三,mybatis的增删查改
一,增加操作
在java里面的UserMapper里面添加方法,用处是实现insert
void insertInToUser(User user);
 在resources里面的User Mapper里面添加方法,用处是实现前面设置的insert方法。
在resources里面的User Mapper里面添加方法,用处是实现前面设置的insert方法。
<insert id="insertInToUser" >
insert into t_user values (#{username},#{password},#{age},#{gender},
#{email},null)
insert>
 在启动类创建对应的方法运行
在启动类创建对应的方法运行
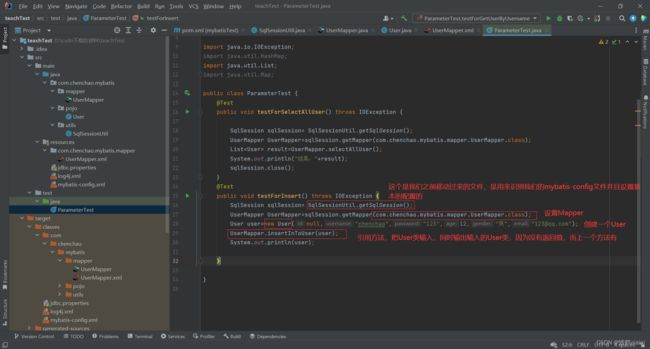
@Test
public void testForInsert() throws IOException {
SqlSession sqlSession= SqlSessionUtil.getSqlSession();
UserMapper UserMapper=sqlSession.getMapper(com.chenchao.mybatis.mapper.UserMapper.class);
User user=new User(null,"chenchao","123",12,"男","[email protected]");
UserMapper.insertInToUser(user);
System.out.println(user);
}
现在来解读一下这个方法。
二,删除操作、
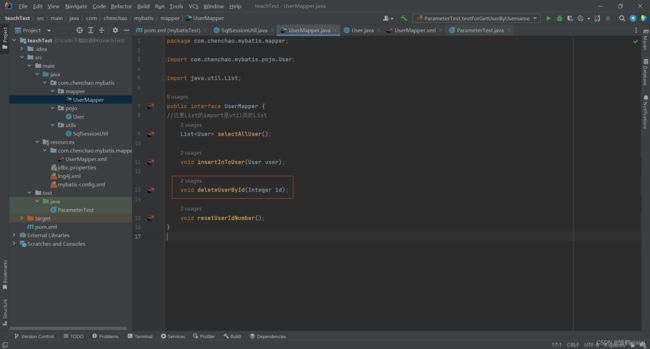
先在java包里面的User Mapper创建删除方法
void deleteUserById(Integer id);
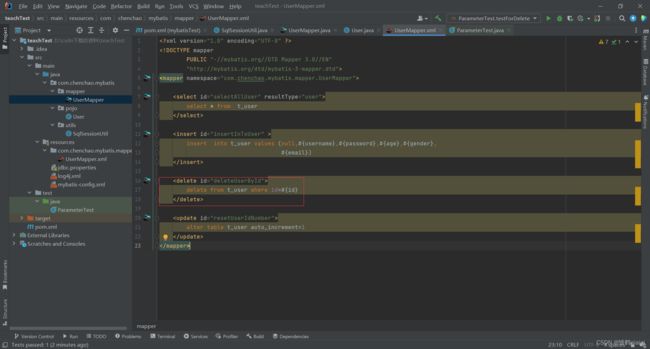
然后到resources里面的User Mapper里面写sql语句
<delete id="deleteUserById">
delete from t_user where id=#{id}
delete>
可以看到我们这边删除了记录,但是我们也把ID的自动递增打乱了。就好比我们这里有10条记录,我把第三条删除了,下次再新增一个的序号就是11。但是我们这里只有9条记录。但是表内的id只是作为识别表内的行的数据时使用的,比如检测到某学生通过学号登入系统,我们只需要获取该生学号再到学生表里面找到该生id就可以针对该id进行增删查改操作。所以一般来说如果需要其他意义的值,比如说考试排名,当有学生因为作弊被取消排名,那么该排序就必须进行重排,而且如果有补考的学生是不是还要新增学生。这个时候如果不重新排序那么可能会出现最后一名的学生的排名大于人数。如果这门课是按照排位挂科的,那么如果作弊的学生是在60分以上的,是不是意味着会有一部分学生因为没有排名排序而低于合格排位。所以这个时候使用排序是合理的。
但是为了简单演示再加上其实原理都是相通的就用id来演示删除后重新排序。
所以要设置重新排序功能
在java包里面的UserMapper添加
void resetUserIdNumber();
然后到resources里面的UserMapper填写对应的sql语句。
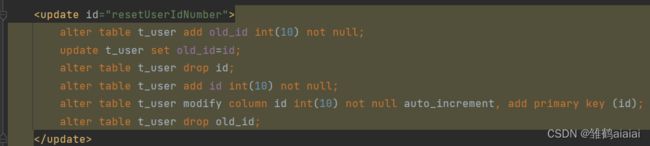
alter table t_user add old_id int(10) not null;
update t_user set old_id=id;
alter table t_user drop id;
alter table t_user add id int(10) not null;
alter table t_user modify column id int(10) not null auto_increment, add primary key (id);
