TFS ——分布式文件存储系统
TFS(Taobao File System)是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。
TFS架构
与Tair类似,TFS也是由NameServer和DataServer组成:
为了容灾,NameServer采用了HA结构,即两台机器互为热备,同时运行,一台为主,一台为备,主机绑定到对外vip,提供服务;当主机器宕机后,迅速将vip绑定至备份NameServer,将其切换为主机,对外提供服务;图中的HeartAgent就完成了此功能。

TFS的设计初衷是为了解决淘宝海量图片存储的问题,所以主要是针对小文件存储的特征作了很多优化。TFS会将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block),每个Block拥有在集群内唯一的编号(Block Id),Block Id在NameServer在创建Block的时候分配,NameServer维护block与DataServer的关系。Block中的实际数据都存储在DataServer上。而一台DataServer服务器一般会有多个独立DataServer进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目录,以降低单个磁盘损坏带来的影响。
TFS架构中,NameServer主要功能是:管理维护Block和DataServer相关信息,包括DataServer加入、退出、心跳信息,block和DataServer的对应关系建立,解除。
正常情况下,一个块会在DataServer上存在, 主NameServer负责Block的创建,删除,复制,均衡,整理,NameServer不负责实际数据的读写,实际数据的读写由DataServer完成。
TFS的Block 大小可以通过配置项来决定,通常为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文件。DataServer进程会给Block中的每个文件分配一个File ID(该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部load在内存,除非出现DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。
存储机制
前面说到,TFS以Block的方式组织文件的存储。每一个Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。在NameServer节点中存储了所有的Block的信息,一个Block存储于多个DataServer中以保证数据的冗余。对于数据读写请求,均先由NameServer选择合适的DataServer节点返回给客户端,再在对应的DataServer节点上进行数据操作。NameServer需要维护Block信息列表,以及Block与DataServer之间的映射关系,其存储的元数据结构如下:

在DataServer节点上,在挂载目录上会有很多物理块,物理块以文件的形式存在磁盘上,并在DataServer部署前预先分配,以保证后续的访问速度和减少碎片产生。为了满足这个特性,DataServer一般在EXT4文件系统上运行。物理块分为主块和扩展块,一般主块的大小会远大于扩展块,使用扩展块是为了满足文件更新操作时文件大小的变化。每个Block在文件系统上以“主块+扩展块”的方式存储。每一个Block可能对应于多个物理块,其中包括一个主块,多个扩展块。
在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。DataServer会在启动的时候把自身所拥有的Block和对应的Index加载进来。
TFS的文件名由块号和文件号通过某种对应关系组成,最大长度为18字节。文件名固定以T开始,第二字节为该集群的编号(可以在配置项中指定,取值范围 1~9)。余下的字节由Block ID和File ID通过一定的编码方式得到。文件名由客户端程序进行编码和解码,它映射方式如下图:

TFS客户端在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在NameServer取得该块所在DataServer信息(如果客户端有该Block与DataServere的缓存,则直接从缓存中取),然后与DataServer进行读取操作。
并发机制
- 对于同一个文件来说,多个用户可以并发读;
- 现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
容错机制
- 集群容错,TFS可以配置主辅集群,一般主辅集群会存放在两个不同的机房。主集群提供所有功能,辅集群只提供读。主集群会把所有操作同步到辅集群。这样既提供了负载均衡,又可以在主集群机房出现异常的情况不会中断服务或者丢失数据。
