【网络协议】Http-上
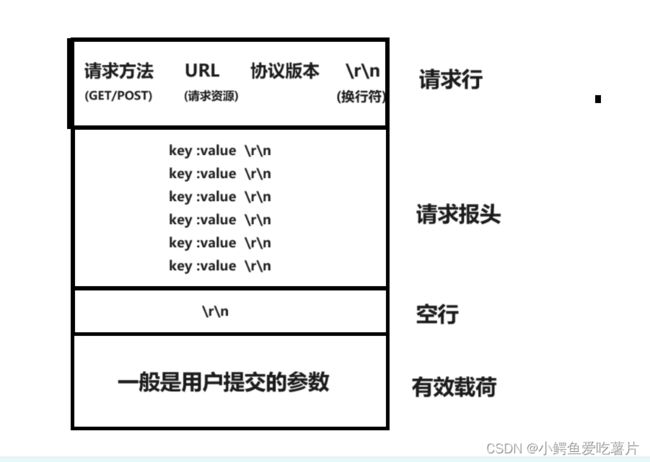
Http请求结构:
结构图1:
实验解析请求报文:
1.在Edge浏览器上输入ip地址+端口号+文件资源,也就是下图中的120.XX.139.29:8888/A/B/c.html

2.我的程序接收到了一个没有有效载荷的http请求(呼应上面的结构图1),如下
GET /1/2/3.html HTTP/1.1 //请求行(请求方法+请求资源+协议版本)
Host: 120.46.139.29:8888 //请求的目的主机+端口号
Connection: keep-alive //链接模式
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.0.0 //操作系统信息+浏览器信息,这也就是当你用浏览器下载app的时候他自动能识别你需要ios还是安卓。
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate //客户端可以接收的编码类型
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 //编码符号
3.关闭我的HttpServer程序
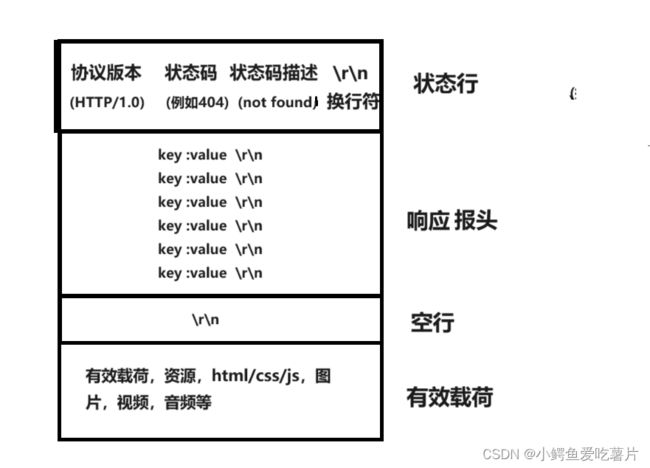
Http响应结构:
结构图2:
代码块1:
const std::string SEP="\r\n";
std::string HandlerHttp(const std::string& request)
{
//前提:request一定是一个完整的请求报文。
//给别人返回的是一个http response;
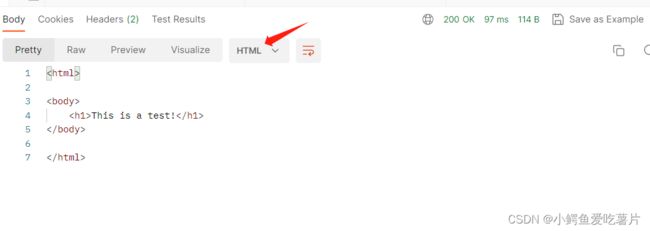
std::cout<<"------------------------------------"<我自己的服务器在收到http请求时,给客户端返回响应,正文是
This is a test!
