mysql 层_Mysql——深入浅出InnoDB底层原理

存储引擎
很多文章都是直接开始介绍有哪些存储引擎,并没有去介绍存储引擎本身。那么究竟什么是存储引擎?不知道大家有没有想过,MySQL是如何存储我们丢进去的数据的?
其实存储引擎也很简单,我认为就是一种存储解决方案,实现了新增数据、更新数据和建立索引等等功能。
有哪些已有的存储引擎可以让我们选择呢?
InnoDB、MyISAM、Memory、CSV、Archive、Blackhole、Merge、Federated、Example
种类很多,但是常用的存储引擎目前就只有InnoDB和MyISAM,我也会着重来介绍这两种存储引擎。
InnoDB是目前使用最广的MySQL存储引擎,MySQL从5.5版本开始InnoDB就已经是默认的存储引擎了。那你知道为什么InnoDB被广泛的使用呢?先把这个问题放一放,我们先来了解一下InnoDB存储引擎的底层原理。
InnoDB的内存架构主要分为三大块,缓冲池(Buffer Pool)、重做缓冲池(Redo Log Buffer)和额外内存池
缓冲池
InnoDB为了做数据的持久化,会将数据存储到磁盘上。但是面对大量的请求时,CPU的处理速度和磁盘的IO速度之间差距太大,为了提高整体的效率, InnoDB引入了缓冲池。
当有请求来查询数据时,如果缓存池中没有,就会去磁盘中查找,将匹配到的数据放入缓存池中。同样的,如果有请求来修改数据,MySQL并不会直接去修改磁盘,而是会修改已经在缓冲池的页中的数据,然后再将数据刷回磁盘,这就是缓冲池的作用,加速度,加速写,减少与磁盘的IO交互。
缓冲池说白了就是把磁盘中的数据丢到内存,那既然是内存就会存在没有内存空间可以分配的情况。所以缓冲池采用了LRU算法,在缓冲池中没有空闲的页时,来进行页的淘汰。但是采用这种算法会带来一个问题叫做缓冲池污染。
当你在进行批量扫描甚至全表扫描时,可能会将缓冲池中的热点页全部替换出去。这样一来可能会导致MySQL的性能断崖式下降。所以InnoDB对LRU做了一些优化,规避了这个问题。
MySQL采用日志先行,在真正写数据之前,会首先记录一个日志,叫Redo Log,会定期的使用CheckPoint技术将新的Redo Log刷入磁盘,这个后面会讲。
除了数据之外,里面还存储了索引页、Undo页、插入缓冲、自适应哈希索引、InnoDB锁信息和数据字典。下面选几个比较重要的来简单聊一聊。
插入缓冲
插入缓冲针对的操作是更新或者插入,我们考虑最坏的情况,那就是需要更新的数据都不在缓冲池中。那么此时会有下面两种方案。
来一条数据就直接写入磁盘
等数据达到某个阈值(例如50条)才批量的写入磁盘
很明显,第二种方案要好一点,减少了与磁盘IO的交互。
两次写
鉴于都聊到了插入缓冲,我就不得不需要提一嘴两次写,因为我认为这两个InnoDB的特性是相辅相成的。
插入缓冲提高了MySQL的性能,而两次写则在此基础上提高了数据的可靠性。我们知道,当数据还在缓冲池中的时候,当机器宕机了,发生了写失效,有Redo Log来进行恢复。但是如果是在从缓冲池中将数据刷回磁盘的时候宕机了呢?
这种情况叫做部分写失效,此时重做日志就无法解决问题。
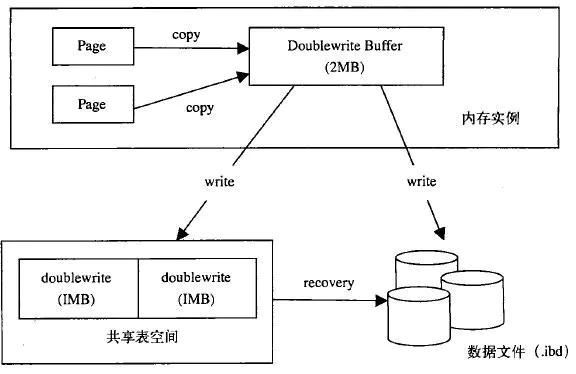
图片来源于网络, 侵删
在刷网页时,并不是直接刷入磁盘,而是copy到内存中的Doublewrite Buffer中,然后再拷贝至磁盘共享表空间(你可以就理解为磁盘)中,每次写入1M,等copy完成后,再将Doublewrite Buffer中的页写入磁盘文件。
有了两次写机制,即使在刷脏页时宕机了,在实例恢复的时候也可以从共享表空间中找到Doublewrite Buffer的页副本,直接将其覆盖原来的数据页即可。
自适应哈希索引
自适应索引就跟JVM在运行过程中,会动态的把某些热点代码编译成Machine Code一样,InnoDB会监控对所有索引的查询,对热点访问的页建立哈希索引,以此来提升访问速度。
你可能多次看到了一个关键字页,接下来那我们就来聊一下页是什么?