- NameServer容错,NameServer采用了HA结构,一主一备,主NameServer上的操作会同步到备NameServer。如果主NameServer出现问题,可以实时切换到备NameServer。另外NameServer和DataServer之间也会有定时的heartbeat,DataServer会把自己拥有的Block发送给NameServer。NameServer会根据这些信息重建DataServer和Block的关系。
- DataServer容错,TFS采用Block存储多份的方式来实现DataServer的容错。每一个Block会在TFS中存在多份,一般为3份,并且分布在不同网段的不同DataServer上。对于每一个写入请求,必须在所有的Block写入成功才算成功。当出现磁盘损坏DataServer宕机的时候,TFS启动复制流程,把备份数未达到最小备份数的Block尽快复制到其他DataServer上去。 TFS对每一个文件会记录校验crc,当客户端发现crc和文件内容不匹配时,会自动切换到一个好的block上读取。此后客户端将会实现自动修复单个文件损坏的情况。
平滑扩容
原有TFS集群运行一定时间后,集群容量不足,此时需要对TFS集群扩容。由于DataServer与NameServer之间使用心跳机制通信,如果系统扩容,只需要将相应数量的新DataServer服务器部署好应用程序后启动即可。这些DataServer服务器会向NameServer进行心跳汇报。NameServer会根据DataServer容量的比率和DataServer的负载决定新数据写往哪台DataServer的服务器。根据写入策略,容量较小,负载较轻的服务器新数据写入的概率会比较高。同时,在集群负载比较轻的时候,NameServer会对DataServer上的Block进行均衡,使所有DataServer的容量尽早达到均衡。
进行均衡计划时,首先计算每台机器应拥有的blocks平均数量,然后将机器划分为两堆,一堆是超过平均数量的,作为移动源;一类是低于平均数量的,作为移动目的。
移动目的的选择:首先一个block的移动的源和目的,应该保持在同一网段内,也就是要与另外的block不同网段;另外,在作为目的的一定机器内,优先选择同机器的源到目的之间移动,也就是同台DataServer服务器中的不同DataServer进程。
当有服务器故障或者下线退出时(单个集群内的不同网段机器不能同时退出),不影响TFS的服务。此时NameServer会检测到备份数减少的Block,对这些Block重新进行数据复制。
在创建复制计划时,一次要复制多个block, 每个block的复制源和目的都要尽可能的不同,并且保证每个block在不同的子网段内。因此采用轮换选择(roundrobin)算法,并结合加权平均。
由于DataServer之间的通信是主要发生在数据写入转发的时候和数据复制的时候,集群扩容基本没有影响。假设一个Block为64M,数量级为1PB。那么NameServer上会有 1 * 1024 * 1024 * 1024 / 64 = 16.7M个block。假设每个Block的元数据大小为0.1K,则占用内存不到2G。
TFS读写流程
写流程
TFS会为每一个文件保存多个副本(在不同的dataserver上),为了保证数据一致性,当写入一个文件时,只有所有参与的dataserver均写入成功时,该操作才算成功。
TFS的写操作数据流图如下所示:
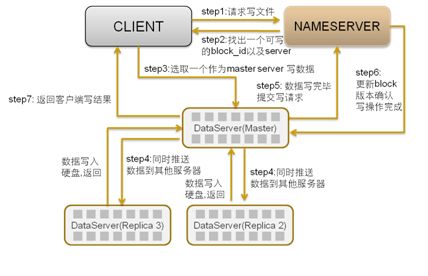
客户端首先向nameserver发起写请求,nameserver需要根据dataserver上的可写块,容量和负载加权平均来选择一个可写的block。并且在该block所在的多个dataserver中选择一个作为写入的master,这个选择过程也需要根据dataserver的负载以及当前作为master的次数来计算,使得每个dataserver作为master的机会均等。master一段选定,除非master宕机,不会更换,一旦master宕机,需要在剩余的dataserver中选择新的master。返回一个dataserver列表。
客户端向master dataserver开始数据写入操作。master server将数据传输为其他的dataserver节点,只有当所有dataserver节点写入均成功时,master server才会向nameserver和客户端返回操作成功的信息。
读流程
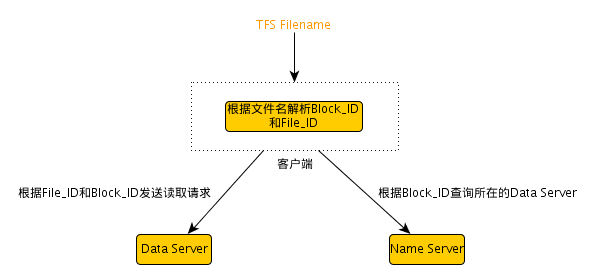
获得Block ID和File ID
根据TFS文件名解析出Block ID和block中的File ID.
获取dataserver地址
向nameserver发送查询请求得到Block ID所在的dataserver地址。
由于nameserver中维护了block和dataserver的对应关系,所以nameserver能够提供相应的信息。
Note: 由于TFS是把大量小文件放在一个block里面,
所以TFS的文件复制是基于block的,而且复制出来的block的block id应该是一致的
请求文件
通过发送Block_ID、File_ID和offset为参数的读请求到对应的dataserver,得到文件内容。
dataserver会根据本地记录的信息来得到File ID所在block的偏移量,从而读取到正确的文件内容.
