
相信对于“现代数据堆栈(Modern Data Stack)”这个名词,大家早已不陌生。但若问及其真正含义,往往又很难快速、准确地阐明。
事实上,对于我们的团队组织而言,吃透并灵活应用“现代数据栈”所能带来的价值与收益,将会是深远且符合发展趋势的。
Q1:什么是现代数据堆栈?
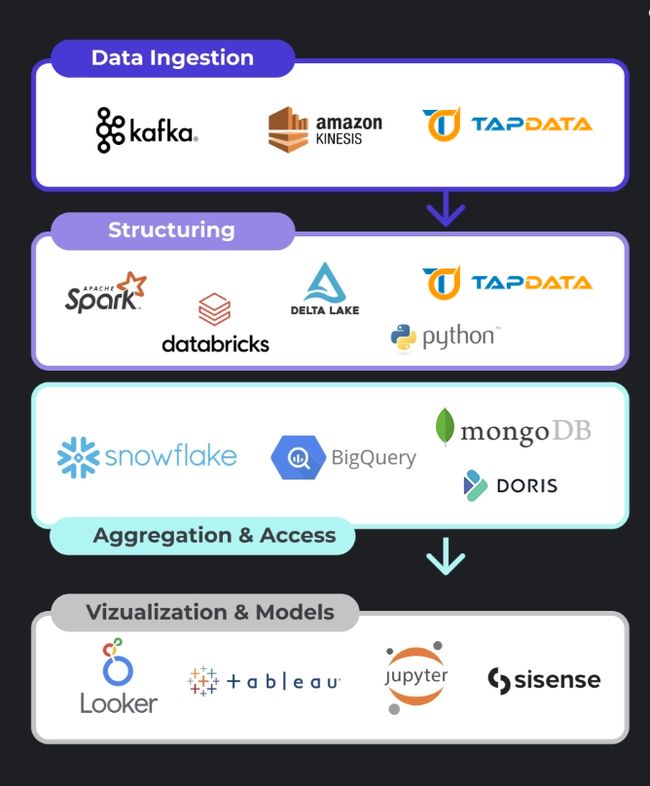
现代数据堆栈的流行伴随着云计算和云数据仓库的崛起,本质上是各种软件工具的组合,用于在一个完全集成的基于云的数据平台上收集、处理和存储数据。由于在稳定性、速度和可扩展性方面的突出表现,其在数据处理方面优势显著。
典型的现代数据堆栈通常包含:
- 抽取、转换、加载(ETL)工具
- 数据获取/集成服务
- 数据仓库
- 数据编排工具
- 商业智能(BI)平台
这些工具用于管理大数据,即无法通过传统方式处理的大型或复杂数据。它们将整个数字化建设过程拆分成了各个模块,让企业能够从眼下的问题出发,根据业务需求进行选型再组合,而不是像过去那样,一口气建立一个大一统的数据平台或数据中台。
Q2:现代数据堆栈具备哪些差异与优势?
- 提高可扩展性:借助现代数据栈,可以更轻松地根据实际场景进行扩展或缩小。堆栈中的各种工具可以一起使用,也可以单独使用,具体取决于自身需求。云的弹性能力可帮助组织按需使用所需的计算资源来执行重要的数据任务。当作业完成后,资源可以恢复到正常状态,从而最大限度地降低计算成本。
- 提高灵活性:现代数据堆栈也比传统数据堆栈更灵活。支持通过不同方式使用各种工具,以满足特定需求。数据堆栈中的服务可以根据需要添加或删除。这里的许多服务都采用基于消费的定价模式,这使得公司在开始迁移到云时无需预先承担巨大的软件采购费用。也有效避免了数据资产受限于特定供应商的状况。
- 提高效率:比传统数据堆栈更高效。堆栈中的工具在设计之初就对在云平台上协同工作更加友好,这有助于节省时间和资源。在云计算的支持下,更多的数据专业人员获得了访问数据的权限,例如:数据分析师可以使用 Tableau 等 BI 工具,数据科学家可以使用 Dataiku 等数据科学工具实现对数据仓库的访问。
- 更好的数据文化:现代数据堆栈有助于在组织内创建更好的“数据文化”。各种工具的设计都考虑到了可用性,因而无论员工的技术专长如何,都能更轻松地访问和使用数据。此外,现代数据堆栈的灵活性意味着组织成员不再受限于使用特定工具,可以自由选择最符合需求的。在良好的数据文化中,成员们可以通过搜索和发现为即时决策找到相关数据;提升数据素养,点亮解释和分析数据并得出合理结论的能力。从长远来看,现代数据栈还能够推进数据治理,加速落实数据工作流中某些类型数据的管理条例,当数据得到适当管理,成员们便能够以正确的方式使用正确的数据。
Q3:哪些人可以采用现代数据堆栈?
