详解yolov1理论 & 代码
目标检测要解决的3大问题:
1、有没有?
图片中是否有要检测的物体?(检测物体,判定前景背景)
2、是什么?
这些物体分别是什么?(检测到的物体是什么)
3、在哪里?
这些物体在哪里?(画框,描边,变色都行)
yolov1模型图

预测结果

当物体中心落到某个网格中,该网格就负责预测这个物体。
每个网络会生成两个预测框,所以yolov1共有 7x7x2=98个预测框,相对于fast-rcnn成百上千个预测框,yolov1少了很多。
每个预测框对应 维度为2x5 + 20 = 30的向量。
20代表:yolov1用的数据有20个类别。这20个类别用独热编码表示,是哪个类别就让该类别标记为1.
5代表 : 4个坐标和一个置信度。
置信度计算的是预测边框 与 真实边框的 IOU,IOU用来选择哪个边框作为预测边框。

参考:https://zhuanlan.zhihu.com/p/595221376
损失函数
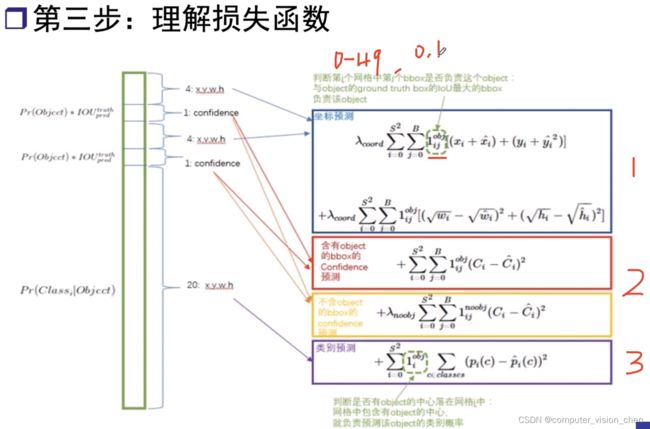
1.对坐标进行预测,坐标损失
预测第i个网格,的第j个bbox是否有该object。 方法是计算每个网格的两个bbox与真实框的IOU,IOU最大bbox对应的网格中包含这个object。


如果不用根号,则是个线性关系 w越大,该物体与小物体的loss就越大。模型的学习会收到它的影响,主要去满足大物体去了。
超参数 λ_coord 默认是5,是为了平衡非物体(背景)的bbox过多的影响。因为目标对于背景来说是很小的,损失函数占比的权重就很小。
置信度损失

此时加入了一个非物体的置信度和权重 λnoobj=0.5,如果 让一个网络去学习n个类别的分类,那么必须让网络学习n+1个类别的分类。1是背景。背景占比比较多,所以调小它的权重。
对类别进行预测
判断是否有object的中心落入网格中,网格中包含有object的中心,就负责预测该object的类别概率。
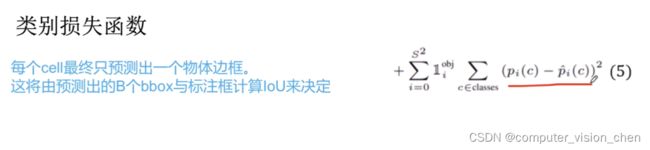
直接预测类别-真实类别,这个方法不好,后面Yolo对它改进。

