【Redis实战】认识Redis中的全局哈希表
文章目录
- Redis是如何支持基于Key的快速访问的
- 全局哈希表
-
- 哈希表结构
- 哈希冲突
- 一张图
- 相关源码
Redis是如何支持基于Key的快速访问的
一谈到Redis,马上能想到的就是:“快”,那么,Redis之所以快,一方面是因为Redis的所有操作都在内存中完成,内存操作本身就很快,另一方面就要归功于它的数据结构了,高效的数据结构是Redis快的基石。
全局哈希表
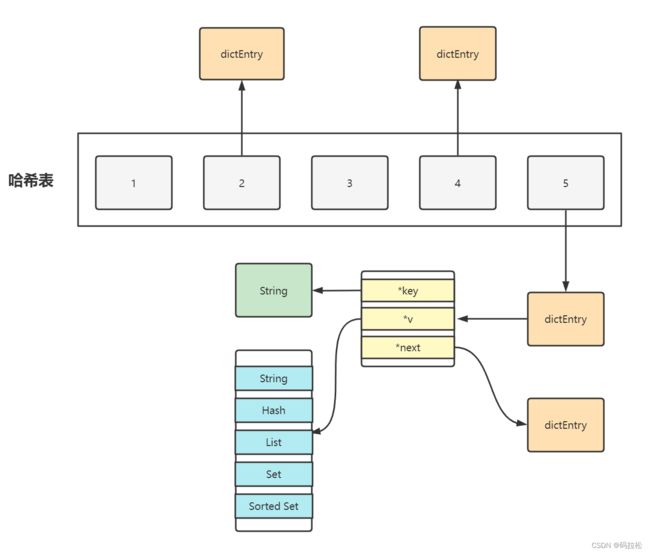
为了实现基于Key的快速访问,Redis采用了哈希表作为最底层的数据存储结构,如果你了解Java中的HashMap,那么理解Redis的哈希表则应该非常容易,实际上也就是数组+链表的结构,这样一来,我们就可以在O(1)的时间复杂度下快速的查找出所需的Key,并且无论是多少Key都不受影响。
我们先来看看哈希表的具体结构设计,每一个dictEntry元素,都保存了*key和*value的指针,*value指针保存在联合体v中,既然保存的是指针,所以也就能保存任何类型的数据结构(String,Hash,List,Set)
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
哈希表结构
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
哈希冲突
当然,提到哈希表,肯定少不了哈希冲突的问题,Redis中采用的方式和Java中的HashMap一样,都是链式哈希的方式,所以一旦冲突变多,就会导致链表过长,最终退化为O(n)的时间复杂度,这对Redis来说肯定是不能接受的。
所以,解决的方式也和Java中的HashMap一样,直接进行一次rehash操作就好了,简单来说就是扩大Entry数组的大小,从而来减少哈希冲突,当然为了不对线上访问造成影响,Redis还采用渐进式rehash的方式,实际上Redis每次在进行rehash操作时,会新准备一个比原哈希表大一倍的新哈希表,然后在每一次处理请求的时候,顺便处理一次数据迁移,比如从原哈希表的第一个索引位置开始,把这个位置上的Entry全部挪到新的哈希表中,这样通过分摊处理,就避免了一次性全量处理所带来的阻塞问题。
一张图
相关源码
就用Hash数据类型中的HGET方法举例
void hgetCommand(client *c) {
robj *o;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp])) == NULL ||
checkType(c,o,OBJ_HASH)) return;
addHashFieldToReply(c, o, c->argv[2]->ptr);
}
static void addHashFieldToReply(client *c, robj *o, sds field) {
int ret;
if (o == NULL) {
addReplyNull(c);
return;
}
// 如果底层数据结构是压缩列表的处理逻辑
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *vstr = NULL;
unsigned int vlen = UINT_MAX;
long long vll = LLONG_MAX;
ret = hashTypeGetFromZiplist(o, field, &vstr, &vlen, &vll);
if (ret < 0) {
addReplyNull(c);
} else {
if (vstr) {
addReplyBulkCBuffer(c, vstr, vlen);
} else {
addReplyBulkLongLong(c, vll);
}
}
// 如果底层是Hash表的处理逻辑
} else if (o->encoding == OBJ_ENCODING_HT) {
sds value = hashTypeGetFromHashTable(o, field);
if (value == NULL)
addReplyNull(c);
else
addReplyBulkCBuffer(c, value, sdslen(value));
} else {
serverPanic("Unknown hash encoding");
}
}
看Hash表的逻辑,基本上就是标准的Hash表查找方式
sds hashTypeGetFromHashTable(robj *o, sds field) {
dictEntry *de;
serverAssert(o->encoding == OBJ_ENCODING_HT);
de = dictFind(o->ptr, field);
if (de == NULL) return NULL;
return dictGetVal(de);
}
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
#define dictGetVal(he) ((he)->v.val)