,被浏览器解释后就会出现下图这样的样子;因为正文部分使用了html,一种描述网页的语言;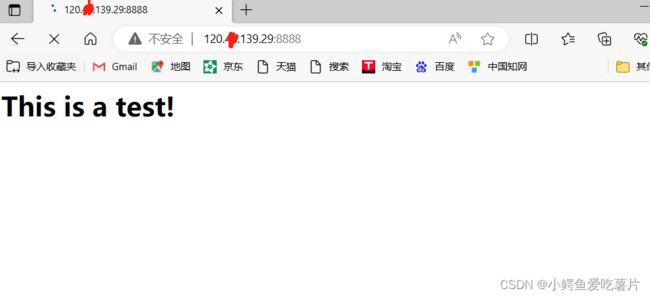
深入理解:
空行能让报头和正文被区分,从而识别出收到的请求或相应的正文开头。
但是当多个http请求同时发送给服务器的时候,如果不知道正文有多长就无法有效识别正文,那怎么才能知道正文读没读取完呢?答案是在响应报头中有Content-Length代表Body的长度;
这里想一个问题在上面的代码中,我的服务器在给浏览器返回响应时,响应报头中并没有带正文长度,那浏览器是如何准确读取完正文的呢?答案是浏览器很牛逼不用我们操心。不过我们可以在上面代码块1的基础上加上Content-Length,再进行测试。
代码块2:
std::string HandlerHttp(const std::string& request)
{
//前提:request一定是一个完整的请求报文。
//给别人返回的是一个http response;
std::cout<<"------------------------------------"<测试:
1.发送http请求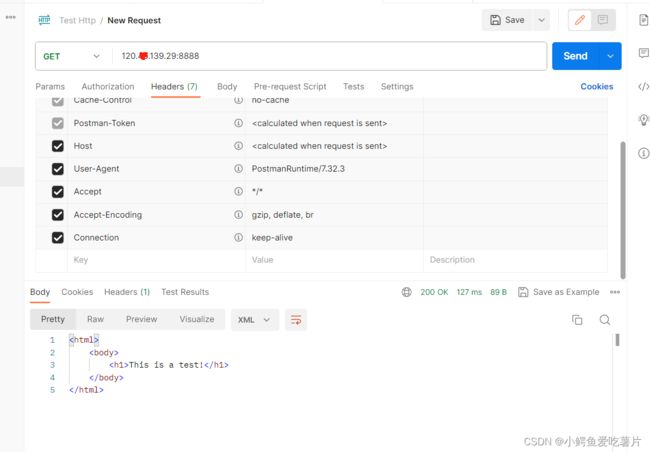
2.查看响应
XML格式:
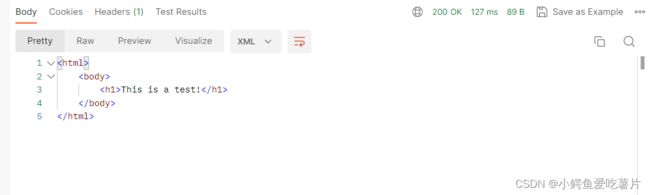
网页预览版:
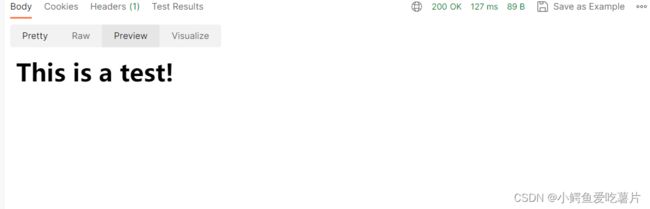
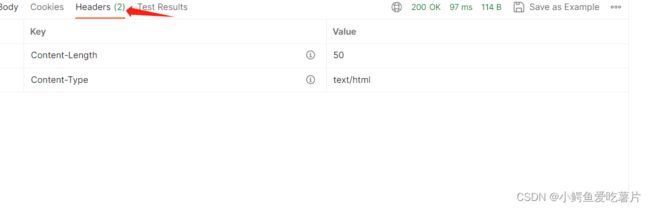
可以看到报头中有了Content-Length;
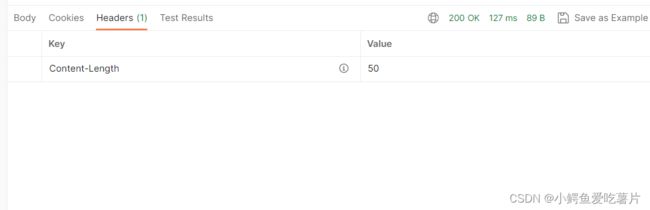
在服务器里面的所有资源都以文件的形式存在,当服务器找到了用户所申请的资源就会返回响应。响应报头中还会携带Content-Type以表示文件是什么类型的,好让用户的浏览器接收到响应后正确解析资源。
代码块3:
在代码块2的基础上再加上Content-Type。
std::string HandlerHttp(const std::string& request)
{
//前提:request一定是一个完整的请求报文。
//给别人返回的是一个http response;
std::cout<<"------------------------------------"<本质上都是文件,都要有自己的后缀。
std::string response;
response+="HTTP/1.1 200 OK"+SEP;//状态行
response+="Content-Length: "+std::to_string(body.size())+SEP;//报头-content_length;
response+="Content-Type: text/html"+SEP;
response+=SEP;//空行
response+=body;//正文
return response;
}
可以看到响应body自动被识别成html了。
报头属性数量也变成两个了。
但是像上面代码那样,把资源写在程序里面显然是不现实的,难不成每次更新资源都需要重新编译程序,然后重新启动服务器?所以服务器Http服务器必须从文件里面读取资源。
为了避免文章太长影响观感,所以分多部分叙述,请看下文。
HTTP-中
参考:
1.URL:统一资源定位符(Uniform Resource Locator)统一资源定位系统是专为标识Internet网上资源位置而设置的一种编址方式,平时所说的网页地址指的即是URL。 统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
2.所有字符都需要编码,利用二进制代表字符。例如ASCLL码或者UTF8,因为计算机只认识二进制。
3.URL编码Encode,解码Decode。