结果
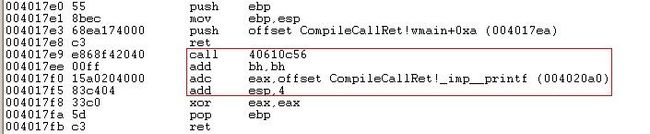
Windbg
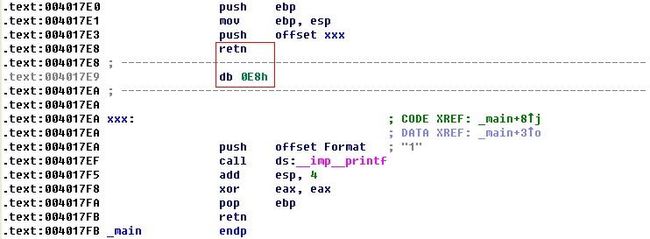
IDA(此处IDA有点智能,它判断了下ret之后的EIP是否为一个固定地址)
b 正常的流程识别错误
编译器在将处理我们代码时是有策略的,比如当我们switch中case比较多的时候(我在我的环境测试时发现好像要超过2个case),switch case逻辑会使用跳转表来表达。举个例子
int switchfun(int nvalue){
switch(nvalue) {
case 0:
case 1: {
nvalue++;
}break;
case 2: {
nvalue += 2;
}break;
case 3: {
nvalue += 3;
}break;
default: {
nvalue = 0;
};
}
return nvalue;
}

可以见到这就是使用了跳转表。我们可以看到0040177C位置是一组数据。如果我们将这个跳转表放在0040174A处,将原来0040174A的逻辑后移,并修正相关偏移,是不是我们就让Windbg分析出错呢?是的,可是为了构造这样的结构,我得对我的代码做改动,且要修改生成的二进制文件。
int switchfun(int nvalue){
{
__asm nop;
.
.
.
__asm nop;
}
switch(nvalue) {
case 0:
case 1: {
nvalue++;
}break;
case 2: {
nvalue += 2;
}break;
case 3: {
nvalue += 3;
}break;
default: {
nvalue = 0;
};
}
return nvalue;
}
我们人为插入多个nop,为我们之后方便修改二进制文件提供空间,同时可以减少计算偏移的量。对二进制文件修改如下
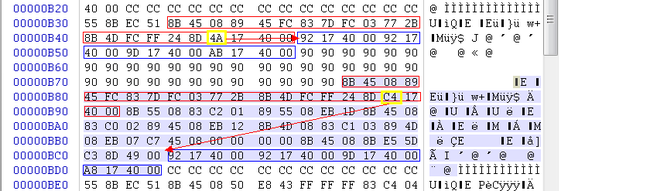
我将从B7C到B92的数据拷贝到以前是一串90(nop)开始处的B34。并紧跟这串数据,将BC4开始的跳转表数据拷贝过来,同时修正跳转表的偏移(C4->4A)。程序可以正确执行,我们看windbg的反汇编结果。
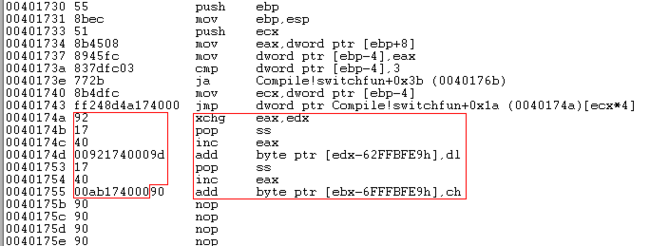
错了吧!
我们再看看IDA的反汇编结果
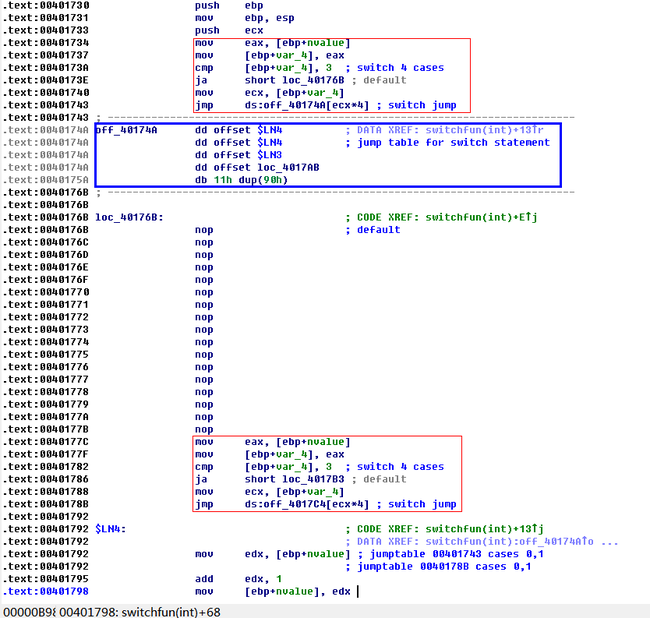
可以见到IDA分析是正确的。
经过如上分析,是不是你觉得IDA比Windbg好呢?其实也不一定。线性扫描的一个大优点就是它可以把所有代码都反汇编掉,而IDA使用的递归下降(recursive descent)算法并不一定会将所有代码都反汇编掉,我会在下一篇博文说明如何利用IDA这个缺陷,来隐藏我们不想被反汇编的逻辑。