【Linux】线程池 | 自旋锁 | 读写锁
文章目录
- 一、线程池
-
- 1. 线程池模型和应用场景
- 2. 单例模式实现线程池(懒汉模式)
- 二、其他常见的锁
-
- 1. STL、智能指针和线程安全
- 2. 其他常见的锁
- 三、读者写者问题
-
- 1. 读者写者模型
- 2. 读写锁
一、线程池
1. 线程池模型和应用场景
线程池是一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
线程池模型
线程池模型本质上也是生产者消费者模型,线程池的实现原理是:在线程池中预先准备好并创建一批线程,然后上层将任务push到任务队列中,休眠的线程如果检测到任务队列中有任务,就直接被操作系统唤醒,然后去消费并处理任务,唤醒一个线程的代价比创建一个线程的代价小的很多。
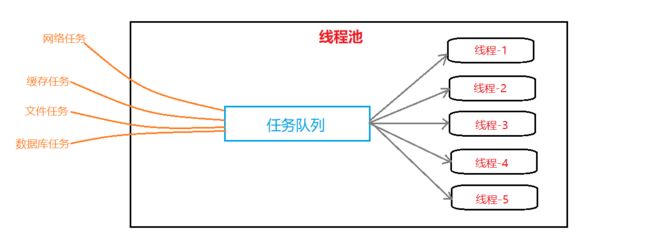
任务线程指的是生产者,任务队列指的是交易场所,右边的一大批线程指的是消费者,因此。线程池的本质还是生产消费模型。
线程池的应用场景
- 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限,出现错误。
2. 单例模式实现线程池(懒汉模式)
ThreadPool.hpp
#pragma once
#include Thread.hpp
#pragma once
#include Task.hpp
#pragma once
#include lockGuard.hpp
#pragma once
#include main.cc
#include "ThreadPool_V4.hpp"
#include "Task.hpp"
#include 
二、其他常见的锁
1. STL、智能指针和线程安全
STL中的容器是否是线程安全的?
不是;原因是, STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响,而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶).
因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全。
智能指针是线程安全的吗?
智能指针是线程安全的吗?unique_ptr 是和资源强关联,只是在当前代码块范围内生效,因此不涉及线程安全问题。对于 shared_ptr,多个对象需要共有一个引用计数变量,所以会存在线程安全问题。但是标准库实现的时候也考虑到了这个问题,就基于原子操作(Compare And Swap(CAS)) 的方式保证 shared_ptr 能够高效原子地操作引用计数。shared_ptr 是线程安全的,但不意味着对其管理的资源进行操作是线程安全的,所以对 shared_ptr 管理的资源进行操作时也可能需要进行加锁保护。
2. 其他常见的锁
悲观锁:悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问贡献资源前,先要进行加锁保护。常见的悲观锁有:互斥锁、自旋锁和读写锁等。乐观锁:乐观锁做事比较乐观,它乐观地认为共享数据不会被其他线程修改,因此不上锁。它的工作方式是:先修改完共享数据,再判断这段时间内有没有发生冲突。如果其他线程没有修改共享数据,那么则操作成功。如果发现其他线程已经修改该共享数据,就放弃本次操作。乐观锁全程并没有加锁,所以它也叫无锁编程。乐观锁主要采取两种方式:版本号机制(Gitee等)和 CAS 操作。乐观锁虽然去除了加锁和解锁的操作,但是一旦发生冲突,重试的成本是很高的,所以只有在冲突概率非常低,且加锁成本非常高的场景下,才考虑使用乐观锁。CAS 操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。自旋锁:使用自旋锁的时候,当多线程发生竞争锁的情况时,加锁失败的线程会忙等待(这里的忙等待可以用 while 循环等待实现),直到它拿到锁。而互斥锁加锁失败后,线程会让出 CPU 资源给其他线程使用,然后该线程会被阻塞挂起。如果临界区代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和临界区代码执行的时间是成正比的关系。如果临界区代码执行的时间很短,就不应该使用互斥锁,而应该选用自旋锁。因为互斥锁加锁失败,是需要发生上下文切换的,如果临界区执行的时间比较短,那可能上下文切换的时间会比临界区代码执行的时间还要长。
三、读者写者问题
1. 读者写者模型
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。那么有没有一种方法,可以专门处理这种多读少写的情况呢?
这就需要我们的读者写者模型出场了,读者写者模型其实也是维护321原则;三种关系:读者与读者、读者与写者、写者与写者。两种对象:读者和写者。一个交易场所:需要写入和从中读取的缓冲区。
下面我们来看一下读者写者模型的三种关系:
读者与读者:没有关系读者与写者:互斥与同步写者与写者:互斥
那么,为什么在生产者消费者模型中,消费者和消费者是互斥关系,而在读者写者问题中,读者和读者之间没有关系呢?
读者写者模型和生产者消费者模型的最大区别就是:消费者会将数据拿走,而读者不会拿走数据,读者仅仅是对数据做读取,并不会进行任何修改的操作,因此共享资源也不会因为有多个读者来读取而导致数据不一致的问题。
2. 读写锁
在读者写者模型中,pthread库为我们提供了 读写锁 来维护其中的同步与互斥关系。读写锁由读锁和写锁两部分构成,如果只读取共享资源用读锁加锁,如果要修改共享资源则用写锁加锁。所以,读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理:
当写锁没有被写线程持有时,多个读线程能够并发地持有读锁,这大大提高了共享资源的访问效率。因为读锁是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。但是,一旦写锁被写进程持有后,读线程获取读锁的操作会被阻塞,而其它写线程的获取写锁的操作也会被阻塞。
伪代码:
// 写者进程/线程执行的函数
void Writer()
{
while(true)
{
P(wCountMutex); // 进入临界区
if(wCount == 0)
P(rMutex); // 当第一个写者进入,如果有读者则阻塞读者
wCount++;// 写者计数 + 1
V(wCountMutex); // 离开临界区
P(wDataMutex); // 写者写操作之间互斥,进入临界区
write(); // 写数据
V(wDataMutex); // 离开临界区
P(wCountMutex); // 进入临界区
wCount--; // 写完数据,准备离开
if(wCount == 0)
{
V(rMutex); // 最后一个写者离开了,则唤醒读者
}
V(wCountMutex); //离开临界区
}
}
// 读者进程/线程执行的次数
void reader()
{
while(TRUE)
{
P(rMutex);
P(rCountMutex); // 进入临界区
if ( rCount == 0 )
P(wDataMutex); // 当第一个读者进入,如果有写者则阻塞写者写操作
rCount++;
V(rCountMutex); // 离开临界区
V(rMutex);
read( ); // 读数据
P(rCountMutex); // 进入临界区
rCount--;
if ( rCount == 0 )
V(wDataMutex); // 当没有读者了,则唤醒阻塞中写者的写操作
V(rCountMutex); // 离开临界区
}
}

初始化:
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t
*restrict attr);
销毁:
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
加锁和解锁:
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
读者写者问题很明显会存在读者优先还是写者优先的问题,如果是读者优先的话,可能就会带来写者饥饿的问题。而写者优先可以保证写线程不会饿死,但如果一直有写线程获取写锁,那么读者也会被饿死。所以使用读写锁时,需要考虑应用场景。读写锁通常用于数据被读取的频率非常高,而被修改的频率非常低。注:Linux 下的读写锁默认是读者优先的。