知识图谱(2)词汇挖掘与实体识别
从非结构化的文本构建知识图谱中的节点涉及两个基本步骤:
- 词汇挖掘(Lexical Analysis):
任务:词汇挖掘主要关注文本中的词汇和单词的处理,包括分词、词干提取、停用词过滤等任务。
作用:
1.词汇挖掘有助于将自然语言文本转化为机器可处理的单词或短语,为后续的NLP任务提供了基础。
2.在构建知识图谱时,词汇挖掘有助于提取实体名称、关键词和短语,作为知识图谱中的节点或关系的标识符。
3.通过分析文本中的词汇统计信息,可以帮助识别热门话题、关键概念等,从而构建图谱的结构。 - 命名实体识别(Named Entity Recognition,NER):
任务:NER是一种信息提取任务,旨在从文本中识别出具有特定含义的命名实体,如人名、地名、组织名、日期、货币等。
作用:
1.在构建知识图谱时,NER用于从文本中抽取实体信息,这些实体通常是知识图谱的核心节点。
2.识别并标记文本中的命名实体,有助于构建知识图谱的实体类型和属性。
3.NER还可以帮助理解文本中的语义关系,识别出实体之间的关联信息,这对于知识图谱的构建和推理非常重要。
在构建知识图谱中,词汇挖掘和NER通常协同工作。首先,词汇挖掘有助于将文本分解为有意义的单词和短语,从中提取潜在的实体。然后,NER任务进一步识别和标记这些实体,并确定它们的类型。
目录
- 词汇挖掘
-
- 关键词挖掘
- 同义词挖掘
- 新词挖掘
- 新词挖掘实例
- 命名实体识别
-
- 实体识别的方法
- 实体识别实例
词汇挖掘
关键词挖掘
关键词挖掘包括多种方法:
基于特征统计
词频属于最简单的方法,我们把文本集合中出现频率高的词作为关键词,但是一些介词会误导判断,所以出现了TF-IDF(term frequency–inverse document frequency)。TF-IDF综合考虑了词在文本中的词频以及普遍重要性,简单理解为一个词语在某个文本中频率高,但在其他文本中频率低才作为关键词。
位置特征也可以作为关键词挖掘的方式,文本的标题,摘要,结论中的词更容易包含关键词。
另外在使用分类器判别是否为关键词时,会考虑词的固有属性:词的长度,词性,对应的句法成分,前缀,后缀等。
基于主题模型
主题模型的假设是,存在隐变量,即文本主题,决定了文本中词汇的出现情况。
比如有下面的一些文本:
明明养了一只狗和一只猫。
一般来说,猫比狗要安静些。
多吃香蕉有利于肠胃健康。
柿子最好不要空腹吃,相比于吃香蕉,明明比较喜欢柿子。
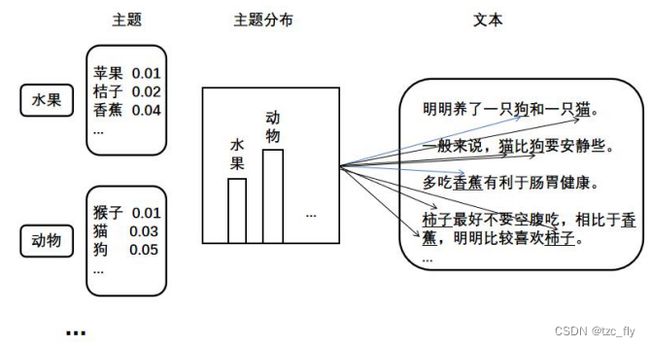
- 主题模型有两种分布:各个文本具有不同的主题分布(右);具体每个主题又具有单词的分布(左)。基于主题模型的方法要求我们根据给出的文本,计算这两个分布,然后获取每个主题下的高频词作为关键词。
从PageRank到TextRank
除了前面的两种方法,还有一种常用的方法是TextRank。这里首先从PageRank说起,PageRank用于体现网页的相关性和重要性,其要点为:
- 如果一个网页被很多其他网页链接到,说明这个网页比较重要,即PageRank值会比较高;
- 如果一个PageRank值高的网页链接到一个其他的网页,则被链接的网页的PageRank值也会相应提高。
TextRank是PageRank在文本上的应用,其思想为:
- 如果一个单词出现在很多单词的左右,说明这个单词比较重要;
- 一个TextRank值高的单词边的单词,TextRank值也会相应提高。
在TextRank中,对于建立单词之间的连接,有两种方式(分别为下图左右),一种是简单的基于窗口,另一种是基于句法分析建立连接(该方式可以考虑到远距离的单词连接):

同义词挖掘
语言中的同义词类型有:不同语言的互译(自行车,bike),相同含义的词(小花,花朵),不同称呼(番茄,西红柿;上海,沪;黑曼巴,科比)。
同义词挖掘方法有:
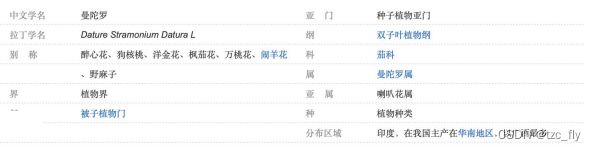
基于同义词资源
一种是使用字典,比如WordNet,汉语大词典,这些词典质量高,但是通常词汇覆盖不完整,比较老旧。另一种是使用百科,比如维基百科,百度百科中的info box部分。
基于模式匹配
手工设计固定的模式:
X又称Y
X(Y)
X简称Y
X,亦称Y
X,别名Y
X,俗称Y
用固定的模式从文本中匹配得到同义词,这种方式准确率虽然高,但是召回率很低。
基于Bootstrapping(自举法)
这是基于模式匹配的进一步方法,步骤为:
- 基于模式匹配发现同义词对;
- 根据同义词对发现更多模式;
- 重复上述过程;
比如下面的过程:

新词挖掘
