详解MySQL索引与底层原理
文章目录
- 索引的底层原理
-
- 一、MySQL缓冲池
-
- 1、数据页与数据页管理
- 2、free链表
- 3、flush链表
- 4、哈希表
- 5、LRU链表
- 补充
- 二、索引的底层原理
-
- 1、InnoDB索引
-
- I. 行记录与页内索引
- II. 页外索引页
- III. B+树结构
- IV. 聚簇索引
- V. InnoDB索引文件
- 2、MyISAM索引
-
- I. 聚簇索引 VS 非聚簇索引
- II. MyISAM索引文件
- 三、页分裂与页合并
-
- 1、页分裂
- 2、页合并
- 四、B+树的优势
-
- 为什么索引不采取其它数据结构
-
- 1、AVL树/红黑树
- 2、哈希表
- 3、跳表
- 4、B树(B-树)
- 五、索引操作
-
- 1、创建索引
-
- 默认主键
- 2、删除索引
- 3、查看索引
-
- I. 索引覆盖
- II. EXPLAIN语句
- 4、全文索引
- 5、复合索引
-
- 最左匹配原则
- 六、索引综合分析
-
- 1、优点
- 2、缺点
- 3、索引的创建原则
索引的底层原理
一、MySQL缓冲池
在探究索引原理之前,需要先了解缓冲池(Buffer Pool)的相关概念。
1、数据页与数据页管理
MySQL数据库本质上就是Linux下的一个目录。而所谓的表,就是对应目录下的多个文件,它们都是存储在磁盘中的。
Linux下内存与磁盘文件的交互以4KB/页进行。而MySQL为了提高I/O效率,也将数据进行分页存储,且一个数据页的大小为16KB,在MySQL下可以通过SHOW GLOBAL STATUS LIKE 'INNODB_PAGE_SIZE'查询。

数据页的基础结构为:
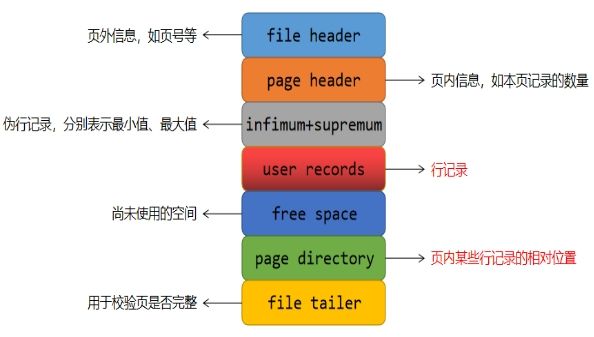
MySQL向系统申请一片连续的内存空间作为缓冲池,默认为128MB,可以通过SHOW VARIABLES LIKE 'INNODB_BUFFER_POOL_SIZE'查看。
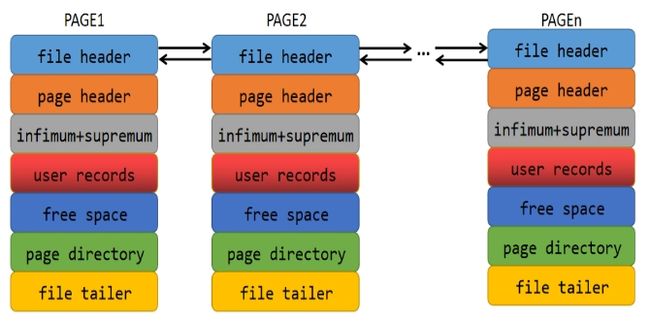
创建数据页会向该缓冲池申请16KB的空间,同时MySQL以双向链表的形式将数据页管理起来:
2、free链表
MySQL以双链表的形式维护当前处于空闲状态的数据页,该链表称为free链表。
3、flush链表
实际上,对表数据进行增删改时,优先修改的是该数据所在数据页的内容,此时被修改的页被称为"脏页面",它们会被添加到flush链表中,适时地被刷新到磁盘上。
4、哈希表
记录当前有哪些表的哪些页被缓存到缓冲池中。