页
页,是InnoDB中数据管理的最小单位。当我们查询数据时,其是以页为单位,将磁盘中的数据加载到缓冲池中的。同理,更新数据也是以页为单位,将我们对数据的修改刷回磁盘。每页的默认大小为16k,每页中包含了若干行的数据,页的结构如下图所示。
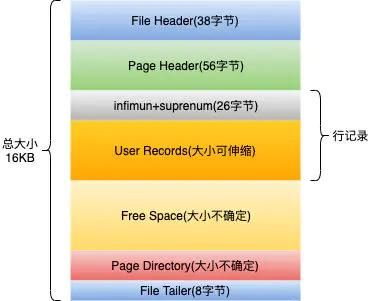
图片来源于网络, 侵删
不用太纠结每个区是干嘛的,我们只需要知道这样设计的好处在哪儿。每一页的数据,可以通过FileHeader中的上一页和下一页的数据,页与页之间可以形成双向链表。因为在实际的物理存储上,数据并不是连续存储的。你可以把它理解成G1的Region在内存中的分布。
而一页中所包含的行数据,行与行之间则形成了单向链表。我们存入的行数据最终会到User Records中,当然最初User Records并不占据任何存储空间。随着我们存入的数据越来越多,User Records会越来越大,Free Space的空间会越来越小,直到被占用完,就会申请新的数据页。
User Records中的数据,是按照主键id来进行排序的,当我们按照主键来进行查找时,会沿着这个单向链表一直往后找,
重做日志缓冲
上面聊过,InnoDB中缓冲池中的页数据更新会先于磁盘数据更新的,InnoDB也会采用日志先行(Write Ahead Log)策略来刷新数据,什么意思呢?当事务开始时,会先记录Redo Log到Redo Log Buffer中,然后再更新缓冲池页数据。
Redo Log Buffer中的数据会按照一定的频率写到重做日志中去。被更改过的页就会被标记成脏页,InnoDB会根据CheckPoint机制来将脏页刷到磁盘。
日志
上面提到了Redo log,这一小节就专门来讲一讲日志,日志分为如下两个维度。
MySQL层面
InnoDB层面
MySQL日志
MySQL的日志可以分为错误日志、二进制文件、查询日志和满查询日志。
错误日志 很好理解,就是服务运行过程中发生的严重错误日志。当我们的数据库无法启动时,就可以来这里看看具体不能启动的原因是什么
二进制文件 它有另外一个名字你应该熟悉,叫Binlog,其记录了对数据库所有的更改。
查询日志 记录了来自客户端的所有语句
慢查询日志 这里记录了所有响应时间超过阈值的SQL语句,这个阈值我们可以自己设置,参数为long_query_time,其默认值为10s,且默认是关闭的状态,需要手动的打开。
InnoDB日志
InnoDB日志就只有两种,Redo Log和Undo Log,
Redo Log 重做日志,用于记录事务操作的变化,且记录的是修改之后的值。不管事务是否提交都会记录下来。例如在更新数据时,会先将更新的记录写到Redo Log中,再更新缓存中页中的数据。然后按照设置的更新策略,将内存中的数据刷回磁盘。
Undo Log 记录的是记录的事务开始之前的一个版本,可用于事务失败之后发生的回滚。
Redo Log记录的是具体某个数据页上的修改,只能在当前Server使用,而Binlog可以理解为可以给其他类型的存储引擎使用。这也是Binlog的一个重要作用,那就是主从复制,另外一个作用是数据恢复。
上面提到过,Binlog中记录了所有对数据库的修改,其记录日志有三种格式。分别是Statement、Row和MixedLevel。
Statement 记录所有会修改数据的SQL,其只会记录SQL,并不需要记录下这个SQL影响的所有行,减少了日志量,提高了性能。但是由于只是记录执行语句,不能保证在Slave节点上能够正确执行,所以还需要额外的记录一些上下文信息
Row 只保存被修改的记录,与Statement只记录执行SQL来比较,Row会产生大量的日志。但是Row不用记录上下文信息了,只需要关注被改成啥样就行。
MixedLevel 就是Statement和Row混合使用。
具体使用哪种日志,需要根据实际情况来决定。例如一条UPDATE语句更新了很多的数据,采用Statement会更加节省空间,但是相对的,Row会更加的可靠。
InnoDB和MyISAM的区别
由于MyISAM并不常用,我也不打算去深究其底层的一些原理和实现。我们在这里简单的对比一下这两个存储引擎的区别就好。我们分点来一点点描述。
事务 InnoDB支持事务、回滚、事务安全和崩溃恢复。而MyISAM不支持,但查询的速度要比InnoDB更快
主播 InnoDB规定,如果没有设置主键,就自动的生成一个6字节的主键,而MyISAM允许没有任何索引和主键的存在,索引就是行的地址
外键 InnoDB支持外键,而MyISAM不支持
表锁 InnoDB支持行锁和表锁,而MyISAM只支持表锁
全文索引 InnoDB不支持全文索引,但是可以用插件来实现相应的功能,而MyISAM是本身就支持全本索引
行数 InnoDB获取行数时,需要扫全表。而MyISAM保存了当前表的总行数,直接读取即可。
所以,简单总结一下,MyISAM只适用于查询大于更新的场景,如果你的系统查询的情况占绝大多数(例如报表系统)就可以使用MyISAM来存储,除此之外,都建议使用InnoDB。
End
由于时间的原因,本文只是简单的聊了聊InnoDB的整体架构,并没有很深入的去聊某些点。例如InnoDB是如何改进来解决缓冲池污染的,其算法具体是什么,checkpoint是如何工作的等等,只是做一个简单的了解,之后如果有时间的话再细聊。
本文地址:https://blog.csdn.net/weixin_48182198/article/details/107662593
希望与广大网友互动??
点此进行留言吧!