对于文本:支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。铰链损失函数的思想就是让那些未能正确分类的和正确分类的之间的距离要足够的远。支持向量机使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。,分词后发现一些在当前词典中不存在但是高频的词汇及词汇组合,如“支持”+“向量机”、“铰链”+“损失函数”,则 “支持向量机” 以及 “铰链损失函数” 就可以作为我们新发现的词汇。
新词挖掘可以分为三个步骤:
- 基于N-gram统计获取出现频率较高的短语作为候选项;
- 对候选项进行多维度特征统计;
- 将多维度特征进行综合评估,排序,取top-K;
n-gram:假设当前词出现的概率仅仅与前面的 n-1 个单词相关
在新词挖掘中,还需要考虑:
- 自由凝固度:表示一个字串的凝固程度;
- 左邻字熵和右邻字熵:表示一个字串的左右搭配的丰富性;
这里先提一个案例,比如的教育和教育家,这两个出现频率都会高,但是教育家更像一个词(教育家的凝固度更高),在NLP中,PMI被用来度量词搭配与关联性,定义如下( w i , w j w_{i},w_{j} wi,wj表示组成单词的两个成分): P M I ( w i w j ) = l o g ( p ( w i w j ) p ( w i ) p ( w j ) ) PMI(w_{i}w_{j})=log(\frac{p(w_{i}w_{j})}{p(w_{i})p(w_{j})}) PMI(wiwj)=log(p(wi)p(wj)p(wiwj))这个式子的逻辑是: w i w j w_{i}w_{j} wiwj出现概率高,而两个成分分开出现的概率低,则越可能说明这两个成分是凝固的。
再举一个例子,比如混合和混凝,前者可以与更多词搭配,后者可能只能与土搭配,这就是自由运用程度,即左右邻字熵: P ( w i w j ) = − ∑ w ∈ W p ( w ) l o g p ( w ) P(w_{i}w_{j})=-\sum_{w\in W}p(w)log\thinspace p(w) P(wiwj)=−w∈W∑p(w)logp(w)其中, w w w为 w i w j w_{i}w_{j} wiwj左边或者右边可能出现的字。
新词挖掘实例
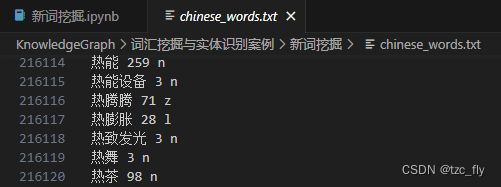
首先是最简单的基于频次的新词挖掘,这里用到一个已有的中文词典:
# 首先用jiaba进行分词
import jieba
text = "支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。\
支持向量机使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。\
铰链损失函数的思想就是让那些未能正确分类的和正确分类的之间的距离要足够的远。\
支持向量机可以通过核方法进行非线性分类,是常见的核学习方法之一。\
支持向量机被提出于1964年,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,\
在人像识别、文本分类等模式识别问题中有得到应用。"
words = jieba.lcut(text)
def get_chinese_words(file_path):
with open(file_path, "r", encoding = "utf-8") as f:
return [line.split()[0] for line in f.readlines()]
# 读取已有的中文字典
CH_DICT = set(get_chinese_words("chinese_words.txt"))
# 对文本中的一元词频(单字词频)和二元词频(双字词频,即相邻两个字组成的词)进行计数,同时过滤掉包含非中文字符的词语和二元词
import re
unigram_freq, bigram_freq = {},{}
for i in range(len(words)-1):
# 检查 words[i] 是否为非中文字符且不在 CH_DICT 中
if words[i] not in CH_DICT and not re.search("[^\u4e00-\u9fa5]",words[i]):
if words[i] in unigram_freq: # 一阶计数
unigram_freq[words[i]] += 1
else:
unigram_freq[words[i]] = 1
bigram = words[i]+words[i+1]