5、LRU链表
记录常用页(热数据)和不常用页(冷数据)。当缓冲池的数据页不够用时,需要将不常用的页面刷新到磁盘,同时用新数据覆盖它。
补充
除了上面所说的数据页,MySQL中还有其它的页类型,比如:undo日志页、溢出页等。
溢出页:当行记录占用内存较大时,该记录需要一个甚至多个单独的页来存储,这样的页称为溢出页
二、索引的底层原理
索引是存储引擎级别的概念,不同存储引擎拥有不同的索引方式,这里主要讨论
InnoDB和MyISAM存储引擎,它们都是基于B+树实现索引。
1、InnoDB索引
I. 行记录与页内索引
数据页内的行记录(即表数据user rocords)按照单向链表的形式被组织起来,根据索引键的值进行升序排序(这里为1、2、3…)。

同时,为了加快链表的遍历,数据页将链表数据进行分组,每组4~8个链表节点,并在page director中保存了每一组中键值最大的链表节点的页内地址偏移量,它们被称为"槽(Slot)",占用2个字节:
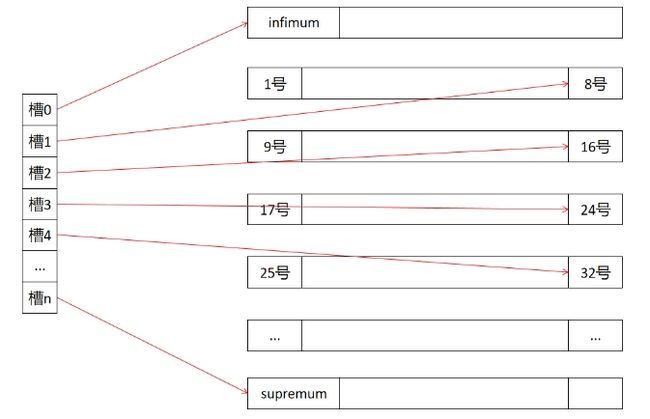
槽0~n构成一个页内目录(或称页内索引),这样链表就不需要单纯地线性遍历,而是可以通过二分法查找目录,以更快地跳转至离目标数据最近的位置。
如此一来,既可以发挥链表范围查找的优势,又能加快链表节点的索引,从而提高在链表中查找的效率!
II. 页外索引页
当表数据量较大时,数据页的数量也会增加。因此光有页内目录是不够的,还需要一种页面专门存储"键与页号"的映射关系,这样的页称为(页外)索引页。
索引页也是一个16KB的数据页,但是不存储有效的表数据,仅在page directory中存储目录结构,它的键是对应页中键值的最小值:

有了索引页后,就可以通过二分查找更快地定位到数据所在的数据页了。
索引页的页内数据也按照键值升序排序,相邻两个索引页的键值满足升序关系。
III. B+树结构
当数据量更大时,可能会有多个索引页。因此,为了更快地定位索引页,可以建立更高一级索引页,最终便会形成以下结构(图中仅画了3层,但实际上3~4层即可支持千万甚至亿级别的数据):
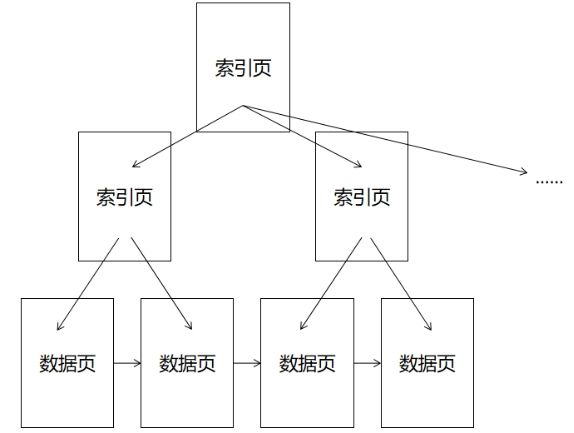
通过对上级索引页二分查找,来索引到下一级索引页,再通过二分查找,来索引到对应的数据页。
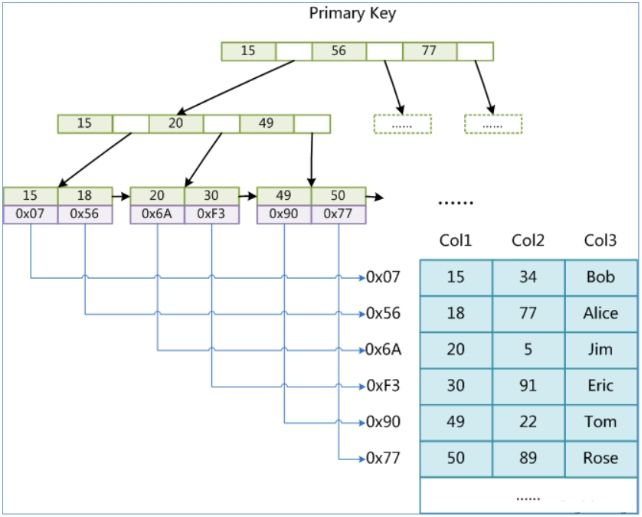
这样的树形索引结构就是“B+树”,其中叶子结点(数据页)存储有效的表数据,且通过链表连接在一起,其它所有非叶子节点(索引页)存储索引数据。
IV. 聚簇索引
InnoDB这种叶子结点直接存储有效行记录的结构称为"聚簇索引",即索引和数据聚合在一起。