alter table t_user drop old_id;
解释一下这些语句的作用。第一句是增加一个字段叫做old_id之后是将id的值转移到old_id然后删除id字段,之后再创建一次id字段(id字段为主键,自增,int(10))。
在启动类创建对应的方法运行
@Test
public void testForDelete() throws IOException {
SqlSession sqlSession= SqlSessionUtil.getSqlSession();
UserMapper UserMapper=sqlSession.getMapper(com.chenchao.mybatis.mapper.UserMapper.class);
//User user=new User(null,"chenchao","123",12,"男","[email protected]");
UserMapper.deleteUserById(9);
UserMapper.resetUserIdNumber();
//System.out.println(user);
}
可以看到这里deleteUserById用的是9号也就是删除id为9的行
我们多放点数据来模拟一下
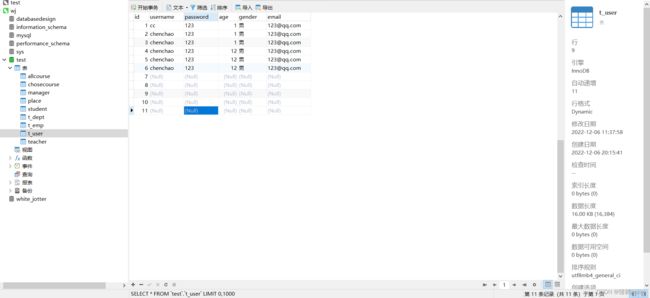

可以看到第9行已经没有了。然后序号也是对的。
Tips:采用了这个方法之后,所有的表的ID会在最后一列,所以所有的insert语句的部分对应id必须也是在最后面。比如
insert into t_user values (#{username},#{password},#{age},#{gender},#{email},null)
三,查找操作
先在java包的UserMapper里面创建
List<User> selectUserById(Integer id);
方法,之后到resources包的User Mapper里面创建的对应的sql语句。
<select id="selectUserById" resultType="user">
select * from t_user where id=#{id}
select>
之后在启动类里面添加方法
@Test
public void testForSelectUserById() throws IOException {
SqlSession sqlSession= SqlSessionUtil.getSqlSession();
UserMapper UserMapper=sqlSession.getMapper(com.chenchao.mybatis.mapper.UserMapper.class);
List<User> result=UserMapper.selectUserById(1);
System.out.println("结果:"+result);
sqlSession.close();
}
四,修改操作
在java包里面的User Mapper创建方法
void updateUserById(@Param("id") Integer id, @Param("username") String username);
注意这里新增一个用法,@Param()。这个是用来给参数命名的,如果不命名当多个参数的时候会导致识别不了第一个参数之后的参数。有多种办法具体可参考https://blog.csdn.net/heyl163_/article/details/126326754 这篇博客。
解释一下这个注解的使用方法
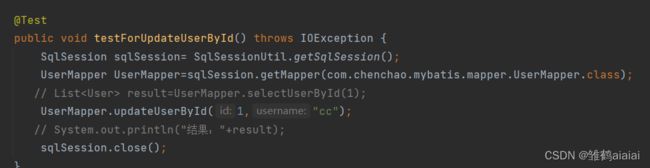

可以看到这里的 UserMapper.updateUserById(1,“cc”);里面写的id和username表示传递参数是按照顺序传递的。