# 检查 bigram 是否为非中文字符且不在 CH_DICT 中
if bigram not in CH_DICT and not re.search("[^\u4e00-\u9fa5]",bigram):
if bigram in bigram_freq:
bigram_freq[bigram] += 1
else:
bigram_freq[bigram] = 1
unigram_freq_sorted = sorted(unigram_freq.items(), key = lambda d: d[1],reverse = True)
bigram_freq_sorted = sorted(bigram_freq.items(), key = lambda d: d[1],reverse = True)
print("unigram:\n",unigram_freq_sorted)
print("bigram:\n",bigram_freq_sorted)
词频结果为:
unigram:
[('机是', 1), ('边距', 1), ('化项', 1), ('中有', 1)]
bigram:
[('支持向量', 4), ('分类的', 3), ('向量机', 3), ('铰链损失', 2), ('损失函数', 2), ('正确分类', 2), ('向量机是', 1), ('机是一类', 1), ('一类按', 1), ('按监督', 1), ('监督学习', 1), ('学习方式', 1), ('方式对', 1), ('对数据', 1), ('数据进行', 1), ('进行二元', 1), ('二元分类', 1), ('的广义', 1), ('广义线性', 1), ('线性分类器', 1), ('其决策', 1), ('决策边界', 1), ('边界是', 1), ('是对', 1), ('对学习', 1), ('学习样本', 1), ('样本求解', 1), ('求解的', 1), ('的最大', 1), ('最大边距', 1), ('边距超平面', 1), ('机使用', 1), ('使用铰链', 1), ('函数计算', 1), ('计算经验', 1), ('经验风险', 1), ('风险并', 1), ('并在', 1), ('在求解', 1), ('求解系统', 1), ('系统中', 1), ('中加入', 1), ('加入了', 1), ('了正则', 1), ('正则化项', 1), ('化项以', 1), ('以优化结构', 1), ('优化结构风险', 1), ('是一个', 1), ('一个具有', 1), ('具有稀疏', 1), ('稀疏性', 1), ('性和', 1), ('和稳健性', 1), ('稳健性的', 1), ('的分类器', 1), ('函数的', 1), ('的思想', 1), ('思想就是', 1), ('就是让', 1), ('让那些', 1), ('那些未能', 1), ('未能正确', 1), ('的和', 1), ('和正确', 1), ('的之间', 1), ('之间的', 1), ('的距离', 1), ('距离要', 1), ('要足够', 1), ('足够的', 1), ('的远', 1), ('机可以', 1), ('可以通过', 1), ('通过核', 1), ('核方法', 1), ('方法进行', 1), ('进行非线性', 1), ('非线性分类', 1), ('是常见', 1), ('常见的', 1), ('的核', 1), ('核学习', 1), ('学习方法', 1), ('方法之一', 1), ('机被', 1), ('被提出', 1), ('提出于', 1), ('在二十世纪', 1), ('年代后', 1), ('后得到', 1), ('得到快速', 1), ('快速发展', 1), ('发展并', 1), ('并衍生', 1), ('衍生出', 1), ('出一系列', 1), ('一系列改进', 1), ('改进和', 1), ('和扩展', 1), ('扩展算法', 1), ('在人', 1), ('人像', 1), ('像识别', 1), ('文本分类', 1), ('分类等', 1), ('等模式识别', 1), ('模式识别问题', 1), ('问题中有', 1), ('中有得到', 1), ('得到应用', 1)]
以红楼梦一书为例,基于自由凝固度和左右邻字熵实现新词挖掘,txt文本为:
首先预处理文本:
# 读取数据
import re
def preprocess_data(file_path):
texts = []