随着对数据“利用”以及数字化建设贯彻落实的要求越来越高,越来越多的企业,不论规模大小,都开始面临数据资产盘活的压力,并将最终受益于现代数据堆栈。
具体来讲,如果你的组织有数据需求,且围绕数据采集到数据分析、应用全流程各个环节设置了多种职能的团队,那么现代数据堆栈就是你的不二之选,因为它恰好可以很好地促进协作。
现代数据堆栈可以简化 IT 瓶颈,加快需要数据的各个团队的访问速度,包括
- 数据分析师
- 业务分析师
- 数据科学家
- 软件工程师
- 网站开发人员
- 数字分析师
- 云计算工程师
- 数据工程师
- 企业领导者
- ……
基本上,任何希望改善其数据管理的公司都可以采用现代数据堆栈。
如果想要现代化你的数据堆栈,有几点需要注意:首先,需要确定你需要哪些服务和工具,以及它们将如何协同工作;其次,需要找到一个能够支持你的现代数据堆栈的数据平台;再次,需要考虑如何将数据从传统系统迁移到新的现代数据堆栈;最后,需要培训团队如何使用现代数据栈中的新工具和服务。
虽然这看起来有一定的工作量,但数据堆栈现代化无疑是改善公司数据管理的好方法,其性价比和回报率都很可观。
Q4:如何构建一个现代数据堆栈?
构建一个现代数据堆栈并不像听起来那么复杂。只要理解了其中的组合逻辑,就会非常简单。下面让我们一步一步拆解来看:
① 选择一个数据仓库
市面上有许多数据仓库可供选择,需要我们基于自身实际充分调研。
这里可以广泛地分为两种类型:本地数据仓库和基于云的数据仓库。前者安装在公司的服务器上;后者则托管在云上,可以从任何地方访问。
优势上,云数据通常更便宜且更容易设置;本地数仓能够提供更多对数据的控制。大多数情况下,我们将选择云数仓合作伙伴作为现代数据堆栈的一部分。当然,受监管行业(如医疗保健或银行业)中的一些公司很多时候仍需要利用本地数据存储来遵守合规性规定。
② 选择一个数据采集工具并连接你的数据源
现在我们已经有了一个数据仓库,下面则需要将数据导入其中。最好的方法是使用数据采集工具,使用数据连接器或 API 的方式连接到我们的数据源连接到它。像是 Tapdata,就内置了大量连接器用于连接各种类型的数据源。
③ 选择一个数据转换工具清洗并准备数据
一旦数据导入了数据仓库,下面就需要通过清洗加工,将原始数据转换为有用的信息,以便进行分析。
④ 选择一个数据科学工具并进行数据分析
数据准备好之后,就可以开始进行数据分析了。数据科学工具可以帮助分析数据并生成见解。这些工具提供了各种数据分析和建模功能,可以帮助我们理解我们的数据。
⑤ 选择一个 BI 工具并可视化你的数据
最后,我们可以使用 BI 工具来完成数据可视化。一些流行的的 BI 工具可以帮助我们创建仪表盘、图表和报告,以便我们的团队更容易地理解数据。
综上所述,现代数据堆栈中蕴含着强大的能量,可以帮助企业做出更好的数据驱动决策。未来,我们可以期待从中看到更多创新。诚然,建立一个现代数据堆栈的确需要一些前期调研等工作,但一旦建立起来,将大大提高企业数据管理和分析的能力。不同的组织会根据其具体需求选择不同的工具和技术,而了解如何构建一个现代数据堆栈便是至关重要的第一步。
为了帮助更多团队入门并熟悉现代数据栈的方法论和实践,更深入地了解现代数据栈的优势和应用,同时也为大家的数据管理和分析工作提供一些启发。作为现代数据栈工具组合中的优秀代表,Tapdata 开源社区联合 MongoDB 开源社区以及 Doris 开源社区,发起现代数据栈主题系列 Meetup,汇集了业内领先的专家和创新技术,为大家带来多种现代数据栈工具的功能特性详解以及各工具组合应用的最佳实践分析等内容。
