springboot线程池简单用法及配置解析
定义线程池
package com.example.demo.start.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @Description: 定义线程池
* @Author: mayanhui
* @Date: 2023-09-19 13:28
*/
@Configuration
@EnableAsync
public class ThreadPoolConfig {
@Bean(name = "taskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数
executor.setCorePoolSize(5);
// 最大线程数
executor.setMaxPoolSize(10);
// 队列容量
executor.setQueueCapacity(5);
// 线程名前缀
executor.setThreadNamePrefix("MyTask-");
/**
* AbortPolicy:中断抛出异常
* DiscardPolicy:默默丢弃任务,不进行任何通知
* DiscardOldestPolicy:丢弃掉在队列中存在时间最久的任务,然后重试任务
* CallerRunsPolicy:重试添加当前的任务,自动重复调用
*/
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
return executor;
}
}
很多人并不理解这些配置,比如核心线程数、最大线程数,队列容量等等,怎么设置其大小,下面通过几个简单的例子来理解这几个参数
@Async("taskExecutor")
@Scheduled(cron = "0/2 * * * * *")
public void myTask() {
// 获取当前线程
Thread currentThread = Thread.currentThread();
// 获取当前线程的名称
String threadName = currentThread.getName();
log.info("当前的线程名称:{}",threadName);
}
这是一个定时任务,模拟我们正常的业务,每2秒中处理一次,此时通过日志
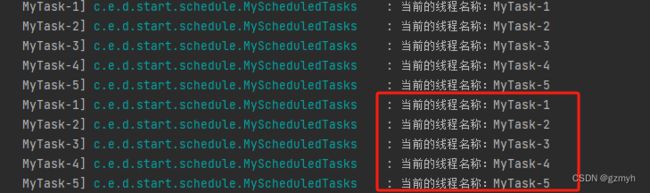
因为我们的业务程序处理时间绝对在2秒内,因此我们可以看到5个核心线程在轮流运行着,说明这个配置是比较合理的。
现在我们假设另外一种情况,假如说我们的业务比较复杂,处理完业务要14秒钟,那我们看看线程池是如何运作的
我们先改一下代码
//监控
@Scheduled(cron = "0/2 * * * * *")
public void t() {
Object o = RedisUtil.get("useTime");
Long u = 0L;
if (Objects.isNull(o)){
RedisUtil.set("useTime","0");
}else{
Long useTime = Long.parseLong(o.toString());
u = useTime + 2L;
RedisUtil.set("useTime",u.toString());
}
//队列里面的线程
int queueSize = taskExecutor.getQueueSize();
int activeCount = taskExecutor.getActiveCount();
log.info("当前队列数量queueSize:{},活跃的线程数activeCount:{},[{}秒]",queueSize,activeCount,u);
}
@Async("taskExecutor")
@Scheduled(cron = "0/2 * * * * *")
public void myTask() {
// 获取当前线程
Thread currentThread = Thread.currentThread();
// 获取当前线程的名称
String threadName = currentThread.getName();
log.info("开始-当前的线程名称:{}",threadName);
try {
//模拟处理,14s
Thread.sleep(14000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("结束-当前的线程名称:{}",threadName);
}
再看看日志
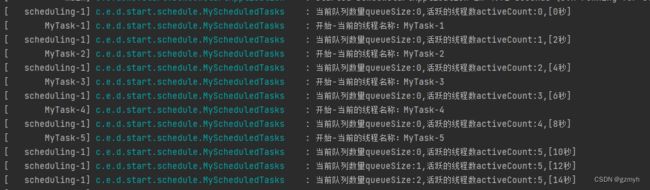
这里的监控程序和我们的测试程序都是2秒运行一次,比如说我们可以看到12秒的时候,有一个请求就进入队列等待了,而活跃的线程数依然是5个
这个应该可以理解吧?2秒钟会有一个线程,而一个线程处理完业务要14秒,也就是说14秒内就会有7个线程产生,那12秒自然产生6个线程,而我们核心线程是5个,因此有一个进入了队列等待
如果按照这个一直跑下去,那队列肯定会满,因为我们队列容量才设置了5个,等待40秒后,看日志

你就会发现队列数量已经达到上限5,此时活跃线程数是6个,而我们的线程名称出现了MyTask-6,为什么??
这是因为我们的最大线程数也加入进来了
思考一下:那接下来队列还会不会阻塞????
接下来我们继续把时间设置成1400000秒,这种情况就是模拟我们的程序性能出问题了,处理一个业务要1400000秒,此时看看线程池是什么情况?

其实猜都猜到,队列数,活跃线程数肯定是满的,另外会抛出异常,直到有线程被处理完后,才会接收新的线程
现在我们总结一下:
首先我们在内存中开启了5个核心线程,如果5个线程处理不过来,那么接下来的线程就会进入队列等,等到队列满了,就会开启最大线程,直到线程数达到了指定线程、队列数达到上限,才会抛出异常。
因此我们在配置这些参数的时候,我们需要估计一下每个线程的处理时间,以及一段时间内产生的线程数,这样大概估计一下核心线程数,至于队列容量,主要是一个缓冲的作用和处理高峰期的线程请求。因此我们使用线程池处理业务的时候最好监控一下线程池的队列容量及活跃线程数,如果数量过高,我们就可以及时处理异常。
线程池的使用例子
@Resource
ThreadPoolTaskExecutor taskExecutor;
@GetMapping("/info")
public void tt(){
int queueSize = taskExecutor.getQueueSize();
int activeCount = taskExecutor.getActiveCount();
/**这里是处理的主要业务***/
log.info("处理正常逻辑");
taskExecutor.execute(() -> {
//这里边是处理一些其它业务
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("queueSize:{},activeCount:{}",queueSize,activeCount);
});
}