mysql云数据库架构设计_MySQL云数据库架构设计与实践的分享-爱可生
原标题:MySQL云数据库架构设计与实践的分享-爱可生
1.MySQL 8.0
MySQL是一个有二十多年历史的开源数据库,也是时下互联网最流行的开源数据库。爱可生大概从2006年开始做面向各类传统行业客户的MySQL应用推广和技术服务工作,到现在大概十二年的时间了。
MySQL 8.0在4月19号刚刚发布有非常多的新的特性,在此挑选了比较重要的几点来跟大家分享。
首先是 MySQL SQL + NOSQL的新架构。近几年互联网的蓬勃发展,新兴的许多NOSQL数据,比如文档型数据库MongoDB。考虑到此类业务场景的需求,MySQL 5.7版本中也支持了Json的数据类型,便于操作Json格式的用户函数。MySQL 8.0在此基础上做了更多的优化并且开放了新的X 协议,用来支持NoSQL的API接口。在MySQL系统内既能使用SQL查询,也能使用NoSQL API方式,并且Java、Python、.NET等官方连接器都已加入了X协议的支持,X 协议默认是开启的33060端口。这也体现了MySQL在持续优化,广泛吸纳开源社区的建议。
关于SQL支持,以往MySQL给大家的印象是SQL支持简单,不支持复杂类查询比如说窗口函数,CTE等。MySQL 8.0 在SQL支持上也做了较多改进,在这些方面目前已基本上和其他的开源数据库甚至一线的商业数据库不相上下,甚至有一些地方支持的更好,比如Json部分,这部分MariaDB和PG都没有完全支持,这个地址有更详细的介绍:
2.为什么需要DBaaS
接下来主要介绍DBaaS 平台的架构演进以及我们的技术选型。为什么需要DBaaS,主要是基于以下三点原因:
降低开源数据库使用门槛
手工->自动化->自助化
服务标准化
这届DTCC的总体感受有大量和NewSQL数据库相关的主题,各个大厂都在做自己的基于开源数据库的分支。爱可生还是以支持原生MySQL版本为主,这个也是大家使用最多的,也可以解决大部分业务场景,我们希望帮助更多传统企业,没有太多自研能力的客户更好的使用它。
自动化运维发展的越来越成熟,随着数据库实例的快速增长,运维方式在从手工到自动化,再到自助化的过程,将数据库服务化更快更便捷的提供服务能力给业务方,支持业务的快速发展,不让数据库成为业务发展的瓶颈。
服务的标准化,业务方不需要关心数据库的底层架构,只提需求,平台自动分配资源提供可靠的数据库服务,将数据库服务做成一种标准服务,这些是DBaaS的重要意义。

大概在2011年,我们开始了第一代设计,那时在帮移动研究院做一个MySQL RDS平台,就是把MySQL包装成标准服务提供给移动企业客户。这代架构比较简单,在控制平面的Manager端负责接受用户服务请求,下发指令给Agent端;MySQL用来存管理信息,DBA通过Manager操作管理数据库实例。每个数据库服务器部署的Agent管理该主机的MySQL服务。
第一代的设计主要是通过shell脚本去完成数据库的基本自动化工作,Manager和Agent用Java来开发,Java调用shell脚本。DBA来开发脚本,开发来开发调度框架。

第二代设计我们改良了一代基础上的一些问题,比如高可用,第一代设计通过脚本的方式只能做到一些简单的Failover切换,但无法做到MySQL快速failover。第二代的设计基本架构不变,将Manager做了拆分,它拆分出来web服务层和调度层。增加了额外的HaServer组件,来解决MySQL主从Failover切换。
存在的问题:
环境依赖,测试覆盖不足
没有扩展性,功能全部耦合
Failover无法保证数据一致性
配置管理存在单点
监控、告警依赖第三方监控平台
备份计划依靠定时任务,缺失恢复演练
3.设计考量
为了解决这些问题,在第三代设计上我们对架构做较大的调整和重构,包括这些设计上的考量。
开发语言Golang/Python/Java
架构设计
按功能进行微服务拆分
故障域小
可按功能独立升级
可降级运行
逐级守护
自检告警
反向告警
支持VPC网络
安全性
RPC链路加密GRPC with TLS, 每个服务器生成私钥
日志无明文密码,落地加密保存
审计日志
Linux capabilities机制权限细分,避免使用root和sudo