但是,如果给表的多个字段建立索引,那么每一颗索引B+树都会有一份数据,这无疑是很大的内存浪费。
因此规定:
1、对于表中的主键索引:叶子结点存储有效数据。
2、对于表中的辅助索引(非主键索引/二级索引):叶子结点存储对应行记录的主键值。当按照非主键索引查询时,先索引到主键值,然后再拿着主键去索引有效数据,该过程称为"回表查询"。这也意味着,对于辅助索引,需要两次查询。
V. InnoDB索引文件
![]()
- .frm文件存储表结构(Frame)
- .ibd文件存储索引结构,其中包含表数据
注:通过
SHOW VARIABLES LIKE 'DATADIR'即可查看数据存储路径,一般都在/var/lib/mysql下。
2、MyISAM索引
MyISAM的索引与InnoDB几乎相同,但是其B+树的叶子结点存储的是有效数据的地址。这意味着,不管是主键索引还是辅助索引,索引与数据是分离的,这种存储结构称为"非聚簇索引"。
I. 聚簇索引 VS 非聚簇索引
1、就主键索引而言,聚簇索引的数据和索引都在一棵B+树上,可以直接获得数据;非聚簇索引则需要通过指针进行二次查找;
2、就辅助索引而言,聚簇索引需要查询两棵B+树才能获得数据(回表查询),此外,如果回表查询的主键值并不连续,甚至非常分散,那么回表时可能需要将多个数据页载入内存,因此效率较低。正因如此,MySQL查询优化器在数据量比较大时甚至会选择扫描全表的方式,而非使用辅助索引进行回表查询;而非聚簇索引同样需要二次查找,但由于第二次查找是直接利用指针定位数据,因此速度更快。
II. MyISAM索引文件

- .frm文件存储表结构(Frame)
- .MYD文件存储表数据(Data)
- .MYI文件存储表索引(Index)
三、页分裂与页合并
1、页分裂
一个数据页内的记录是按升序链表组织的,但是当一个数据页装不下所有数据时,MySQL就要建立多个页来存储这些数据。同样的,对于相邻的两个页PAGE1和PAGE2,必须满足:PAGE2中的所有数据大于PAGE1中的所有数据(比较的是键值)。
比如,向PAGE1中插入一个新值6,但是PAGE1满了,就需要新建一个PAGE2并将6插入其中,但是此时就无法满足上述条件了:
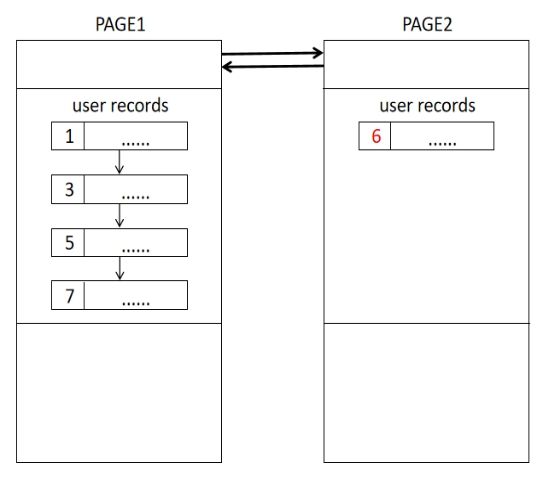
因此,必须将PAGE2中的6与PAGE1中的7进行交换:
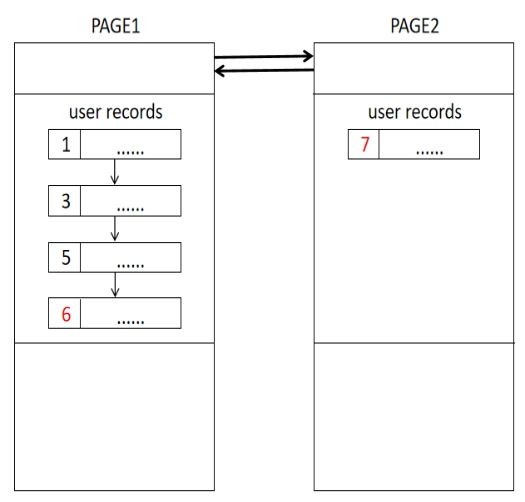
上述创建新页并进行数据交换的过程称为“页分裂”。
此外,在进行必要的数据交换时,可能还伴随着将原数据页中的部分数据转移到新数据页中。