Nameserver
1、Ns(Nameserver)中的BlockManager用来管理所有来自Ds(Dataserver)的Block信息。因为Block的数量比较多,因此,BlockManager将Block组织成HashMap的数据结构,Hash的桶的个数由MAX_BLOCK_CHUNK_NUMS决定。另外,为了组织方便,定义了一个双向队列std::deque
2、Ns中的ServerManager用来管理所有的Server信息。为了管理好活动的和不可服务的DS,ServerManager定义了两个Server列表servers_和dead_servers_。针对具体的DS的操作大致包括加入Server到活动列表(分为是新加入的还是暂时不可服务又好了的),从活动列表中移除Server到不可服务列表(这种情况可能发生在Ds某种原因退出)。当Server在不可服务列表中超过一定时间后,就会将它从不可服务列表中移除(这种情况可能是磁盘坏掉了,所以等换好新盘启动需要一定的时间)。另外,通过ServerManager可以得到活动Server列表以及不可服务Server列表以及某一个范围内的Server列表。 与BlockManager类似,ServerManager也提供了建立和解除具体Ds与Block的关系接口,但这些过程是以各个Server为中心来完成的。此外,ServerManager还负责挑选可写主块,先由ServerManager挑一个Server,再由Server挑一个Block。当BlockManager中发现某些Block需要复制时,由于每个Block对应多个Server,ServerManager负责挑选出要复制的源Server和目标Server。当ServerManager发现某个Server不满足均衡(目前是将活动列表中的前32个server根据容量百分比,特别小的作为目标Server,特别大的作为源Server)时,针对该Server(作为Source Server)里面的具体Block,ServerManager负责挑选出可做为目标的Server。当某种原因导致Block的副本数大于最大副本数时,ServerManager会根据包含该Block的Server的容量进行排序并在满足一定条件下选择一个Server将多余的Block进行删除。(在选择复制、迁移目标Server时需要考虑Server是否不在任务队列里,是否有空间,以及是否和已经挑选的Server在不同机架)
Dataserver 后台线程
心跳线程
即指Ds向Ns发的周期性统计信息。原先的做法是当Ds需要汇报block时会将blockInfo的信息通过心跳包的形式发给Ns。而现在的心跳只负责keepalive,汇报block的工作由专门的包进行发送。(所以之前的做法是Ns会在心跳的回复包中带上一个状态(status),Ds在收到这个状态包后,会根据状态进行一些相应的操作(比如淘汰过期的Block以及新增Block操作等))。
复制线程
人工或者Ns可以添加复制Block任务至复制队列中,复制线程会从复制队列中取出并执行。结合Ns,整个复制的大致过程是ns向复制的源Ds发起复制任务,源Ds将复制任务所需要的信息结构(ReplBlockExt)加入复制队列中。复制线程取出一个复制任务后,会先通过ReadRawData接口将源Ds的Block数据读出,然后向目标Ds发WriteRawData消息,目标ds在接到writeRawData消息后复制数据,然后通过batch_write_info进行index的复制。然后源Ds将复制是否成功的状态向Ns进行回复,Ns在收到复制成功的消息后会进行Block与Ds关系的更新。当从ns中收到move的操作后,还会将源ds上的Block删除掉。在管理复制的过程中,还用到两个重要的数据结构ReplicateBlockMap_和ClonedBlockMap_,前者用来记录源中将要进行复制的Block,后者用来记录目标中正在复制Block的状态。
压缩线程
真正的压缩线程也从压缩队列中取出并进行执行(按文件进行,小文件合成一起发送)。压缩的过程其实和复制有点像,只是说不需要将删除的文件数据以及index数据复制到新创建的压缩块中。要判断某个文件是否被删除,还需要拿index文件的offset去fileinfo里面取删除标记,如果标记不是删除的,那么就可以进行write_raw_data的操作,否则则滤过。
检查线程
a 清理过期的Datafile;
b 修复check_file_queue_中的逻辑块(block_checker.cpp);
c 清理过期的复制块(由于复制过程中出错导致的错误复制块,复制目标的ds做);
d 清理过期的压缩块(由于压缩过程中出错导致的错误压缩块,压缩在同一个ds上做);
e 每天rotate读写日志,清理过期的错误逻辑块;
f 读日志累积后刷磁盘;
b的详细过程: 每次对文件进行读写删操作失败的时候,会try_add_repair_task(blockid, ret)来将ret错误的block加入check_file_queue_中,正常情况下加入的为-EIO(I/O错误)的错误Block,那什么时候加入的是CRC的错误呢?人工进行修复的时候发该类型的CRC_ERROR_MESSAGE消息,然后也会加入check_file_queue_中.也就是说人工修复是认为CRC错误的。然后在check的时候会根据类型进行do_repair_crc还是do_repair_eio操作,对各自类型进行错误统计,其中check_block的过程就是通过crc_error和eio_error数量来判断该Block是否过期(对于过期的逻辑块,在错误位图上进行相应物理块的设置),如果是,则请求Ns进行update_block_info, 如果不是,对于eio请求,则无法修复,设置Block不正常(abnormal)的最新时间,对于Crc的则尝试修复,修复过程中会从其他Ds上读副本来进行修复,若出错则会请求Ns进行update_block_info,否则设置Block不正常的最新时间。
客户端
TFS提供了Nginx模块,通过Nginx作为HTTP客户端可以实现对TFS的访问。
另外,TFS还提供了C++和Java库,允许程序员利用这些库开发自己的TFS客户端。