拥挤物体的中心,会跑到一个网格中去,那么一个网络就会预测两个物体。很不好。
对小物体检测也不好,小物体权重小。
对不规则物体(长宽比不正常)
voc数据集
以PASCAL VOC2017为例,它包含如下5个文件夹:
Annotations
JPEGImages
ImageSets
SegmentationClass
SegmentationObject
JPEGImages
PASCAL VOC提供的所有的图片,其中包括训练图片,测试图片。
Annotations
xml格式的标签文件,每个xml对应JPEGImage中的一张图片。各个目标的位置和类别。以(x,y)的格式不保存坐标点。
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename> //文件名
<source> //图像来源(不重要)
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //图像尺寸(长宽以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //是否用于分割(在图像物体识别中01无所谓)
<object> //检测到的物体
<name>horse</name> //物体类别
<pose>Right</pose> //拍摄角度
<truncated>0</truncated> //是否被截断(0表示完整)
<difficult>0</difficult> //目标是否难以识别(0表示容易识别)
<bndbox> //bounding-box(包含左下角和右上角xy坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> //检测到多个物体
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
ImageSets
训练要用到的:
1.train.txt:训练集 (注意,均为图片名,没有后缀。以train.txt为例,分为两列,第一列为图像名如00012;第二列为-1和1,-1表示目标在对应的图像没有出现,1则表示出现。)
2.val.txt:验证集
3.trainval.txt:训练和验证集
# 训练用不到的其它内容
Action:人的动作
Layout:人体的具体部位
Main: 图像物体识别的数据,总共20类, 需要保证train val没有交集。
Segmentation:用于分割的数据
验证集(val)与测试集(test)是有区别的。
验证集:val是validation的简称,验证是否过拟合、以及用来调节训练参数等。
测试集:当模型训练完成后,用于检测模型的准确性。
https://blog.csdn.net/weixin_43570470/article/details/123659793
write_txt.py
'''
读取XML文件信息
'''
import xml.etree.ElementTree as ET
import os
import random
VOC_CLASSES = ( # 定义所有的类名
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor') # 使用其他训练集需要更改
# 创建两个文件用于存放
train_set = open('voctrain.txt', 'w')
test_set = open('voctest.txt', 'w')
Annotations = 'VOCdevkit/VOC2017/Annotations'
# 返回Annotations文件下的所有文件名 (里面是所有xml文件,一个图片对应一个xml文件,是对图片的标注)
xml_files = os.listdir(Annotations)
# 打乱数据集
random.shuffle(xml_files)
train_num = int(len(xml_files) * 0.7) # 设置训练集个数
train_lists= xml_files[:train_num] # 训练集列表
test_lists= xml_files[train_num:] # 测试集列表
def parse_rec(filename): # 输入xml文件名
tree = ET.parse(filename)
objects = []
# 读取xml文件中的 下的内容
'''
'''
for obj in tree.findall('object'):
# 创建一个结构体
obj_struct = {}
# 获取到 difficult元素,如果值为1,表示目标难以识别,则跳过
difficult = int(obj.findall('difficult').text)
if difficult ==1:
continue
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(float(bbox.find('xmin').text)),
int(float(bbox.find('ymin').text)),
int(float(bbox.find('xmax').text)),
int(float(bbox.find('ymax').text))]
objects.append(obj_struct)
return objects
def write_txt():
count = 0
for train_list in train_lists: # 生成训练集txt
count += 1
image_name = train_list.split('.')[0] + '.jpg' # 图片文件名
results = parse_rec(Annotations + train_list)
if len(results) == 0:
print(train_list)
continue
train_set.write(image_name)
for result in results:
class_name = result['name']
bbox = result['bbox']
class_name = VOC_CLASSES.index(class_name)
train_set.write(' ' + str(bbox[0]) +
' ' + str(bbox[1]) +
' ' + str(bbox[2]) +
' ' + str(bbox[3]) +
' ' + str(class_name))
train_set.write('\n')
train_set.close()
for test_list in test_lists: # 生成测试集txt
count += 1
image_name = test_list.split('.')[0] + '.jpg' # 图片文件名
results = parse_rec(Annotations + test_list)
if len(results) == 0:
print(test_list)
continue
test_set.write(image_name)
for result in results:
class_name = result['name']
bbox = result['bbox']
class_name = VOC_CLASSES.index(class_name)
test_set.write(' ' + str(bbox[0]) +
' ' + str(bbox[1]) +
' ' + str(bbox[2]) +
' ' + str(bbox[3]) +
' ' + str(class_name))
test_set.write('\n')
test_set.close()
if __name__ == '__main__':
write_txt()
最终生成的训练集和数据集标签如下:
红框中前四个数是左上和右下角坐标,第五个数是类别。
一个图片可能否有多个目标,所有可能会有多个红框。

yoloData.py
encoder结果是7x7x30 = 7x7x(20+5+5)
20是这个数据集有20类,两个5是因为让这7x7个格子,每个格式产生两个候选框。