with open(file_path, "r", encoding = "utf-8") as f:
for text in f.readlines():
text = re.sub("[^\u4e00-\u9fa5。?.,!:]","",text.strip())
text_splited = re.split("[。?.,!:]", text)
texts += text_splited
texts = [text for text in texts if text is not ""]
return texts
texts = preprocess_data("hongloumeng.txt") # 处理数据《红楼梦》一书,按照基本的标点符号进行切分
texts为处理后的列表:
['红楼梦曹雪芹',
'第一回甄士隐梦幻识通灵贾雨村风尘怀闺秀',
'此开卷第一回也',
'作者自云',
'因曾历过一番梦幻之后',
'故将真事隐去',
'而借通灵之说',
'撰此石头记一书也',
...
'由来同一梦',
'休笑世人痴']
获取已有的中文词典:
# 获取已有的中文词典
def get_chinese_words(file_path):
with open(file_path, "r", encoding = "utf-8") as f:
return [line.split()[0] for line in f.readlines()]
CH_DICT = set(get_chinese_words("chinese_words.txt"))
接下来需要对文本进行切分以及获取相关的频次信息,这里统一在一个函数中,主要逻辑如下:
- 对文本按照一定的长度范围进行切分,切分出所有成词的可能性,这里称之为字符串。
- 对于所有切分出的字符串进行过滤,长度大于等于 2 的词以及不是词典 CH_DICT 中的词作为候选新词。
- 获取所有切分出的字符串的频次信息(在后续计算中需要用到一些字符串的频次信息)、候选新词词频信息、候选新词左右出现的字的统计信息。
def get_candidate_wordsinfo(texts, max_word_len):
# texts 表示输入的所有文本,max_word_len 表示最长的词长
# 四个词典均以单词为 key,分别以词频、词频、左字集合、右字集合为 value
words_freq, candidate_words_freq,candidate_words_left_characters, candidate_words_right_characters = {},{},{},{}
WORD_NUM = 0 # 统计所有可能的字符串频次
for text in texts: # 遍历每个文本
# word_indexes 中存储了所有可能的词汇的切分下标 (i,j) ,i 表示词汇的起始下标,j 表示结束下标,注意这里有包括了所有的字
# word_indexes 的生成需要两层循环,第一层循环,遍历所有可能的起始下标 i;第二层循环,在给定 i 的情况下,遍历所有可能的结束下标 j
word_indexes = [(i,j) for i in range(len(text)) for j in range(i + 1, i + 1 + max_word_len)]
WORD_NUM += len(word_indexes)
for index in word_indexes: # 遍历所有词汇的下标
word = text[index[0]:index[1]] # 获取单词
# 更新所有切分出的字符串的频次信息
if word in words_freq:
words_freq[word] += 1
else:
words_freq[word] = 1
if len(word) >= 2 and word not in CH_DICT: # 长度大于等于 2 的词以及不是词典中的词作为候选新词
# 更新候选新词词频
if word in candidate_words_freq:
candidate_words_freq[word] += 1
else:
candidate_words_freq[word] = 1
# 更新候选新词左字集合
if index[0] != 0: # 当为文本中首个单词时无左字
if word in candidate_words_left_characters:
candidate_words_left_characters[word].append(text[index[0]-1])
else:
candidate_words_left_characters[word] = [text[index[0]-1]]
# 更新候选新词右字集合
if index[1] < len(text)-1: # 当为文本中末个单词时无右字
if word in candidate_words_right_characters:
candidate_words_right_characters[word].append(text[index[1]+1]) #
else:
candidate_words_right_characters[word] = [text[index[1]+1]]
return WORD_NUM, words_freq, candidate_words_freq, candidate_words_left_characters, candidate_words_right_characters
WORD_NUM, words_freq, candidate_words_freq, candidate_words_left_characters, candidate_words_right_characters = \
get_candidate_wordsinfo(texts = texts, max_word_len = 3) # 字符串最长为 3
计算PMI值和左右邻字熵:
import math
# 计算候选单词的 pmi 值
def compute_pmi(words_freq,candidate_words):
words_pmi = {}
for word in candidate_words:
# 首先,将某个候选单词按照不同的切分位置切分成两项,比如“电影院”可切分为“电”和“影院”以及“电影”和“院”
bi_grams = [(word[0:i],word[i:]) for i in range(1,len(word))]
# 对所有切分情况计算 pmi 值,取最大值作为当前候选词的最终 pmi 值
# words_freq[bi_gram[0]],words_freq[bi_gram[1]] 分别表示一个候选儿童村新词的前后两部分的出现频次
words_pmi[word] = max(map(lambda bi_gram: math.log(\
words_freq[word]/(words_freq[bi_gram[0]]*words_freq[bi_gram[1]]/WORD_NUM)),bi_grams))
"""
通俗版本
pmis = []
for bi_gram in bigrams: # 遍历所有切分情况
pmis.append(math.log(words_freq[word]/(words_freq[bi_gram[0]]*words_freq[bi_gram[1]]/WORD_NUM))) # 计算 pmi 值
words_pmi[word] = max(pmis) # 取最大值
"""
return words_pmi
words_pmi = compute_pmi(words_freq,candidate_words_freq)
print(words_pmi)
words_pmi为:
{'楼梦': 7.0587357419432335,
'楼梦曹': 9.870716865893675,
'梦曹': 6.286945434064175,
'梦曹雪': 8.733466784520152,
'曹雪': 7.509691352898036,
'雪芹': 6.388917492427074,
'一回甄': 3.804819724002924,
'回甄': 2.906744525095319,
'回甄士': 8.414218246100537,
'甄士': 6.468308097045223,
'士隐': 8.401639463893677,
'士隐梦': 9.10736542666048,
'隐梦': 4.044984962886565,
'隐梦幻': 10.294531112670036,
'梦幻识': 9.120158778120391,
'幻识': 5.331686482410129,
'幻识通': 10.294531112670036,
'识通': 4.127713678084193,
'识通灵': 9.014369169986555,
'通灵': 6.624772700002879,
'通灵贾': 9.0905583083441,
'灵贾': 0.484457206162542,
'灵贾雨': 8.745197124305642,
'贾雨': 3.2110174340356203,
'雨村': 8.3843424459642,