三代的架构中,我们把很多功能拆成多个微服务组件,增加了中间件部分。在组件的命名上里都以U打头,因为MySQL是My,我们就取Your谐音。哈哈。
控制层面:
Ucore是用来做配置管理的,原来是MySQL单点,如果要解决它的高可用意味着需要给它挂备节点去冗余它,Ucore是一个分布式KV存储,自带的高可用特性,leader节点挂了会自动选举新的leader节点。整个集群的配置信息的保存在这里,其余组件注册后会看到全局配置信息。
UMC是面向DBA的管理入口,集群管理操作是从UMC进入,而URDS是面向开发者提供自服务的入口,开发可以通过该入口申请需要的数据库服务,并管理自己的数据库。
Urman 组件是负责数据库备份调度管理,所有数据库实例的备份任务调度都是通过Urman服务去控制,其对应的Agent接收Urman发出的请求和指令,Agent执行备份操作。
Umonitor是用来做监控数据汇总和展示,它从Ustat中拉去监控数据。
Ustat负责性能数据的采集,包括数据库服务的性能指标及系统层面的资源监控。
Uguard负责MySQL服务的高可用切换,Uguard-mgr做切换决策,Uguard Agent负责决策的执行。
数据层面:
在物理机上部署多个MySQL实例,实例间采用Cgroup方式做资源隔离,包括CPU、内存以及磁盘IOPS,用磁盘配额方式管理磁盘空间,资源的规格由管理员来设定。
Proxy层面:
Uproxy,解决需要读写分离的业务场景,它是一个透明的读写分离中间件,所谓透明就是业务不需要改造,不需要划分读地址,写地址,只提供一个入口,业务直接访问中间件。它会自动做读写分离,事务发往主节点,非显式事务的查询语句发往从节点,我们做了大量优化尽可能减少中间件的性能损耗。
Ushard,解决数据需要水平扩展的业务场景,使用数据分片方式,根据业务场景选择合适的拆分字段和拆分函数将数据分散到多个数据节点。
Proxy层面也有高可用守护,这样整个集群都没有单点的风险。
我们的目标是把这几种架构全部在一个平台管理起来,建议一套统一的运维管理体系,当然现在已经实现了这个目标。
4.服务可用性设计
关于服务可用性,主要通过以下几个维度来介绍。
不只是切换
Slave 写了数据怎么办
Slave的可用性
复制链路的可用性
决策者的可用性
切换
首先,MySQL切换只是其中一个环节,影响业务连续性的因素我们都要考虑到。比如从机实例的服务状态,从机不能被写数据,复制链路的状态、降低这些因素的影响才能保障较高的可用性。
我梳理了下MySQL的切换流程大概有11个步骤
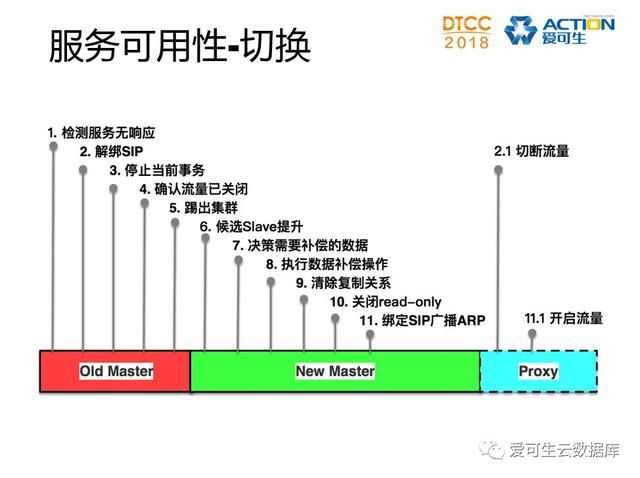
逐层守护
逐层守护的意思是指,每层服务都会有它的上层服务负责可用性守护,最外层是数据库服务,然后是守护数据库的客户端层,再是管理端层,最后是核心层Ucore。

SLA
SLA是一种辅助切换决策的量化机制。不同业务类型的数据库对可用性和数据一致性的要求是不一样的,比如说日志系统,对可用性诉求大于数据一致性; 而交易类系统,数据一致性是必须的。因此我们定义了两种协议,一种是RPO协议,一种是RTO协议。RPO协议保障数据的RPO级别,包含P和PE两类级别,P类是主从日志无差异,存在一定延迟级别就告警,PE类是日志有差异时不做切换由人工干预。

RTO是保障服务连续性需求,也分为两类级别T和TE,T类是切换前如果日志有差异最多允许补偿多久。TE类是日志差异较大超过所允许的丢失的极限,这时需要人工干预。设置好SLA协议,故障时会根据协议决策切换逻辑。
5.数据可用性
数据可用性包括了两部分,数据的备份和数据恢复演练。
定义一个运维时间窗口,备份调度器会根据备份策略编排任务,如果设置了转储设备,再自动将备份集转储。
除了备份以外还有演练,如果只是做完备份就不管了。当需要恢复时也不知道是否一定可恢复,这就需要定期进行演练。我们可以在平台中设置恢复演练任务,自动帮你做恢复演练,把恢复演练做到日常中除了有备份的,也有演练的任务,这个演练的任务会对你的备份集进行一个恢复的演练。备份产生了以后我们就会在一台演练机上来做恢复,检测这个备份是否能够恢复出来。能恢复出来我们就会认为这个备份机是OK的,其实就是把演练做到了日常中。
6.监控设计
监控我们原来用的zabbix,现在的选型是Prometheus监控框架,它是时序型存储数据比较紧凑也便于查询,用Grafana展现监控数据,数据采集我们做成单进程模式,利用go channel并行采集多个服务数据。
7.DTS设计
数据传输服务主要我们解决数据迁移的应用场景,比如 分布式集群里分片迁移。它的设计要点包括以下内容:
l 分布式架构
l 窄带宽下传输效率高于原生
l 全量+增量传输
l 支持GTID
l 支持并行回放
l 输出端支持kafka
l 支持 multi-master, star, fan-in 多种拓扑
l 兼容阿里云、微软云、原生MySQL
它还可以用于上云,下云,云间的数据迁移。这个是DTS的架构和设计图。

Manager是Leader+Follower架构,自动选主,它负责迁移任务下发。Agent既可以作为数据的提取端,也可以作为数据的回放端。通过提取端可以从MySQL的Binlog里提取日志信息,传递给回放端,回放端并行回放日志。一个DTS集群可以管理多套的数据库服务,界面设计如下:

8.未来规划
1)支持更丰富的开源数据库
根据用户的需求支持更多类型的数据库服务。
2)容器化
探索适合数据库的容器化管理方式
3)混合云
公有云+私有云
在一个中心统一管理私有云和公有云的数据库服务。

责任编辑: