flink流写mysql实现exac,Flink SQL CDC 实践以及一致性分析
本文由民生银行王健、文乔分享,主要介绍民生银行 Flink SQL CDC 实践以及一致性分析。内容包括:背景
什么是 Flink SQL CDC Connectors
Flink SQL CDC 原理介绍
三种数据同步方案
Flink SQL CDC + JDBC Connector 同步方案验证
Flink SQL CDC + JDBC Connector 端到端一致性分析
Flink SQL CDC 目前存在的缺陷
一. 背景
数据准实时复制(CDC)是目前行内实时数据需求大量使用的技术,随着国产化的需求,我们也逐步考虑基于开源产品进行准实时数据同步工具的相关开发,逐步实现对商业产品的替代。我们评估了几种开源产品,Canal、Debezium、Flink CDC 等产品。作了如下的对比:

二.什么是 Flink SQL CDC Connectors
在 Flink 1.11 引入了 CDC 机制,CDC 的全称是 Change Data Capture,用于捕捉数据库表的增删改查操作,是目前非常成熟的同步数据库变更方案。
Flink CDC Connectors 是 Apache Flink 的一组源连接器,是可以从 MySQL、PostgreSQL 数据直接读取全量数据和增量数据的 Source Connectors,开源地址:https://github.com/ververica/...。
目前(1.11版本)支持的 Connectors 如下:
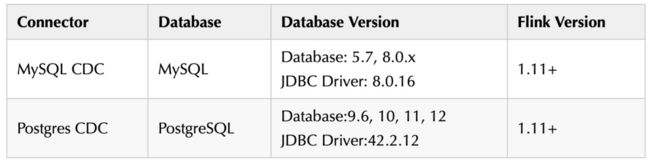
另外支持解析 Kafka 中 debezium-json 和 canal-json 格式的 Change Log,通过Flink 进行计算或者直接写入到其他外部数据存储系统(比如 Elasticsearch),或者将 Changelog Json 格式的 Flink 数据写入到 Kafka:

三. Flink SQL CDC 原理介绍
在公开的 CDC 调研报告中,Debezium 和 Canal 是最流行使用的 CDC 工具,这些 CDC 工具的核心原理是抽取数据库日志获取变更。在经过一系列调研后,我行采用的是 Debezium (支持全量、增量同步,同时支持 MySQL、PostgreSQL、Oracle 等数据库)。
Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将 changelog 转换为 Flink SQL 认识的 RowData 数据。(以下右侧是 Debezium 的数据格式,左侧是 Flink 的 RowData 数据格式)。

RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind 里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u 表示是 update 更新操作标识符(op 字段的值 c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
四. 三种数据同步方案
4.1 方案一:Debezium+Kafka+计算程序+存储系统
目前我行在生产上采用的就是这个方案,采用 Debezium 订阅 MySQL 的 Binlog 传输到 Kafka,后端是由计算程序从 Kafka 里消费,最后将数据写入到其他存储,架构类似如下:
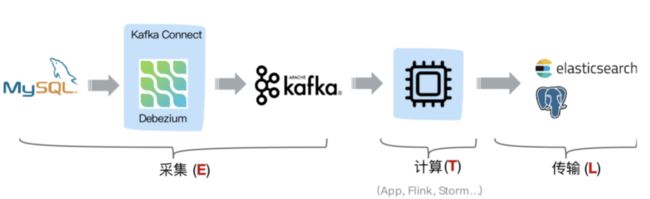
这种方案中利用 Kafka 消息队列做解耦,Change Log 可供任何其他业务系统使用,消费端可采用 Kafka Sink Connector 或者自定义消费程序,但是由于原生 Debezium 中的 Producer 端未采用幂等特性,因此消息可能存在重复,另外 Kafka Sink Connector(比如 JDBC Sink Connector 只能保证 At least once)或者自定义消费程序在保证数据的一致性上也有难度。
4.2 方案二:Debezium+Kafka+Flink SQL+存储系统
从第二章节我们知道 Flink SQL 具备解析 Kafka 中 debezium-json 和 canal-json 格式的 Change Log 能力,我们可以采用如下同步架构:

与方案一的区别就是,采用 Flink 通过创建 Kafka 表,指定 format 格式为 debezium-json,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统。方案二和方案一类似,组件多维护繁杂,而前述我们知道 Flink 1.11 中 CDC Connectors 内置了 Debezium 引擎,可以替换 Debezium+Kafka 方案,因此有了更简化的方案三。
4.3 方案三:Flink SQL CDC + JDBC Connector
将如下架构虚线部分用 Flink SQL 替换:

我们得到如下改进的同步方案架构:

从官方的描述中,通过 Flink CDC connectors 替换 Debezium+Kafka 的数据采集模块,实现 Flink SQL 采集+计算+传输(ETL)一体化,优点很多:开箱即用,简单易上手
减少维护的组件,简化实时链路,减轻部署成本
减小端到端延迟
Flink 自身支持 Exactly Once 的读取和计算
数据不落地,减少存储成本
支持全量和增量流式读取
binlog 采集位点可回溯
五. Flink SQL CDC + JDBC Connector同步方案验证
5.1 测试环境和脚本
测试环境测试场景 使用 Flink SQL CDC 从 MySQL 数据库同步数据到目标 MySQL,Kafka。CREATE TABLE sbtest1 (
id INT,
k INT,
c STRING,
pad STRING
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '197.XXX.XXX.XXX',
'port' = '3306',
'username' = 'debezium',
'password' = 'PASSWORD',
'database-name' = 'cdcdb',
'table-name' = 'sbtest1',
'debezium.snapshot.mode' = 'initial'
);
到DB:
create table printSinkTable (
id INT,
k INT,
c STRING,
pad STRING,
primary key (id) NOT ENFORCED
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://197.XXX.XXX.XXX:3306/mydb?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&serverTimezone=UTC',
'username' = 'debezium',
'password' = 'PASSWORD',
'table-name' = 'sbtest',
'driver' = 'com.mysql.cj.jdbc.Driver',
'sink.buffer-flush.interval' = '3s',
'sink.buffer-flush.max-rows' = '1',
'sink.max-retries' = '5');
INSERT INTO printSinkTable SELECT * FROM sbtest1;
到KAFKA:
CREATE TABLE kafka_gmv (
id INT,
k INT,
c STRING,
pad STRING
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'kafka_gmv',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '197.XXX.XXX.XXX:9092',
'format' = 'changelog-json'
);
INSERT INTO kafka_gmv SELECT * FROM sbtest1;
5.2 测试结论
■ 5.2.1 功能测试

■ 5.2.2 异常测试常规功能测试
 基于 DNS 的数据库切换测试
基于 DNS 的数据库切换测试
测试示意图:
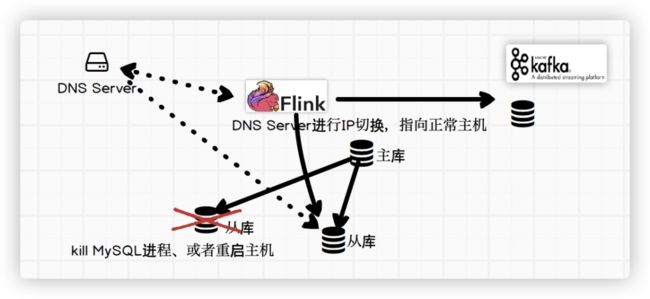
○ Flink 需要配置的参数:任务失败后延迟 5 秒重启,重试 10 次。restart-strategy: fixed-delay restart-strategy.fixed-delay.attempts: 10 restart-strategy.fixed-delay.delay: 5s。
○ MySQL 环境信息:一主库两个从库。
○ DNS 配置:DNS 申请了一个域名:XX.XX.cmbc.cn 策略:当前域名指向其中一个从库,探测数据库服务端口,每个 2 分钟自动探测一次。当前数据库异常后 DNS 修改指向到第二个从库。
○ 操作系统和 JVM 缓存配置:JVM 缓存配置 30 秒,操作系统缓存 30 秒。
测试结果:当 Flink 参数未设置上述参数的情况下,kill 当前访问数据库,Flink 任务报错退出,查看 DNS 没有访问记录。
Flink 配置上述参数后,Flink 后台尝试访问上述数据库,本地 DNS 缓存在访问失败的情况下失效,重新请求 DNS 域名服务器获取新数据库访问信息,任务继续复制。Flink 高可用测试
在 Flink 高可用测试中,我们使用 Standalone 集群高可用性方案进行测试,一个主 JobManager,一个从 JobManager,当主节点异常之后,备选节点成为新的 leader,并接管 Flink 集群。新 JobManager 成为新的 leader 后,集群恢复正常,并可以进行任务的调度,异常的任务恢复运行。
这里备选和主节点是一样的,也就是说每个 JobManager 都可以充当备选和主节点。官网的下图展示了这一过程:

异常测试步骤和结果如下:

■ 5.2.3 性能测试
性能测试进行了累计测试,用以检测 Flink cdc 的极限性能,分别测试了 kafka 和 MySQL 作为目标的场景。测试描述
使用 sysbench 进行压测,插入 200 余万数据,表结构如下:CREATE TABLE `sbtest1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`k` int(10) unsigned NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
);
累计性能测试结果:

六. Flink SQL CDC + JDBC Connector 端到端一致性分析
Flink SQL CDC + JDBC Connector 本质上是一个 Source 和 Sink 并行度为 1 的Flink Stream Application,Source 和 Sink 之间无 Operator,下面我们逐步分析 Flink SQL CDC + JDBC Connector 端到端如何保证一致性。
6.1 端到端一致性实现条件
一致性就是业务正确性,在“流系统中间件”这个业务领域,端到端一致性就代表 Exacly Once Msg Processing(简称 EOMP),即一个消息只被处理一次,造成一次效果。即使机器或软件出现故障,既没有重复数据,也不会丢数据。
幂等就是一个相同的操作,无论重复多少次,造成的效果和只操作一次相等。
流系统端到端链路较长,涉及到上游 Source 层、中间计算层和下游 Sink 层三部分,要实现端到端的一致性,需要实现以下条件:上游可以 replay,否则中间计算层收到消息后未计算,却发生 failure 而重启,消息就会丢失。
记录消息处理进度,并保证存储计算结果不出现重复,二者是一个原子操作,或者存储计算结果是个幂等操作,否则若先记录处理进度,再存储计算结果时发生 failure,计算结果会丢失,或者是记录完计算结果再发生 failure,就会 replay 生成多个计算结果。
中间计算结果高可用,应对下游在接到计算结果后发生 failure,并未成功处理该结果的场景,可以考虑将中间计算结果放在高可用的 DataStore里。
下游去重,应对下游处理完消息后发生 failure,重复接收消息的场景,这种可通过给消息设置 SequcenceId 实现去重,或者下游实现幂等。
在 Flink SQL CDC + JDBC Connector 方案中,上游是数据库系统的日志,是可以 replay 的,满足条件1“上游可 replay”,接下来我们分别分析 Flink SQL CDC 如何实现条件 2 和 3,JDBCConnector 如何实现条件 4,最终实现端到端的一致性。以 MySQL->MySQL 为例,架构图如下(目前 Flink SQL 是不支持 Source/Sink 并行度配置的,Flink SQL 中各算子并行度默认是根据 Source 的 Partition 数或文件数来决定的,而 DebeziumSource 的并行度是 1,因此整个 Flink Task 的并行度为 1):