目前,我们的 Meetup 北京首站已上线,如果你想获取更多有关数据基础设施建设、现代数据栈搭建指南的干货,欢迎报名参与:
Modern Data Stack Meetup · 北京站
活动详情:
- 日期:2023年9月24日(周日)
- 时间:14:00-17:00
- 地点:北京市阿里中心 · 望京A座-望京A座-20F-03 万松书院
主办方:
- Tapdata 开源社区
- MongoDB 开源社区
- Doris 开源社区
- 特别支持:阿里云
嘉宾与议题:

分享简介:
自2015年的MongoDB 3.0版本以来,MongoDB在每一年都发布了重大版本更新,不断提供开发者所需要的实用功能。今年的MongoDB 7.0也不例外,它带来了一系列开发者喜爱的新特性,包括开发简化、性能提升、迁移简化和增强的安全性等方面的改进。这些特性旨在满足市场和客户不断提高的需求,MongoDB将一直在您身边,为您提供功能更强大、性能更卓越、开发更便捷的平台。

分享简介:
- Apache Doris 基本介绍与技术特性
- OLAP 中的数据更新:行更新与列更新
- 实时数据更新与极速分析如何兼得
- 高并发实时数据更新的挑战及解决方案
- 真实用户案例分享
- 总结与规划
在实时数据仓库的业务场景中,对于实时数据面对上游数据的变化,需要快速获取到数据变更记录并进行及时数据更新,以提升业务决策的时效性。
在 Apache Doris 2.0 版本中,我们对数据更新能力进行了全面提升,我们将 Merge on Write 写时合并的数据更新模式进行了全面增强,引入了全新的部分列更新能力。通过一系列优化,实现了在海量数据上的实时更新和极速分析能力。在本次分享中,我们将会对以上功能和优化进行详细的介绍。

分享简介:
在当今数据驱动的世界中,将数据整合、同步和建模变得至关重要。从“让数据有用”到“活用数据”,传统技术栈的弊端日益显露,发展现状正在催促我们引入更加灵活的技术栈,随着云数仓的兴起,现代数据栈的概念开始流行。Tapdata Cloud 便在现代数据栈工具生态中承担着数据采集、处理和准备阶段的任务,连接各类数据源,为各类数据管理需求提供轻量级实时数据平台解决方案。
本次分享将为大家详细讲解 Tapdata Cloud 在现代数据栈生态下的具体表现:
- 现代数据栈工具联合:解放数据力量
- Tapdata Cloud 云服务工具特性
- 数据实时数据同步至 SelectDB
- 多层级数据建模于 MongoDB

分享简介:
阿里云对象存储 OSS 作为数据湖底座,存放海量不同类型数据。本次分享将重点介绍如何通过阿里云对象存储的加速、存算分离、冷热分层能力,在各种数据存储与分析场景实现性能、成本和效率的优化。
活动收益:
通过本系列 Meetup,你将有机会:
- 聆听专家分享:了解现代数据栈的最新发展趋势,以及它如何应用于实际业务场景中
- 与技术专家互动:参与技术研讨会,与专家面对面交流,解决您在数据处理过程中的疑问和挑战
- 体验创新产品:熟悉各种现代数据栈相关的产品和解决方案,深入了解它们的功能和优势
- 结识技术同好:与更多技术爱好者建立联系,分享见解,共同探讨数据管理和分析的前沿话题
适宜人群:
无论您是数据工程师、数据科学家、数据架构师还是对现代数据栈感兴趣的技术爱好者,我们都热忱欢迎您的参与。通过该系列活动,我们希望能够和大家共同探索现代数据栈的未来,释放数据潜能,助力业务腾飞。
报名方式:
点击了解活动详情:https://www.slidestalk.com/MongoDB/mds_meetup_beijing/