...}
计算邻字熵:
from collections import Counter
# 计算候选单词的邻字熵
def compute_entropy(candidate_words_characters):
words_entropy = {}
for word,characters in candidate_words_characters.items():
character_freq = Counter(characters) # 统计邻字的出现分布
# 根据出现分布计算邻字熵
words_entropy[word] = sum(map(lambda x: - x/len(characters) * math.log(x/len(characters)) , character_freq.values()))
return words_entropy
words_left_entropy = compute_entropy(candidate_words_left_characters)
words_right_entropy = compute_entropy(candidate_words_right_characters)
# 根据各指标阈值获取最终的新词结果
def get_newwords(candidate_words_freq,words_pmi,words_left_entropy,words_right_entropy,\
words_freq_limit = 15, pmi_limit = 6, entropy_limit = 1):
# 在每一项指标中根据阈值进行筛选
candidate_words = [k for k, v in candidate_words_freq.items() if v >= words_freq_limit]
candidate_words_pmi = [k for k, v in words_pmi.items() if v >= pmi_limit]
candidate_words_left_entropy = [k for k, v in words_left_entropy.items() if v >= entropy_limit]
candidate_words_right_entropy = [k for k, v in words_right_entropy.items() if v >= entropy_limit]
# 对筛选结果进行合并
return list(set(candidate_words).intersection(candidate_words_pmi,candidate_words_left_entropy,candidate_words_right_entropy))
get_newwords(candidate_words_freq,words_pmi,words_left_entropy,words_right_entropy)
得到的结果即为挖掘出的新词:
['在贾母',
'到如今',
'进园来',
'凤姐也',
...
'蘅芜',
'来瞧瞧',
'难为他',
'李纹',
'不告诉']
命名实体识别
命名实体识别(Name Entity Recognition,NER)也称为"专名识别",是指识别文本中具有特定意义的实体,包括人名,地名,机构名,专用名词等。NER对KG构建的意义重大,有了实体才能进一步关系抽取。NER本质上是一个序列标注任务,标注方式有BIO和BIOES两种:
- B:Begin,表示开始;
- I:Intermediate,表示中间;
- E:End,表示结尾;
- S:Single,表示单个字符;
- O:Other,表示其他,用于标记无关字符;
例子如下,该例子是对每个字进行标注:

该例子是对每个字进行标注,PER代表Person,ORG代表组织机构,LOC代表地方。我们也可以对一个序列进行分词,对分词进行NER序列标注。
对于通用的实体,NER可以直接用现有工具来做:Jieba,PKUSeg,Stanza,LTP等。
实体识别的方法
一般是基于概率图模型的方法,比如HMM和CRF。后期出现了基于深度学习的方法,比如BERT,BERT+CRF。
HMM
HMM是描述一个由隐藏的状态序列和显性的观测序列组合而成的随机过程。隐藏状态序列为命名实体标签,观测序列为文本。
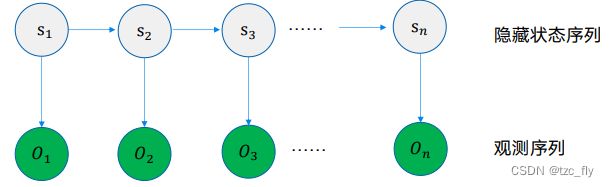
HMM的局限:
- HMM的连接关系比较简单,这是一种简化的假设,不适用于具有复杂句法的序列;
- HMM学习的是联合分布 P ( Y , X ) P(Y,X) P(Y,X),即 X X X序列和 Y Y Y序列一起出现的概率,但在NER中,预测问题需要的是条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X),即给定文本 X X X,预测序列标注 Y Y Y。也就是HMM的学习目标和预测目标是不匹配的。就像BERT不适合生成,GPT不适合分类。
CRF
CRF本身是一个很大的概念,在NER中,使用的是linear-chain CRF。可以这样理解,HMM是生成模型,CRF是判别模型,将HMM转化为判别模型就是linear chain CRF。
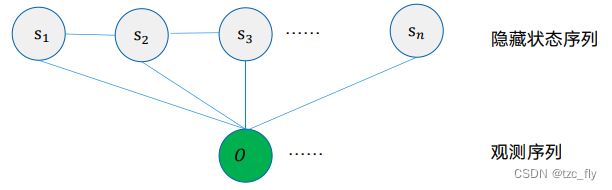
在上图中,这是无向图,用势函数计算概率: P ( S ∣ O ) = ( 1 / Z ) ∏ t = 1 n Φ ( s t − 1 , s t , O ) = ( 1 / Z ) e x p ∑ t = 1 n E ( s t − 1 , s t , O ) P(S|O)=(1/Z)\prod_{t=1}^{n}\Phi(s_{t-1},s_{t},O)=(1/Z)exp\sum_{t=1}^{n}E(s_{t-1},s_{t},O) P(S∣O)=(1/Z)t=1∏nΦ(st−1,st,O)=(1/Z)expt=1∑nE(st−1,st,O)其中, Z Z Z是正则化项, ( s t − 1 , s t , O ) (s_{t-1},s_{t},O) (st−1,st,O)形成一个最大团,在无向图中,最大团的势函数连乘即得到所有 S S S的概率分布。
对于 E ( s t − 1 , s t , O ) E(s_{t-1},s_{t},O) E(st−1,st,O)可分解为 m m m个状态函数之和+ n n n个转移函数之和,分别为如下含义:
- 每个 t t t时刻对应 m m m个状态函数,给当前时刻的状态特征打分;针对观测序列与状态的对应关系,比如"我"一般是"名词"。
- 每个 t t t时刻对应 n n n个转移函数,给当前时刻的状态转移特征打分;针对状态间的关系,比如"动词"后一般跟"名词"。
CRF目标是通过给定的有监督数据学习势函数中的参数,再用该模型做序列标注。
基于深度学习
现在更流行直接用深度学习模型做NER,或者深度学习模型+CRF做NER。
实体识别实例
这里使用Kashgari(https://github.com/BrikerMan/Kashgari)做NER,Kashgari基于tensorflow,在这个实例中的ner.h5包含两部分。
1.用BERT作为word embedding,chinese_L-12_H-768_A-12是BERT开源的预训练中文语言模型:
from kashgari.embeddings import BertEmbedding
bert_embed = BertEmbedding('chinese_L-12_H-768_A-12')
2.用BiLSTM+CRF作为序列标注模型,输入的词向量使用来自BERT的词向量,sequence_length=100指定了序列的长度,在深度学习NER中,输入通常是一个由embedding表示的序列,这里限制了序列的长度为100:
from kashgari.tasks.labeling import BiLSTM_CRF_Model
ner_model = BiLSTM_CRF_Model(bert_embed,sequence_length=100)
有监督数据为人民日报标注数据,验证结果为:
precision recall f1-score support
ORG 0.8962 0.8151 0.8537 1271
LOC 0.9014 0.9087 0.9051 1862
PER 0.9742 0.9601 0.9671 1103
训练后的权重为ner.h5,对输入进行预测:
def ner_predict(input_sen,model):
ners = model.predict([[char for char in input_sen]])
return ners
import kashgari
loaded_model = kashgari.utils.load_model('ner.h5')
input_sen = "新华社是个不错的单位"
ners = ner_predict(input_sen,loaded_model)
print(ners)
# [['B-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O']]