PyTorch学习笔记(四) -------卷积层
什么是卷积?
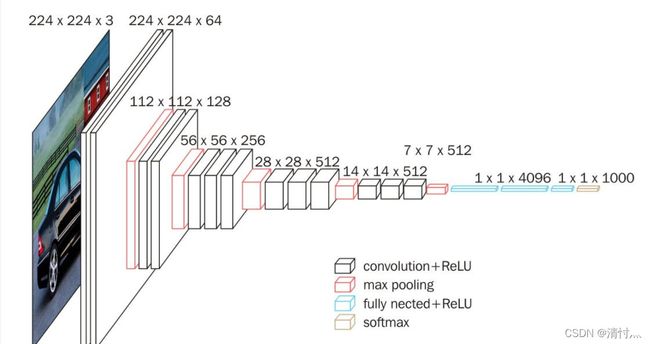
来看这张图
输入图像是224*224*3 即图片尺寸是224*224,3个通道;输出图片尺寸是224*224,64个通道
个人认为,卷积就是图片经过卷积核的映射过程,如下图所示

什么是通道?
在卷积操作中一般要求设置的in_channel和out_channel
在一遍jpg,png图片中,in_channel=3,为RGB三个通道,RGB的不同可以调整图片的色彩
out_channel则表示卷积核的数量,卷积核的数量=输出通道
以上就是这次学习中对这两个基本概念的个人理解,想要更细致的理解建议可以看看吴恩达老师的机器学习,在学习过程中可以先尝试着敲一些代码,来print一下看它的模型是什么样的,然后配合理论概念进行理解
下面来看代码模型
这里测试一个图像数据集,给定它的卷积核
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kelnel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])当然,要进行reshape操作变换参数
input = torch.reshape(input, (1, 1, 5, 5)) # 变换,二维通道数为1, batch_size=1(每次送入的图片数量), 后面是5*5, reshape完变成4维
kelnel = torch.reshape(kelnel, (1, 1, 3, 3)) # 同上
print(input.shape)
print(kelnel.shape)下面来看cnn中Modul的参数调试
output = F.conv2d(input, kelnel, stride=1) # conv2d表示二维卷积操作,F表示非线性化,图像(二维矩阵), 卷积核, stride=1指步数为1
print(output) # 卷积后的输出
output2 = F.conv2d(input, kelnel, stride=2)
print(output2)
# padding=1,上下左右扩展一位,空的地方默认为0
output3 = F.conv2d(input, kelnel, stride=1, padding=1)
print(output3)
这里主要是测试三种,对stride,padding进行了解,stride表示卷积时候的步长,padding表示是否上下左右扩展
下面是完整实践的代码
# -*- coding = utf-8 -*-
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import Dataset
import cv2
from PIL import Image # 图像处理的库
import os
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torch.utils.data import DataLoader
class MyData(Dataset):
def __init__(self, root_dir, label_dir, transform=None): # 初始化类,为class提供全局变量
self.transform = transform
self.root_dir = root_dir # 根文件位置
self.label_dir = label_dir # 子文件名
self.path = os.path.join(self.root_dir, self.label_dir) # 合并,即具体位置
self.img_path = os.listdir(self.path) # 转换成列表的形式
def __getitem__(self, idx): # 获取列表中每一个图片
img_name = self.img_path[idx] # idx表示下标,即对应位置
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 每一个图片的位置
img = Image.open(img_item_path) # 调用方法,拿到该图像
img = img.convert("RGB")
img = self.transform(img)
label = self.label_dir # 标签
return img, label # 返回img 图片 label 标签
def __len__(self): # 返回长度
return len(self.img_path)
tensor_trans = transforms.Compose([transforms.ToTensor(), transforms.Resize([512, 512])])
root_dir = 'D://情绪图片' # 根目录
happy_label_dir = '开心' # 子目录
happy_dataset = MyData(root_dir, happy_label_dir, transform=tensor_trans) # 开心数据集创建完成
test_loader = DataLoader(dataset=happy_dataset, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# batch_size每次取dataset的四个数据集并打包, shuffle是是否打乱,drop_last为False即最后一步不满4个时不舍,反之舍
class SJ(nn.Module):
def __init__(self):
super(SJ, self).__init__() # 继承父类
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
# 初始化,现在网络中有一个卷积层,in_channels=3表示输入通道为3,一般jpg图片为RGB三个通道,RGB的不同可以调整图片的色彩
# out_channels=6表示输出通道为6,卷积核的数量=输出通道,kernel_size表示卷积核的大小为3*3,stride表示步长,padding表示是否上下左右扩展
def forward(self, x):
x = self.conv1(x) # 将X放入卷积层卷积
return x
sj = SJ()
step = 0
writer = SummaryWriter('sj')
for data in test_loader:
imgs, label = data
output = sj(imgs)
step = step + 1
writer.add_images('input', imgs, step)
output = torch.reshape(output, (-1, 3, 510, 510)) # 修改输出通道为3, 前面-1表示batch_size不变,后面是图像尺寸
writer.add_images('output', output, step)
writer.close()
前面数据集的创建在前几篇博客中有介绍过,这里不多讲述
后面class CJ(nn_Module)主要是定义了一个神经网络,各行代码的意思在注释中已经标出
下面来看卷积前后的对比
卷积前

卷积后

这里的数据集从摄图网中下载,约有一百张,仅用于代码学习,不做他用。
欢迎评论私信交流,共同进步~