在对表进行增删改时,很可能会导致相邻数据页不满足数据升序的条件,因此页需要进行必要的数据交换,这也意味着为了加快查找建立的索引实际上牺牲了增删改的效率。
2、页合并
对表记录的删除操作并非真正的删除,而是将对应记录标记为“已删除”,其空间可以被新记录使用。
当删除记录达到阈值MERGE_THRESHOLD(默认页体积的50%)时,InnoDB会向前或向后寻找合适的页,将两个页的数据合并成一页。
四、B+树的优势

-
非叶子节点只存储索引,这意味着只需要较少的页即可构建整棵B+树的上层索引节点,因此树的高度较低,一般为2~4层,且根索引页常驻内存,因此查询叶子结点数据最多只需要1~3次的I/O操作。
-
目录和数据被存放在固定大小的页中,有利于按需将页从磁盘加载至内存,不会导致一张表占用大量内存的情况。
-
叶子结点只存储数据和页内索引,且数据是顺序存储的,所有的叶子结点通过链表连接在一起,有利于范围查找。
-
数据被单独存放在页中,因此能够有效发挥局部性原理的优势。
为什么索引不采取其它数据结构
以较为高效的几种数据结构为例:
1、AVL树/红黑树
平衡二叉树的优势在于查找复杂度为O(logN),但是相较于B+树,平衡二叉树一个节点对应一个键值,也就只能存储一个数据,这也导致当数据量非常大时,整棵树就会很高。
如果目标数据存储在较底层,那么由于一个节点只有一个数据,不同节点可能会分散在不同的数据页中,因此加载这些节点很可能会占据大量的内存空间,且磁盘的I/O次数会增加,使MySQL的效率大打折扣。
2、哈希表
哈希表通过键值存储,使查找复杂度提升至O(1),但是问题在于:哈希表存储数据是无序的,不支持排序和范围查找;且键值需要通过行数据计算,不支持模糊匹配;此外,数据量较大时,哈希冲突会严重影响MySQL的性能。
注:MySQL中只有Memory存储引擎支持哈希索引。
3、跳表
跳表与B+树类似,都是基于目录来实现logn的查询效率,但是问题在于:跳表的每个节点只能存储一个数据,且整体高度相比B+树高很多,因此跳表的I/O效率过低!
4、B树(B-树)
B树与B+树最大的区别在于:其不管是叶子结点还是树内节点,都混合存储了索引和数据。

相比于B+树,B树的劣势在于:
-
大量的数据被分散在各层节点中,导致每个节点能存储的索引数量有限,因此B树整体较高,从而导致I/O效率的下降;
-
B树的数据分散存储,因此在B树中范围查找只能通过递归遍历树的方式,没有B+树的效率高,且局部性原理的优势不显著;
五、索引操作
1、创建索引
ALTER TABLE tb_name ADD INDEX [index_name] (COLUMN1[, ...])
