prometheus 告警
prometheus 告警
1, prometheus 告警简介
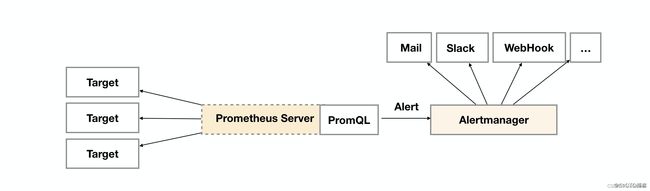
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。

在Prometheus中一条告警规则主要由以下几部分组成:
告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
1,1 自定义 prometheus 告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
1.2 定义告警规则
一条典型的告警规则如下
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
在告警规则文件中,我们可以将一组相关的规则设置定义在一个 group 下.每个 group 中我们可以定义多个告警规则(rule).一条告警规则主要由以下几部分组成:
alert: 告警规则的名称
expr: 基于 PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件
for: 评估等待时间,可选参数.用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生告警的状态为 pending
labels: 自定义标签,允许用户指定要附加到告警上的一组附加标签
annotations: 用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations 的内容在告警产生时会一同作为参数发送到 alertmanager.
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
rule_files:
[ - ... ]
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期:
global:
[ evaluation_interval: | default = 1m ]
1.3, 警报触发
prometheus 以一个固定时间间隔来评估所有规则,这个时间由evaluate_interval定义,我们将其设置为 15 秒.在每个评估周期,prometheus 运行每个警报规则中定义的表达式并更新警报状态:
警报的 3 种状态:
Inactive: 警报未激活;
Pending: 警报已满足测试表达式条件,但仍在等待 for 子句中指定的持续时间;
Firing: 警报以满足测试表达式条件,并且 Pending 的时间已经超过 for 子句中指定的持续时间.
Pending到Firing的转换可以确保警报更有效,且不会来回浮动。没有for子句的警报会自动从Inactive转换为Firing,只需要一个评估周期即可触发。带有for子句的警报将首先转换为Pending,然后转换为Firing,因此至少需要两个评估周期才能触发。
2, 报警组件 AlertManager
2.1 什么是 AlertManager?
我们在前面刚开始的时候也讲了,prometheus 是组件化的工具,从他的官方架构图上我们可以看得出来,prometheus server 只是 负责产生警告,他并不会处理警告,我们这个时候就需要 AlertManager组件来处理和消费告警.
Alertmanager接受到Prometheus的重置后,需要删除重复,分组,相互之间通过路由发送到正确的接收器,电子邮件,Slack,钉钉等。Alertmanager还支持沉默和警报抑制的机制。
2.1.1 分组
分组是指当出现问题时,Altermanager 会收到一个单一的通知,而当系统停机时,可能会成百上千的报警同时生成,这个时候就需要将这些告警信息分组了.
比如,一个机房内运行着 100 台物理机,当这个机房的网络出现问题,很有可能全部机器都不能正常监控了,那么如果每个机器网络不可达都发送消息,那么我们可能 会同时收到 100 条短信,那这个时候就不是报警短信了,他就会变成短信轰炸,那我们如果能把这种同类型\找出同一种影响的短信合并成一条来发送,那这不就美滋滋.
2.1.2 抑制
抑制是指当警报发出后,停止重复发送初始化警报引发其他错误的警报的机制。
例如当警报被触发