6.2 Flink SQL CDC 的一致性保证
Flink SQL CDC 用于获取数据库变更日志的 Source 函数是 DebeziumSourceFunction,且最终返回的类型是 RowData,该函数实现了 CheckpointedFunction,即通过 Checkpoint 机制来保证发生 failure 时不会丢数,实现 exactly once 语义,这部分在函数的注释中有明确的解释。/**
* The {@link DebeziumSourceFunction} is a streaming data source that pulls captured change data
* from databases into Flink.
* 通过Checkpoint机制来保证发生failure时不会丢数,实现exactly once语义
*
The source function participates in checkpointing and guarantees that no data is lost
* during a failure, and that the computation processes elements "exactly once".
* 注意:这个Source Function不能同时运行多个实例
*
Note: currently, the source function can't run in multiple parallel instances.
*
*
Please refer to Debezium's documentation for the available configuration properties:
* https://debezium.io/documentation/reference/1.2/development/engine.html#engine-properties
*/
@PublicEvolving
public class DebeziumSourceFunction extends RichSourceFunction implements
CheckpointedFunction,
ResultTypeQueryable {
为实现 CheckpointedFunction,需要实现以下两个方法:public interface CheckpointedFunction {
//做快照,把内存中的数据保存在checkpoint状态中
void snapshotState(FunctionSnapshotContext var1) throws Exception;
//程序异常恢复后从checkpoint状态中恢复数据
void initializeState(FunctionInitializationContext var1) throws Exception;
}
接下来我们看看 DebeziumSourceFunction 中都记录了哪些状态。/** Accessor for state in the operator state backend.
offsetState中记录了读取的binlog文件和位移信息等,对应Debezium中的
*/
private transient ListState offsetState;
/**
* State to store the history records, i.e. schema changes.
* historyRecordsState记录了schema的变化等信息
* @see FlinkDatabaseHistory
*/
private transient ListState historyRecordsState;
再回到端到端一致性的条件 2 和 32.记录消息处理进度,并保证存储计算结果不出现重复,二者是一个原子操作,或者存储计算结果是个幂等操作,否则若先记录处理进度,再存储计算结果时发生failure,计算结果会丢失,或者是记录完计算结果再发生failure,就会replay生成多个计算结果。
3.中间计算结果高可用,应对下游在接到计算结果后发生failure,并未成功处理该结果的场景,可以考虑将中间计算结果放在高可用的DataStore里。
我们发现在 Flink SQL CDC 是一个相对简易的场景,没有中间算子,是通过 Checkpoint 持久化 binglog 消费位移和 schema 变化信息的快照,来实现 Exactly Once。接下来我们分析 Sink 端。
■ 6.2.1 JDBC Sink Connector 如何保证一致性
我们在官网上发现对于 JDBC Sink Connector 的幂等性中有如下解释:如果定义了主键,JDBC 写入时是能够保证 Upsert 语义的, 如果 DB 不支持 Upsert 语法,则会退化成 DELETE + INSERT 语义。Upsert query 是原子执行的,可以保证幂等性。
这个在官方文档中也详细描述了更新失败或者存在故障时候如何做出的处理,下面的表格是不同的 DB 对应不同的 Upsert 语法:Database Upsert Grammar
MySQL INSERT .. ON DUPLICATE KEY UPDATE ..
PostgreSQL INSERT .. ON CONFLICT .. DO UPDATE SET ..
因此我们可以通过写入时保证 Upsert 语义,从而保证下游 Sink 端的幂等性,再 Review 一次到端到端一致性实现条件 4,下游去重也可以通过实现幂等从而实现下游的 Exactly Once 语义。4.下游去重,应对下游处理完消息后发生 failure,重复接收消息的场景,这种可通过给消息设置 SequcenceId 实现去重,或者下游实现幂等。
■ 6.2.2 Flink SQL CDC + JDBC Sink Connector 组合后如何保证一致性
在前两小节我们分析了组件各自如何保证一致性,接下来,我们分析组合后在源库异常、Flink 作业异常、目标库异常三种异常场景下如何保证端到端一致性。
 Debezium Source 对 MySQL 进行 Snapshot 时发生异常
Debezium Source 对 MySQL 进行 Snapshot 时发生异常
在 Flink Task 启动后,首先会进行 MySQL 全表扫描,也就是做 Snapshot,这里有个需要注意的地方就是,在 Snapshot 阶段,在扫描全表数据时,没有可用于恢复的位点,所以无法在全表扫描阶段去执行 Checkpoint。为了不执行 Checkpoint,MySQL 的 CDC 源表会让执行中的 Checkpoint 一直等待(通过持有 checkpoint 锁实现),甚至 Checkpoint 超时(如果表超级大,扫描耗时非常长)。这块可以从 DebeziumChangeConsumer 的代码中看到:@Override
public void handleBatch(
List> changeEvents,
DebeziumEngine.RecordCommitter> committer) throws InterruptedException {
try {
for (ChangeEvent event : changeEvents) {
SourceRecord record = event.value();
deserialization.deserialize(record, debeziumCollector);
if (isInDbSnapshotPhase) {
if (!lockHold) {
MemoryUtils.UNSAFE.monitorEnter(checkpointLock);
lockHold = true;
//在snapshot阶段不做checkpoint
LOG.info("Database snapshot phase can't perform checkpoint, acquired Checkpoint lock.");
}
if (!isSnapshotRecord(record)) {
MemoryUtils.UNSAFE.monitorExit(checkpointLock);
isInDbSnapshotPhase = false;
LOG.info("Received record from streaming binlog phase, released checkpoint lock.");
}
}
// emit the actual records. this also updates offset state atomically
emitRecordsUnderCheckpointLock(debeziumCollector.records, record.sourcePartition(), record.sourceOffset());
}
...
在做 Snapshot 阶段,可能会碰到源库 MySQL 异常或者 Flink 任务本身异常,那我们分别分析下异常后如何恢复:若遇到源库 MySQL 异常,Flink Task 发现无法连接数据库异常退出,重新启动 Flink Task(或者 retry),因为没有做 snapshot 没做 checkpoint,那么会重新再做一次 Snapshot,这些全量数据最后发送到目的 MySQL,由于下游 MySQL 实现了写幂等,因此最终保持一致性。
若遇到 Flink 任务异常,重新启动(或者 retry),同上面情况一样,重新做一次 Snapshot,最终也能保持一致性。
若遇到目标库 MySQL 异常,同场景一一致,Flink Task 无法往目标数据库写入异常退出,在需要重新启动或 retry 后,重新做一次 Snapshot,全量数据最后发送到目的 MySQL,由于目的下游 M 有 SQL 实现了写幂等,最终保持一致性。Snapshot 完成后读取 binlog 时发生异常
在全量数据完成同步后,开始进行增量获取,此时 Flink 会进行定时 Checkpoint,将读取 binlog 的位移信息和 schema 信息存入到 StateBackend,若此时发生异常,那我们分析下异常后如何恢复:若源 MySQL 异常,Flink Task 发现无法连接数据库异常退出,重新启动 Flink Task(或者 retry),将会从最近一次 Checkpoint 的数据进行恢复,由于可以读取到 mysql binlog 位移信息,实现继续同步,不会丢失数据,最终也能保持一致性。
若 Flink 任务异常,重新启动或 retry 后,同场景 1 一致,继续读取 binlog,能保持一致性。
若目的 MySQL 异常,jdbc connector 无法往目标数据库写入,cdc connector 读取到的 binlog 位移信息也不再更新,两个操作是一个原子性操作,在 Flink Task 恢复后,从最近一次 Checkpoint 进行恢复,最终保持一致性。
6.3 总结
分布式系统中端到端一致性需要各个组件参与实现,Flink SQL CDC + JDBC Connector 可以通过如下方法保证端到端的一致性:源端是数据库的 binlog 日志,全量同步做 Snapshot 异常后可以再次做 Snapshot,增量同步时,Flink SQL CDC 中会记录读取的日志位移信息,也可以 replay
Flink SQL CDC 作为 Source 组件,是通过 Flink Checkpoint 机制,周期性持久化存储数据库日志文件消费位移和状态等信息(StateBackend 将 checkpoint 持久化),记录消费位移和写入目标库是一个原子操作,保证发生 failure 时不丢数据,实现 Exactly Once
JDBC Sink Connecotr 是通过写入时保证 Upsert 语义,从而保证下游的写入幂等性,实现 Exactly Once
再来回顾一下端到端保持一致性的条件,发现全都能满足。
1.上游可以 replay,否则中间计算层收到消息后未计算,却发生 failure 而重启,消息就会丢失。
2.记录消息处理进度,并保证存储计算结果不出现重复,二者是一个原子操作,或者存储计算结果是个幂等操作,否则若先记录处理进度,再存储计算结果时发生 failure,计算结果会丢失,或者是记录完计算结果再发生 failure,就会 replay 生成多个计算结果。
3.中间计算结果高可用,应对下游在接到计算结果后发生 failure,并未成功处理该结果的场景,可以考虑将中间计算结果放在高可用的 DataStore 里。
4.下游去重,应对下游处理完消息后发生 failure,重复接收消息的场景,这种可通过给消息设置 SequcenceId 实现去重,或者下游实现幂等。
七. Flink SQL CDC 目前存在的缺陷使用正则匹配原表后(多个源端表),到目标表无法进行一对一的映射。需要逐个匹配。
CDC source 端定义时,需要指定所有字段,目前不支持省略字段定义。
CDC 到 KAFKA 时无法按照主键进行自动分区分发、无法指定分区键分发数据。到 KAFKA 的数据格式指定(JSON,AVRO JSON等)。
目标端支持需求:DB2、ADB/GreenPlum、Oracle 暂不支持。不支持 DDL同步,不支持表的创建。
任务管理和监控的 REST API 不完善。
参考资料:
作者介绍:
文乔:2012 年硕士毕业后加入民生银行生产运营部系统管理中心,天眼日志平台主要参与人,目前在开源工具组负责 Flume、Kafka 的源码研究和工具开发等相关工作。
王健:2011 年加入民生银行科技部,数据库管理员(负责 DB2,Oracle,MySQL 等运维工作,对 MPP 等数据库有很长的维护和实施经验,擅长数据迁移等等),同时负责行内 KAFKA 集群运维和实施工作,负责行内数据库实时复制等工作。