或
CREATE INDEX index_name ON table_name(COLUMN)
或在创建表时指定索引:
CREATE TABLE tb_name (....., INDEX index_name(COLUMN))
index_name可以用来为该索引取名,建议以idx_为前缀,加上列名作为索引名。如果省略index_name,则默认以列名作为索引名。
默认主键
MySQL会自动为主键和唯一键建立索引,其中所有的非主键索引都称为普通索引(辅助索引),它们的B+树叶子结点存储的是行记录的主键值。
如果表没有设定主键或者非空唯一键,就会自动生成一个6字节的默认主键(用户不可见)。
2、删除索引
普通索引根据索引名删除:
ALTER TABLE tb_name DROP INDEX INDEX_NAME
或
DROP INDEX index_name ON tb_name
删除主键索引只能通过删除主键完成:
ALTER TABLE tb_name DROP PRIMARY KEY
3、查看索引
查看对应表有哪些索引:
SHOW INDEX FROM tb_name [\G]

I. 索引覆盖
对于使用辅助索引的查询语句,如果索引的键值覆盖了需要查询的字段,那么此时不需要回表查询。
比如表t为c1建立辅助索引,那么对于SQL:select c1 from t where c1 > 10
由于索引树中存储了c1作为键,因此只需要扫描c1>10的链表节点,同时取出c1的值即可,而不是拿着节点存储的主键值回表查询完整的行记录,再从行记录中取出c1,这样效率太低了,而且完全没必要。
上述过程称为索引覆盖。
II. EXPLAIN语句
explain + SQL语句可以查看MySQL的查询优化器对该SQL语句进行优化后生成的执行计划。用户可以在该计划的辅助下,针对性地改进查询语句。
explain包含以下字段:
- id
查询语句一般包含一个或多个SELECT关键字,MySQL为每一个SELECT都分配了一个唯一的id来标识它们,例如:

- select_type
每个SELECT语句在整体查询语句中扮演的“角色”,比如:
-
SIMPLE:不包含UNION或子查询的简单查询;
-
PRIMARY:包含UNION或子查询的SELECT语句中的主查询;
-
SUBQUERY:包含子查询的SELECT语句中的子查询;
-
UNION:union语句中最左边的select为主查询,其余查询都是union类型。
- table
对应SELECT查询的表名。
- type
该SQL语句的查询方法,包括但不仅有:
-
const:主键或唯一键索引与常数进行等值匹配(如id=1就是一个等值匹配)
-
ref:非主键或唯一键索引与常数进行等值匹配
-
index:扫描索引的叶子节点中的数据,如果是辅助索引,则可能需要回表查询。由于需要遍历,没有利用索引的特性,因此该方法意味着**“索引无效”**。
-
all:不依赖索引的全表扫描
上述查询方法从上至下效率递减。
- possible_keys
该SQL语句可能使用到的索引名。
- key
经查询优化器优化后,该SQL语句实际使用的索引名。
- key_len
根据key对应的列最多占用的空间大小计算,比如INT为4,utf8字符集下varchar(10)占用30字节。此外,还有两种额外情况:
-
如果该列可以存储NULL值,则加1
-
如果该列是变长类型,则再加2
- ref
与索引列进行等值匹配的数据的类型(常数const、表的某一列等)。
- rows
预计本次查询需要读取的记录行数。
- extra
其它文本类信息,如:using temporary表示查询时可能会建立临时表进行去重、排序等。
4、全文索引
全文索引用于文本关键字匹配,与搜索引擎的底层原理相关。在处理大数据时,全文索引的文本匹配速度比普通的模糊匹配’like %'速度更快。
在MySQL5.6之前,只有MyISAM支持全文索引,5.6之后,InnoDB和MyISAM都支持全文索引。但是MySQL的全文索引仅支持英文,如果对中文进行全文检索,可以使用 sphinx的中文版(coreseek)。
1、创建全文索引
CREATE TABLE tb_name (...., FULLTEXT(COLUMN[,...]))
或
CREATE FULLTEXT INDEX index_name ON tb_name (COLUMN[, ...])
