Mysql分组查询每组最新的一条数据(四种实现方法)
MySQL分组查询每组最新的一条数据
-
- 前言
- 注意事项
- 准备SQL
- 错误查询
-
- 错误原因
- 方法一
- 方法二(适用于自增ID和创建时间排序一致)
- 方法三(适用于自增ID和创建时间排序一致)
- 方法四(以创建时间为基准获取每个用户最新的一条数据,必须要添加对应字段的索引 最好是覆盖索引)
- 总结
-
- MAX()函数和MIN()这一类函数和GROUP BY配合使用存在问题
前言
在写报表功能时遇到一个需要根据用户id分组查询最新一条钱包明细数据的需求,在写sql测试时遇到一个有趣的问题,开始使用子查询根据时间倒序+group by customer_id发现查询出来的数据一直都是最旧的一条,而不是我需要的最新一条数据我明明已经倒序排了,后来总结出了三种解决方案如下。
注意事项
- 数据库版本 Mysql5.7+
- 执行 GROUP BY 语句的时候出现 sql_mode=only_full_group_by 解决方法(这里是Mysql8的解决方案,Mysql5.7也差不多自行百度即可)
-
1、执行 select @@sql_mode; 查看sql模式
select @@sql_mode;
-
2、将sql_mode中的only_full_group_by模式剔除 重新设置sql_mode值,如果是使用JDBC连接需要重启项目才能生效。
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'; set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
-
准备SQL
这里模拟一个sql
DROP TABLE IF EXISTS `customer_wallet_detail`;
CREATE TABLE `customer_wallet_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`customer_id` bigint(20) NULL DEFAULT NULL COMMENT '用户ID',
`happen_amount` varchar(15) NULL DEFAULT '0' COMMENT '发生金额 带-号的代表扣款',
`balance_amount` varchar(15) NULL DEFAULT '0' COMMENT '可用余额',
`create_time` bigint(20) NULL DEFAULT NULL COMMENT '发生时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB COMMENT = '用户钱包明细';
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (1, 1, '100', '100', 1670300656630);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (2, 1, '-10', '90', 1670300656640);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (3, 1, '5', '95', 1670300656650);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (4, 3, '998', '998', 1670300656660);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (5, 3, '-100', '898', 1670300656670);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (6, 3, '-98', '800', 1670300656680);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (7, 2, '666', '666', 1670300656690);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (8, 2, '-66', '600', 1670300656695);
INSERT INTO `customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `create_time`) VALUES (9, 2, '-600', '0', 1670300656699);
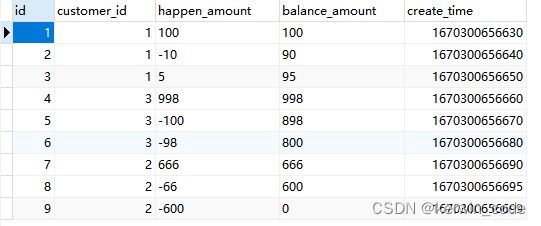
错误查询
SELECT
*
FROM
( SELECT * FROM customer_wallet_detail ORDER BY create_time DESC ) t1
GROUP BY
t1.customer_id;
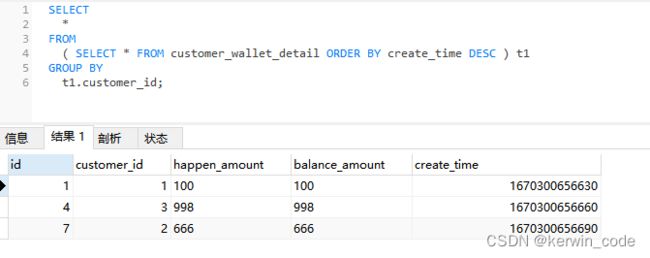
错误原因
在mysql5.7以及之后的版本,如果GROUP BY的子查询中包含ORDER BY,但是 GROUP BY 不与 LIMIT 配合使用,ORDER BY会被忽略掉,所以子查询在 GROUP BY 时排序不会生效,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序。
方法一
鉴于以上的原因我们可以添加上 LIMIT 条件来实现功能。
PS:这个LIMIT的数量可以先自行 COUNT 出你要遍历的数据条数(这个数据条数是所有满足查询条件的数据合,我这里共9条数据)
SELECT
*
FROM
( SELECT * FROM customer_wallet_detail ORDER BY create_time DESC LIMIT 9 ) t1
GROUP BY
t1.customer_id;
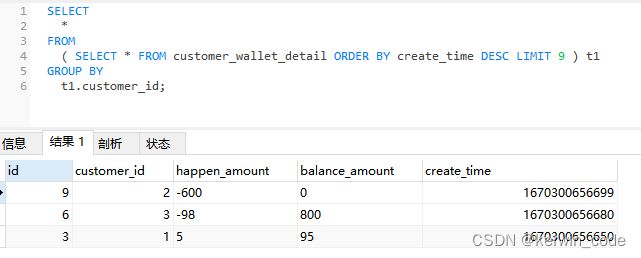
方法二(适用于自增ID和创建时间排序一致)
方法一需要先 COUNT 查询然后将查询结果设置到 LIMIT 条件中比较麻烦,这里还可以使用 MAX() 函数来实现该功能。
PS:因为我这里的业务数据是有序插入的,使用主键自增id和create_time结果是一样的而且使用id查询效率更高,如果没有唯一且有序的id可以替代create_time那么就用方案一,不能直接使用 SELECT id,MAX(create_time) 这种操作来获取最新一条数据id,原因在总结中有详细描述。
SELECT
*
FROM
customer_wallet_detail
WHERE
id IN ( SELECT MAX( id ) FROM customer_wallet_detail GROUP BY customer_id )
ORDER BY
customer_id;

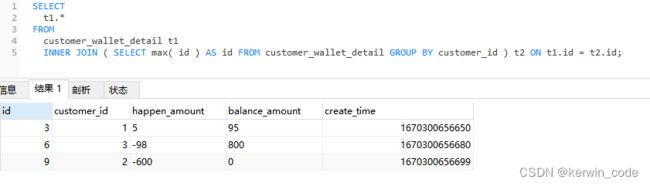
方法三(适用于自增ID和创建时间排序一致)
方法三和方法二实现逻辑基本一致只是将IN查询替换成了连接查询,本地20w条数据测试 方法三比方法二性能提升50%,有兴趣的可以增大数据集测试后续性能变化。
SELECT
t1.*
FROM
customer_wallet_detail t1
INNER JOIN ( SELECT MAX( id ) AS id FROM customer_wallet_detail GROUP BY customer_id ) t2 ON t1.id = t2.id
方法四(以创建时间为基准获取每个用户最新的一条数据,必须要添加对应字段的索引 最好是覆盖索引)
有朋友在评论区提供了第四种方法,这种方法在表数据量少的时候是可行的,我的测试表还是20w数据,并且customer_id字段加了索引,全部查询出来耗时在180s左右,我本地MySQL性能会差一点,这种查询方式是将 b1 中的每一条数据 都和 b2 中的每一条数据进行比对取出满足条件的数据,b1 有20w条数据 b2 也有20w条数据,如果没有索引不计算io开销,只算cpu开销,这条sql需要进行 20w * 20w = 400亿次数据比对,在有索引的情况下数据比对次数会少一些但是也千万级的,如果考虑其它开销并且没索引的情况下那查询耗时可想而知。
- 使用限制
- 1、这种方式其实除了性能问题以外还有一个更加严重的问题,在一些业务里给用户余额明细添加数据时可能同一时间戳添加多条,这样count结果就大于1了,这个用户数据就查不出来了,还有一种情况如果开发人员事务没有控制好,我们在入库时一般会提前将create_time填充,但是我们用的是自增ID,入库时create_time 小的,数据ID可能还会大一些,选择那种方法还是需要看业务上怎么设计的
SELECT
b1.*
FROM
customer_wallet_detail t1
WHERE
( SELECT COUNT( 1 ) FROM customer_wallet_detail t1 WHERE t2.customer_id = t1.customer_id AND t1.create_time <= t2.create_time ) <= 1;

PS:优化方案
- 1、针对这条语句的查询特性,我们减少数据的查询条数,比如给 t1和t2 添加上筛选时间区间,减少遍历数组总数。
- 2、使用覆盖索引,我自己在测试的时候发现如果使用组合索引包含两个字段 (customer_id,create_time) 性能会提升很多,20w数据查询出结果只用了40s,如果只使用customer_id字段索引会进行回表,使用覆盖索引没有额外的回表操作所以会快很多。
总结
结合我的业务经过测试,目前看来方案三是最合适的,sql简单性能适中,方案一比方案二性能更差而且实现麻烦,最终选择那个方案主要看业务而定。
MAX()函数和MIN()这一类函数和GROUP BY配合使用存在问题
MAX()函数和MIN()这一类函数和GROUP BY配合使用,GROUP BY拿到的数据永远都是这个分组排序最上面的一条,而MAX()函数和MIN()这一类函数会将这个分组中最大或最小的值取出来,这样会导致查询出来的数据对应不上。
- 正确查询:

- 错误查询:这里的确拿到每个分组最新创建时间了但是拿的数据id还是排序的第一条