注:全文索引仅支持字符串类型数据(varchar、char、text)
2、删除全文索引
DROP INDEX index_name ON tb_name
与其它索引的删除方法相同。
3、使用全文索引
SELECT ... FROM tb_name WHERE MATCH(COLUMN) AGAINST('???')
match后跟的是创建全文索引的列名,against后跟的是查找的关键字。
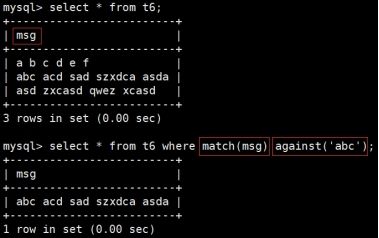
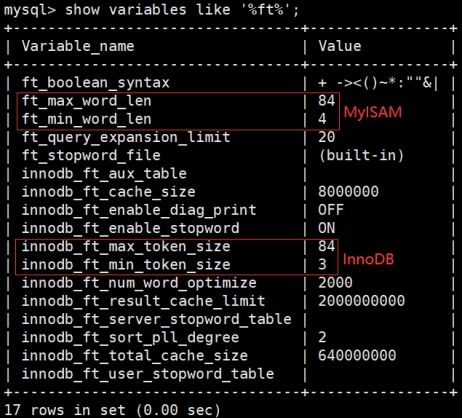
当查找关键字较短时,会出现查询不到的情况,这是因为mysql下设置了最小搜索长度,可以通过show variables like '%ft%'查看:
5、复合索引
以两个及以上的列的键值建立的索引称为复合索引。
1、创建复合索引
CREATE INDEX index_name ON tb_name (COLUMN1, COLUMN2[, ...])
2、删除复合索引
DROP INDEX index_name ON tb_name
最左匹配原则
假设创建了三个列的复合索引(c1,c2,c3),那么B+索引树中的数据是以最左侧的c1列为基准进行排序的,对于c1列相同的数据,则以c2列为基准进行排序,c2列相同则以c3列为基准进行排序。
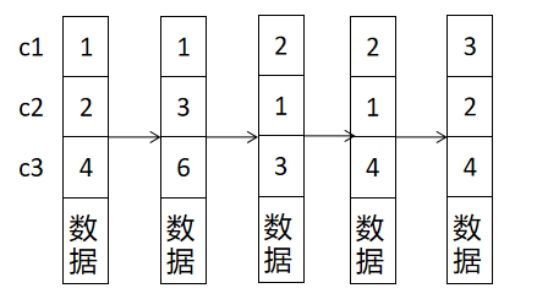
简而言之:复合索引树中的数据仅对(c1,c2,c3)中最左侧的c1列有序,而对于c2、c3列是无序的。
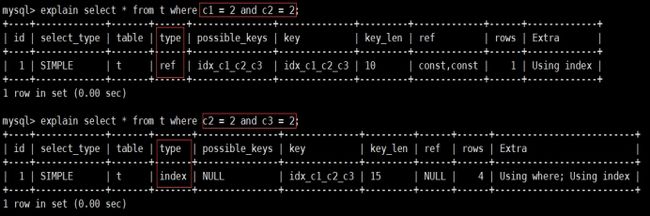
那么只有以c1为条件之一的查询语句才能有效利用复合索引提升查询效率,比如:
-
查询一使用c1作为查询条件之一,因此type为ref,即使用了索引提高效率;
-
查询二并没有c1作为查询条件,因此type为index,表示该查询在联合索引建立的索引树中进行全表数据扫描,即没有使用索引提高效率。
但是,如果是下面这种情况:

虽然有c1作为查询条件之一,但是type依然为index,这是因为c1=2的数据可以使用索引查询,但是由于c2在表中是乱序排列的,因此c2=2的数据需要扫描索引树的全部数据进行查询。
正是由于复合索引的最左匹配原则,因此查询最频繁的字段应当作为复合索引的最左字段。
六、索引综合分析
1、优点
-
加快了检索速度。
-
避免了索引列的排序,因为索引数据是已经根据索引键排序好的。
2、缺点
-
时间代价:数据的增删改都需要动态修改B+树索引,因而性能会下降。此外,MySQL在执行查询语句前会先生成一个查询计划,分析使用不同索引所需的成本。如果建立了太多的索引,就会导致分析耗时过多,从而影响查询效率。
-
空间代价:数据量较大时, 索引也会占据较大的物理空间。
3、索引的创建原则
-
频繁用来查询、排序、分组的字段应当添加索引。
-
必须是具有唯一性或重复数据较少的字段(例如性别’男’'女’就不应该设为索引)。
-
更新较为频繁的字段不应该作为索引,因为修改索引会消耗一定的时间。
-
索引列占用的内存应当尽量小,比如能用INT就不要用BIGINT,这样一个数据页可以存放更多数据,从而减少磁盘I/O。