【实战项目之个人博客】
目录
项目背景
项目技术栈
项目介绍
项目亮点
项目启动
1.创建SSM(省略)
2.配置项目信息
3.将前端页面加入到项目中
4.初始化数据库
5.创建标准分层的目录
6.创建和编写项目中的公共代码以及常用配置
7.创建和编写业务的Entity、Mapper、Service、Controller等基础代码
8.按照页面,从前端或者后端开始实现相应的交互和业务代码
项目功能实现
实现用户注册功能
实现用户登录功能
实现添加文章功能
实现文章编辑功能
实现注销功能
实现文章内容详情页功能
实现增加阅读量功能
实现判断当前用户登录状态功能
实现用户的博客列表功能
实现文章删除功能
实现统一异常处理功能
实现统一数据格式返回
实现主页博客展示和分页功能
实现密码加盐(增强密码安全性)功能
实现验证码功能
实现将Session存储的用户信息持久化到Redis功能
项目背景
本项目是我个人为了提升技术能力和积累实战经验,搭建的一个个人博客系统。通过这个项目,将学习并实践Web开发、前端设计、后端编程等技能,同时记录和分享我在学习和实践中的心得体会。
项目技术栈
SpringBoot+SpringWeb+Mybatis+MySQL+Redis
项目介绍
基于SSM的前后端分离的个人博客系统,项目中融入了Editor开源组件,更方便用户对博文的编写,大概包含以下功能:用户的登录与注册、个人博客列表及其所有人博客展示,用户对个人博文的增加、删除、修改、查询,博客列表的分页管理等。
项目亮点
1.注册用户时候,对用户密码进行加盐加密处理,登录用户时候,对密码进行加盐解密处理,从而提高用户信息安全性。
2.将用户信息存入session,实现内存到redis的持久化,支持分布式处理。
3.通过拦截器的方式进行登录验证,减轻代码冗余,提高重用率。
项目启动
1.创建SSM(省略)
2.配置项目信息
application.properties
# 配置数据库的连接字符串
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/myblog?characterEncoding=utf8&useSSL=false
username: root
password: 111111
driver-class-name: com.mysql.cj.jdbc.Driver
# 设置 Mybatis 的 xml 保存路径
mybatis:
mapper-locations: classpath:mybatis/*Mapper.xml # 映射文件包扫描
type-aliases-package: com.example.demo.entity # 实体类别名包扫描
configuration: # 配置打印 MyBatis 执行的 SQL
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #默认日志级别是info,而这需要的日志级别是debug
# 配置打印 MyBatis 执行的 SQL
logging:
level:
com:
example:
demo: debug #默认info > debug,只有设置为debug才能看到日志
3.将前端页面加入到项目中
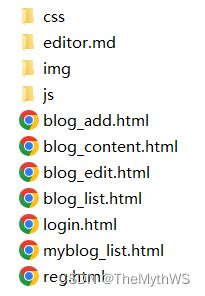
4.初始化数据库
-- 创建数据库
drop database if exists myblog;
create database myblog DEFAULT CHARACTER SET utf8mb4;
-- 使用数据数据
use myblog;
-- 创建表[用户表]
drop table if exists userinfo;
create table userinfo(
id int primary key auto_increment,
username varchar(100) not null,
password varchar(65) not null,
photo varchar(500) default '',
createtime timestamp default current_timestamp,
updatetime timestamp default current_timestamp,
`state` int default 1
) default charset 'utf8mb4';
-- 创建文章表
drop table if exists articleinfo;
create table articleinfo(
id int primary key auto_increment,
title varchar(100) not null,
content text not null,
createtime timestamp default current_timestamp,
updatetime timestamp default current_timestamp,
uid int not null,
rcount int not null default 1,
`state` int default 1
)default charset 'utf8mb4';
-- 创建视频表
drop table if exists videoinfo;
create table videoinfo(
vid int primary key,
`title` varchar(250),
`url` varchar(1000),
createtime timestamp default current_timestamp,
updatetime timestamp default current_timestamp,
uid int
)default charset 'utf8mb4';
-- 添加一个用户信息
INSERT INTO `myblog`.`userinfo` (`id`, `username`, `password`, `photo`, `createtime`, `updatetime`, `state`) VALUES
(1, 'admin', 'admin', '', '2022-5-20 14:28:57', '2022-5-20 13:14:52', 1);
INSERT INTO `myblog`.`userinfo` (`id`, `username`, `password`, `photo`, `createtime`, `updatetime`, `state`) VALUES
(2, 'themyth', '1234', '', '2022-8-18 14:28:57', '2022-8-18 13:14:52', 1);
-- 文章添加测试数据
insert into articleinfo(title,content,uid)
values('Java','Java正文',1);
-- 添加视频
insert into videoinfo(vid,title,url,uid) values(1,'java title','http://www.google.com',1);
5.创建标准分层的目录
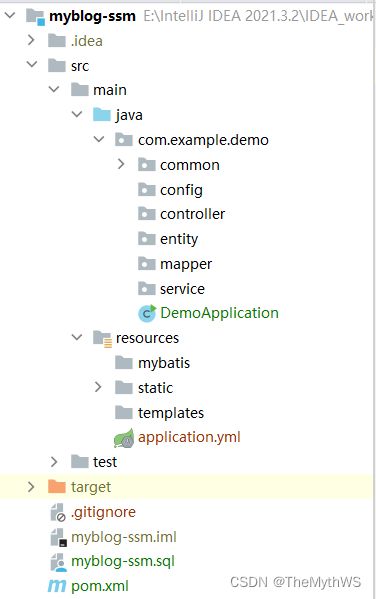
ps:真实项目service下面还有个子包impl,里面存放service的实现类。因为本项目比较简单,所以就没有完全标准型的分层。
6.创建和编写项目中的公共代码以及常用配置
定义统一格式返回对象:
/**
* 最终版的 JSON 统⼀返回对象
*/
@Data
public class AjaxResult implements Serializable {
private Integer code;
private String msg;
private Object data;
/**
* 返回成功数据
* @param data
* @return
*/
public static AjaxResult success(Object data) {
AjaxResult ajaxObject = new AjaxResult();
ajaxObject.setCode(200);
ajaxObject.setMsg("");
ajaxObject.setData(data);
return ajaxObject;
}
public static AjaxResult success(Object data, String msg) {
AjaxResult ajaxObject = new AjaxResult();
ajaxObject.setCode(200);
ajaxObject.setMsg(msg);
ajaxObject.setData(data);
return ajaxObject;
}
/**
* 返回失败数据
* @param code
* @param msg
* @return
*/
public static AjaxResult fail(Integer code, String msg) {
AjaxResult ajaxObject = new AjaxResult();
ajaxObject.setCode(code);
ajaxObject.setMsg(msg);
ajaxObject.setData("");
return ajaxObject;
}
public static AjaxResult fail(Integer code, String msg, Object data) {
AjaxResult ajaxObject = new AjaxResult();
ajaxObject.setCode(code);
ajaxObject.setMsg(msg);
ajaxObject.setData(data);
return ajaxObject;
}
}7.创建和编写业务的Entity、Mapper、Service、Controller等基础代码
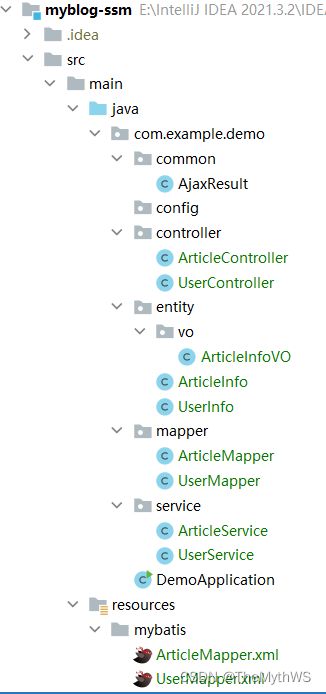
8.按照页面,从前端或者后端开始实现相应的交互和业务代码
项目功能实现
实现用户注册功能
前端核心代码
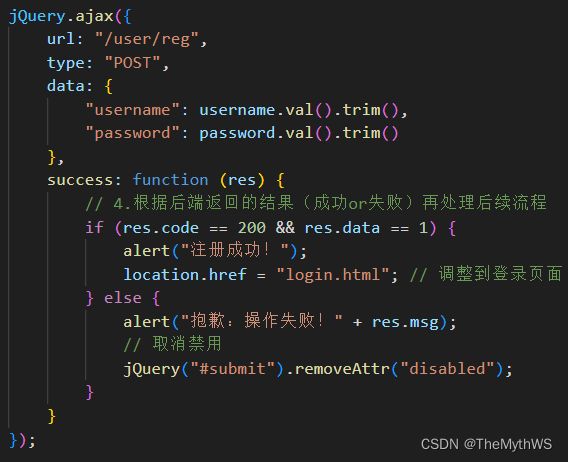
写后端接口
先写controller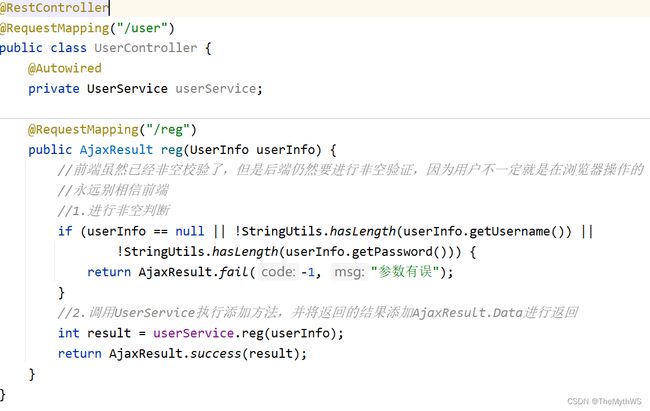
写service

写mapper
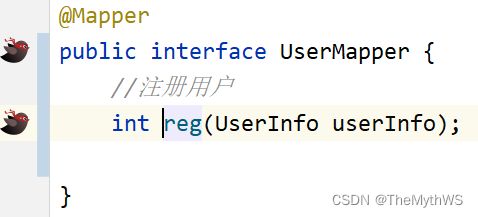
对应的xml
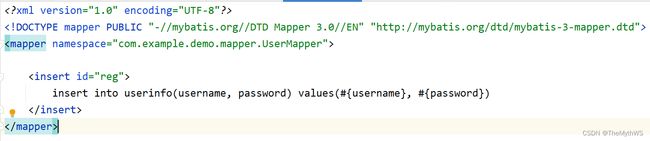
ps:也可以从mapper写起,看个人习惯。
接下来就是测试:
假如出问题了如何解决,排除法:先看前端有无问题,可以利用js打断点调试,如果没有问题就是后端的问题,再进行debug调试。缩小问题,定位问题,解决问题。
前端的调试方式:
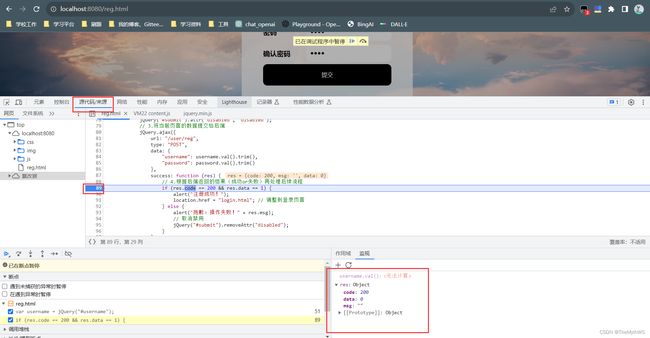
实现用户登录功能
前端核心代码
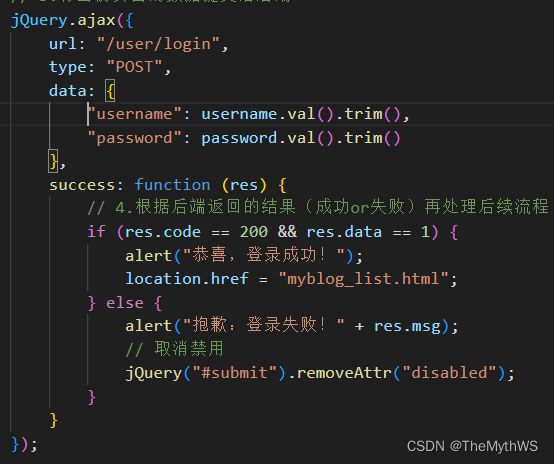
写后端接口
mapper
xml

service
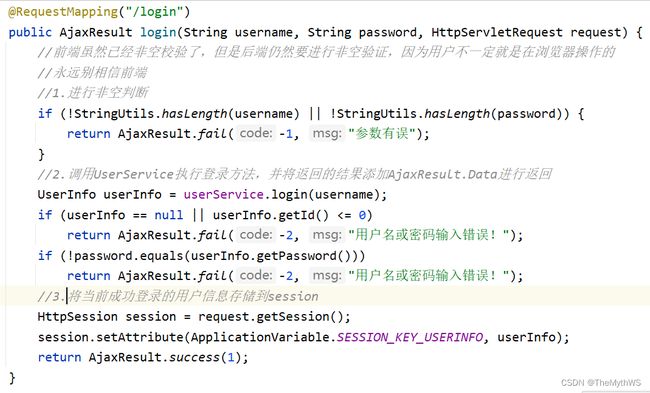
controller
拦截器
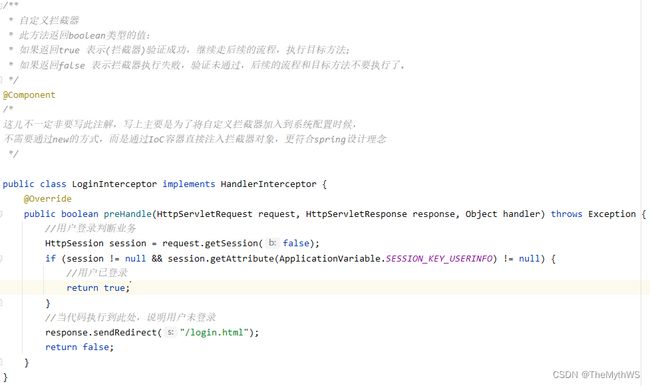
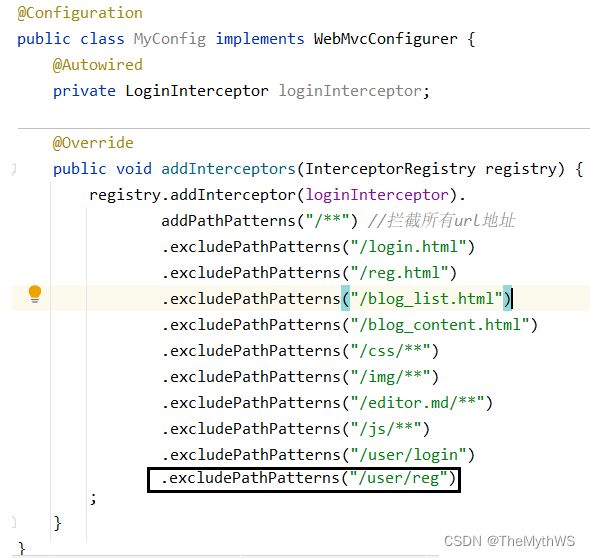
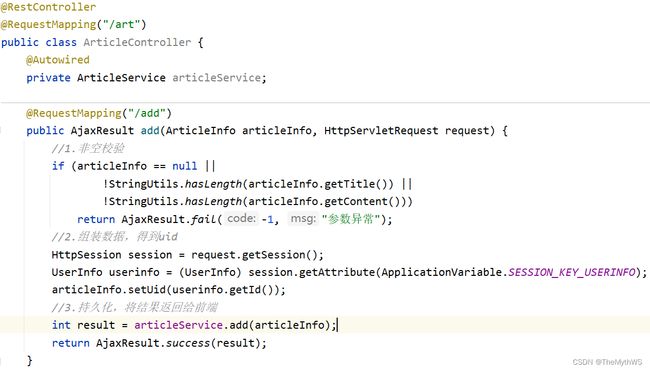
实现添加文章功能
前端核心代码
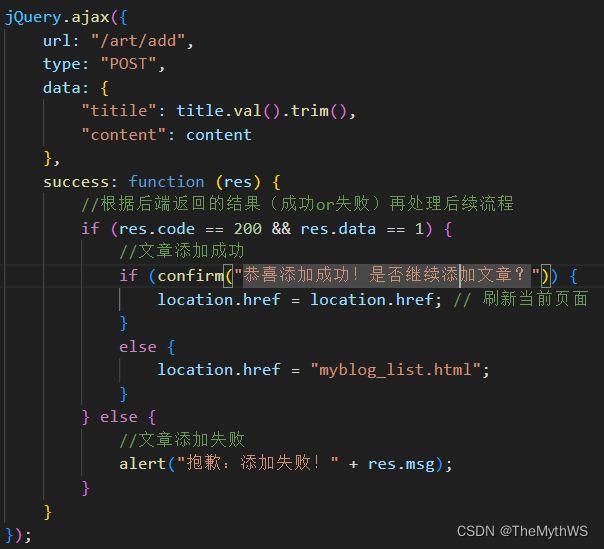
mapper

xml

service
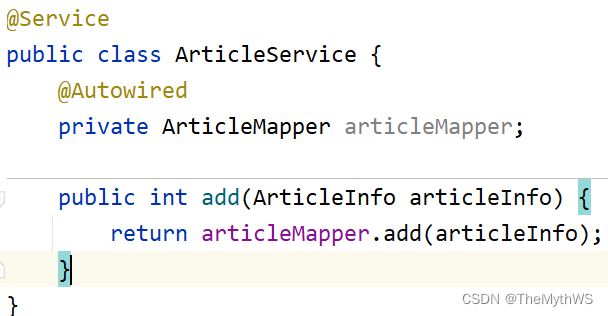
controller
实现文章编辑功能
1.要对文章进行编辑,首先得在编辑文章的界面,在编辑页面的界面时候首先得加载文章的信息,于是就要去查询文章的信息将其展示到页面,根据文章的id去查询文章,同时不是本文章的用户不能去编辑,所以在后端给前端返回文章信息的时候,要确定这篇文章是否是属于当前登录中的用户的,只有确定是当前用户的文章才能进行显示。页面展示的内容为标题和内容,只能对标题和内容进行编辑,所以后端返回给前端文章内容时候,前端构建页面的时候只需要构建文章的标题和内容。
2.当页面正常显示,用户就可以编辑自己的文章,之后就要进行编辑之后再次发布文章,从而更新自己的文章,在修改文章的时候,同时也要验证权限的问题,不是自己的文章不能进行修改的提交操作。
前端核心代码
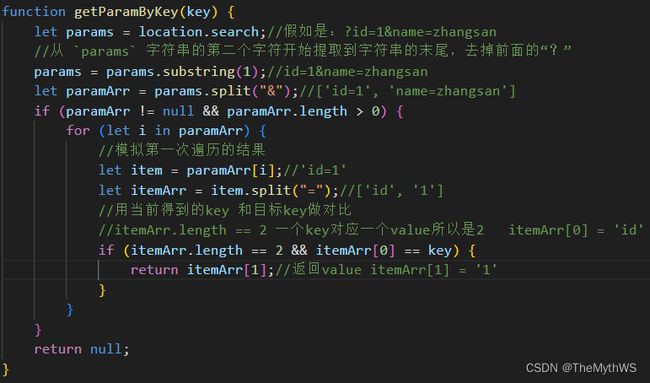
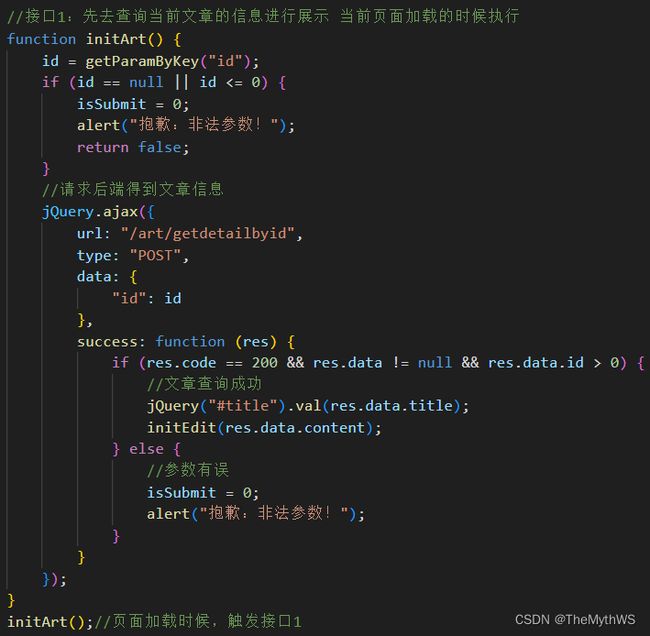
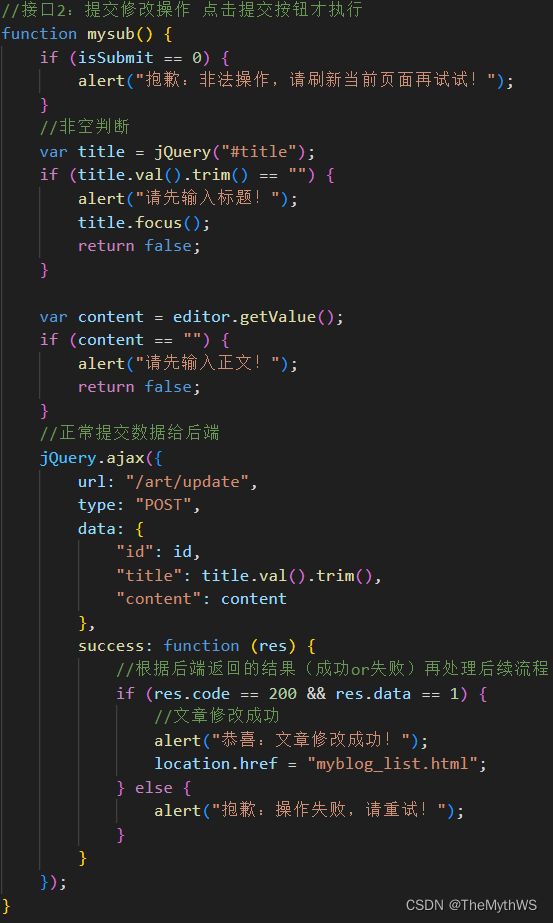
mapper

xml

service
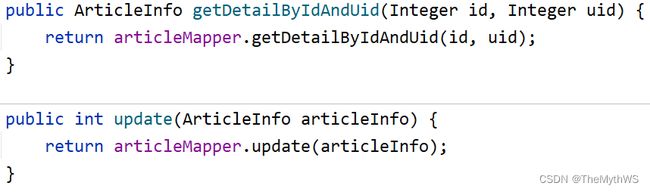
工具类
因为我们经常通过当前session会话获取当前登录用户,所以我们可以封装一个类来专门处理这个事情:
controller
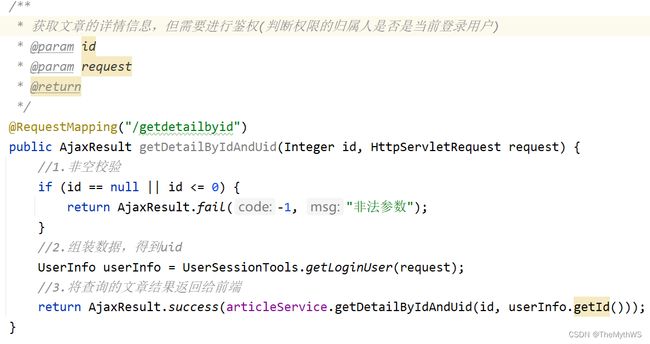
 ps:一定要加上uid的获取,用户只能删除自己的文章。
ps:一定要加上uid的获取,用户只能删除自己的文章。
实现注销功能
前端核心代码

后端代码

实现文章内容详情页功能
首先要得到文章的内容,需要文章id(这个id在查询字符串里面)去数据库查询此文章显示到页面,前端只需要提交id就行,后端可以通过当前登录的用户得到用户的id,然后再通过文章id和用户id在数据库查询文章,将查询文章的结果返回给前端,这里的文章内容详情包含了文章的标题、作者、阅读量、发布时间。
前端核心代码
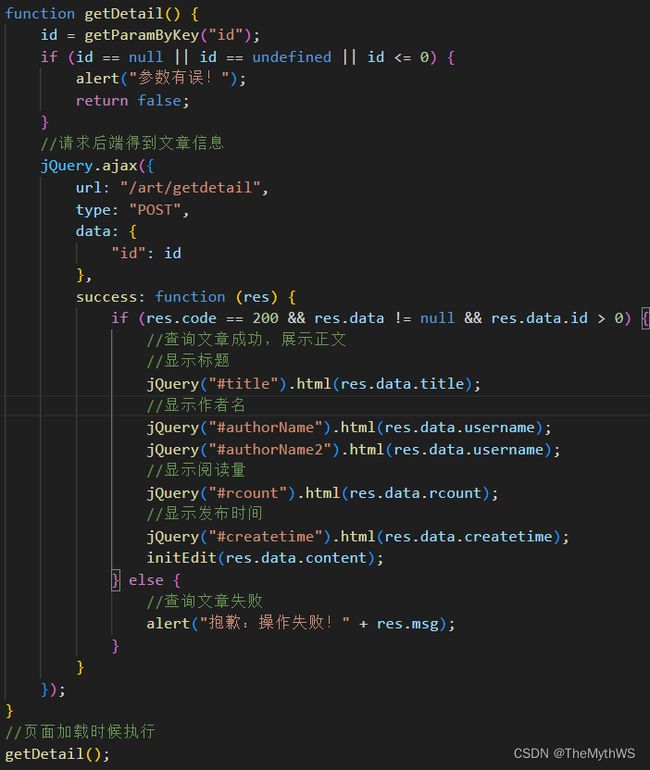
添加拦截器规则
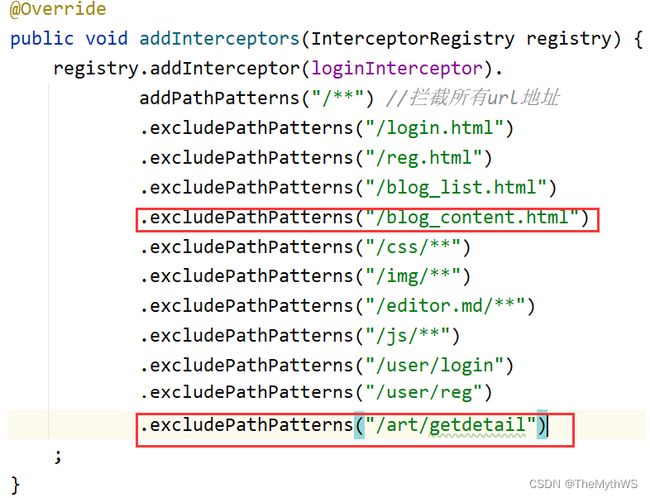
mapper

VO

xml
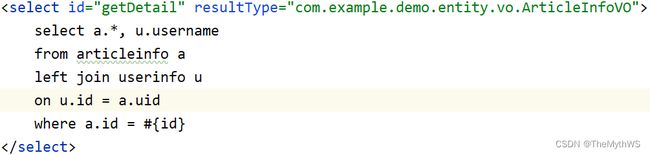
service

controller

实现增加阅读量功能
前端核心代码
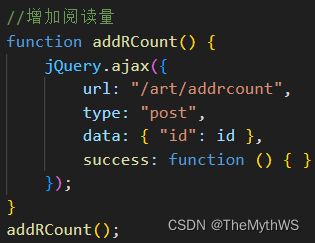
ps:如果多次刷新阅读量依然没有增加,先去前端查找问题:

所以需要添加拦截器规则:(之前上面实现文章详情内容的时候,内容加载不出来也是也可能是这个原因,当然具体原因需要具体分析,可以通过打断点的方式去找问题)

mapper

xml
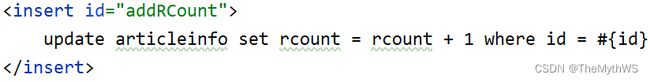
service
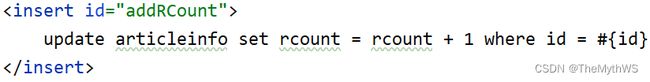
controller

实现判断当前用户登录状态功能
首先要对按钮的实现进行调整,我们可以从下面发现问题:
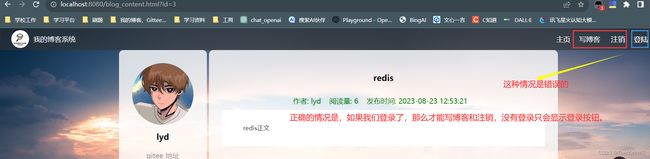
前端核心代码
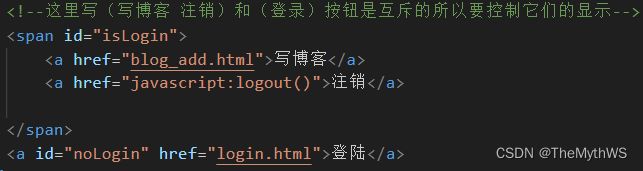

添加拦截器规则
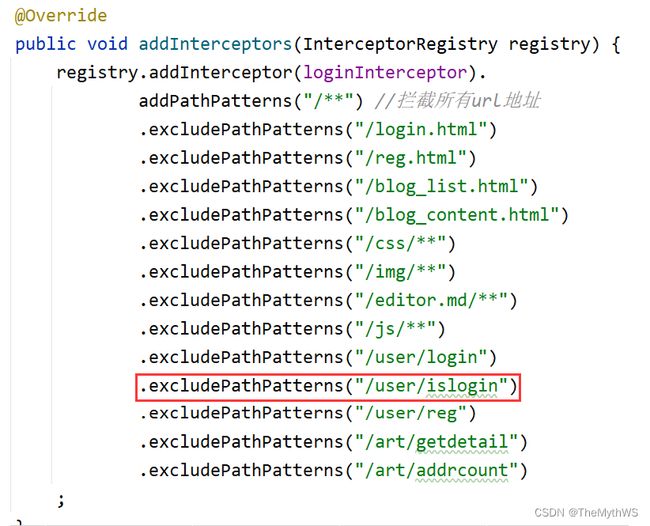
controller

实现用户的博客列表功能
前端核心代码
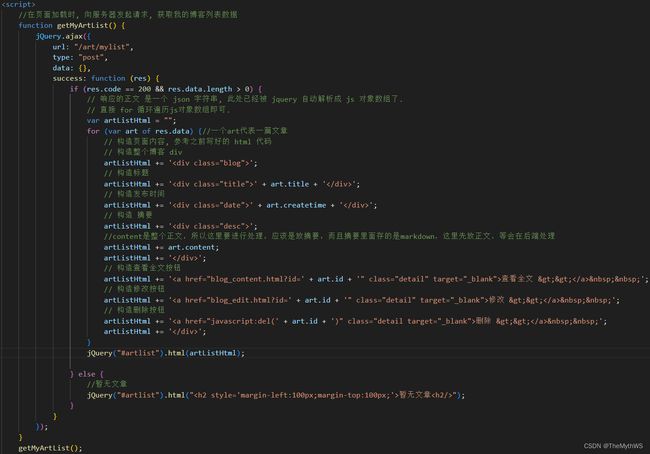
用于截取文章摘要的工具类

mapper

xml
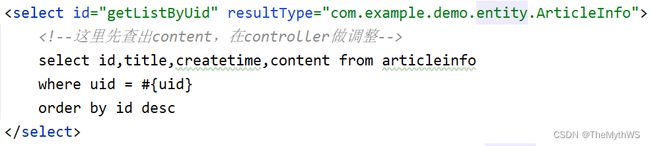
service

controller
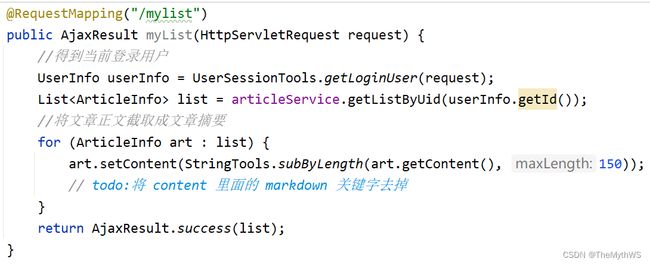
实现文章删除功能
删除文章的时候也要判断归属人,不能删除别人的文章,前端只需要传入文章id就行了,uid是可以通过session获取当前登录用户的属性获取的。
前端核心代码
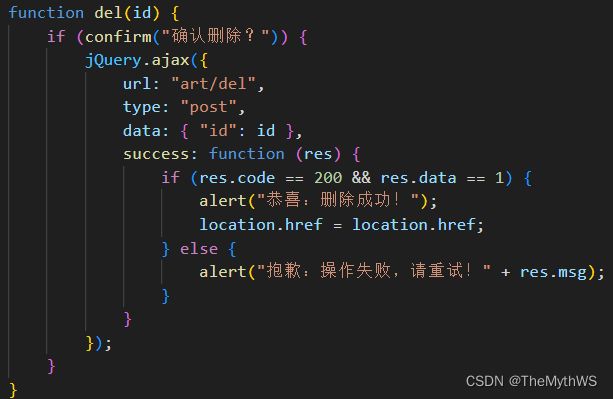
mapper

xml

ps:什么文章都可以删取决于id = #{id},但是能否真正的删除是要根据uid = #{uid}来决定的,要先确定此文章归属人是否是当前登录用户的。
service
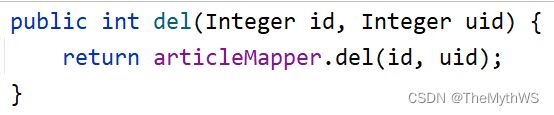
controller
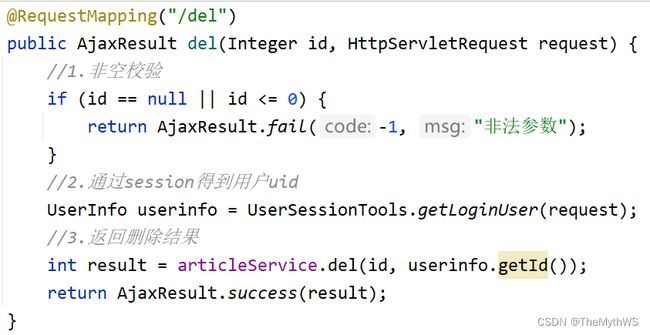
实现统一异常处理功能

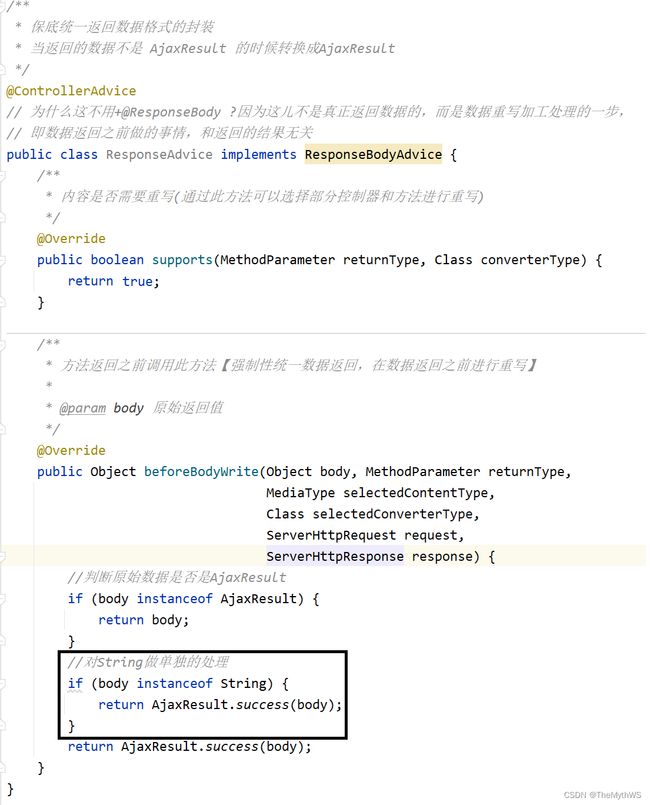
实现统一数据格式返回
我们考虑一种情况:在我们写代码时候,可能有些时候就会忘记有统一的数据返回,或者我们压根不知道有,就会让前端不知所措。
所以这时候我们就需要进行统一数据格式返回。
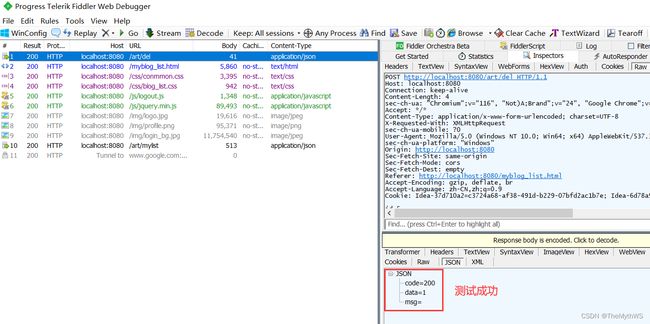
先演示:返回int的情况,查看返回的结果是否是返回刚刚定义好的统一数据格式返回
我们用fidder进行抓包测试:
现在进行String类型的数据测试,如果返回的是String,结果会是咋样?
先在controller弄个测试接口

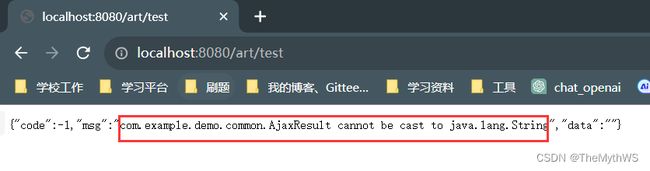
分析为什么会出现此原因?
先将统一异常处理类里面的注解注释掉,记得将注解注释去除
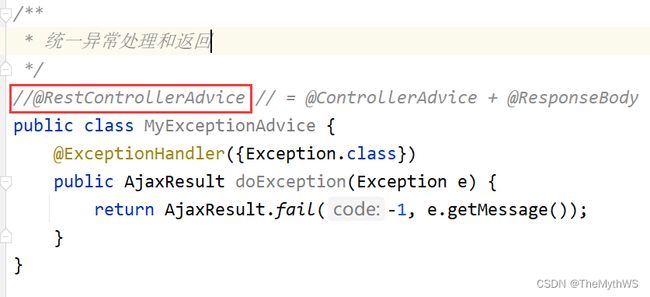
果然发现就是StringHttpMessageConverter惹的祸,后续原因会在统一数据格式返回章节进行解释。
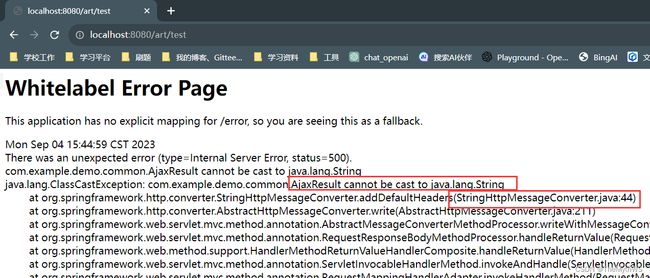
解决方案
第一步:

第二步:
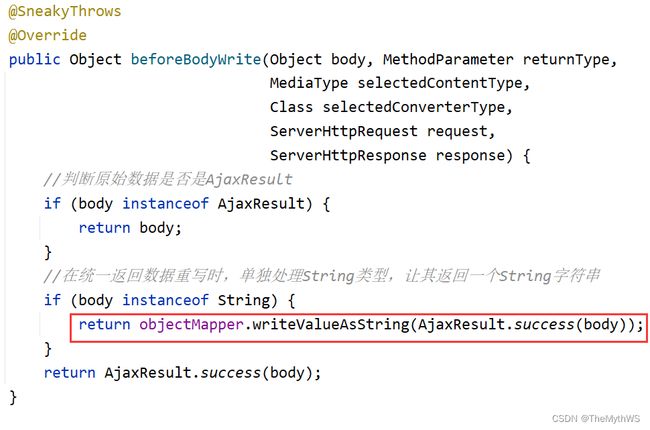
再次进行测试:
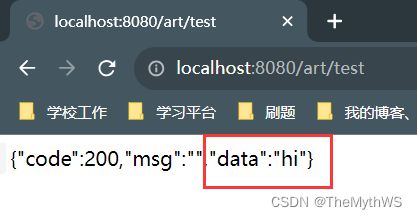
假如我们忘写了,可以发现保底策略可以将"hi"放进data中,这下String类型的数据返回也就解决了。
实现主页博客展示和分页功能
先复习一下数据库上如何实现分页查询
select * from emp limit 0,5
sql语句通过limit关键字实现数据的分页查询, limit后面可以放两个整数作为参数,前一个参数的意义为从那条数据开始查询,后一个参数的意义是连续取出多少条
如果查询 第n 页,每页x条 数据那么sql语句应该写成Select * from emp limit (n-1)*x,x
分页查询的sql语句代码公式为:SELECT * FROM emp LIMIT (页码数-1)*页大小,页大小
第一点 : index ,size start =(index-1)*size;
第二点: maxpage = if (total % size == 0) { maxpage = total / size }
else { maxpage = total / size + 1 }
假设有100条数据,页大小为5,那么要分20页
假设有103条数据,页大小为5,那么要分21页 第21页装3条数据
即:如果查询的总记录数
能整除页面大小,那么就刚好
不能整除页面大小,页码数+1举例:用员工表来演示
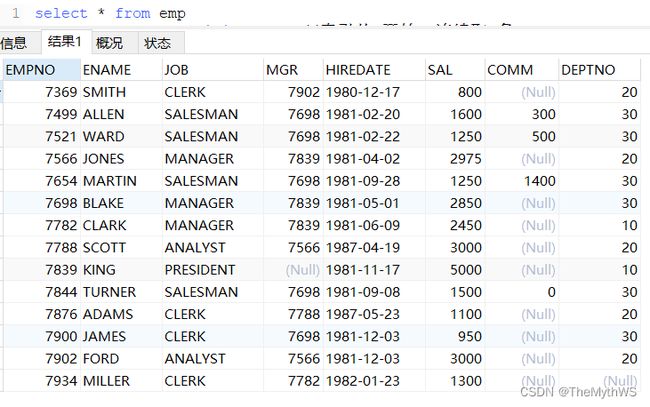
我们先查询所有的员工:
查询第二页的员工,前提:且页大小为7
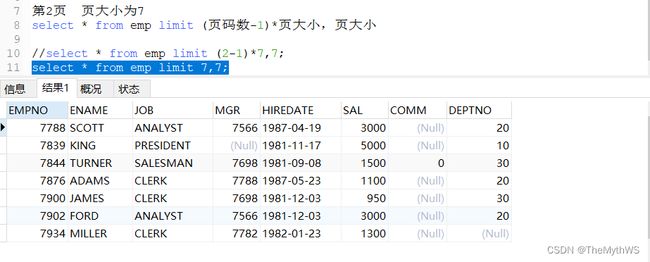
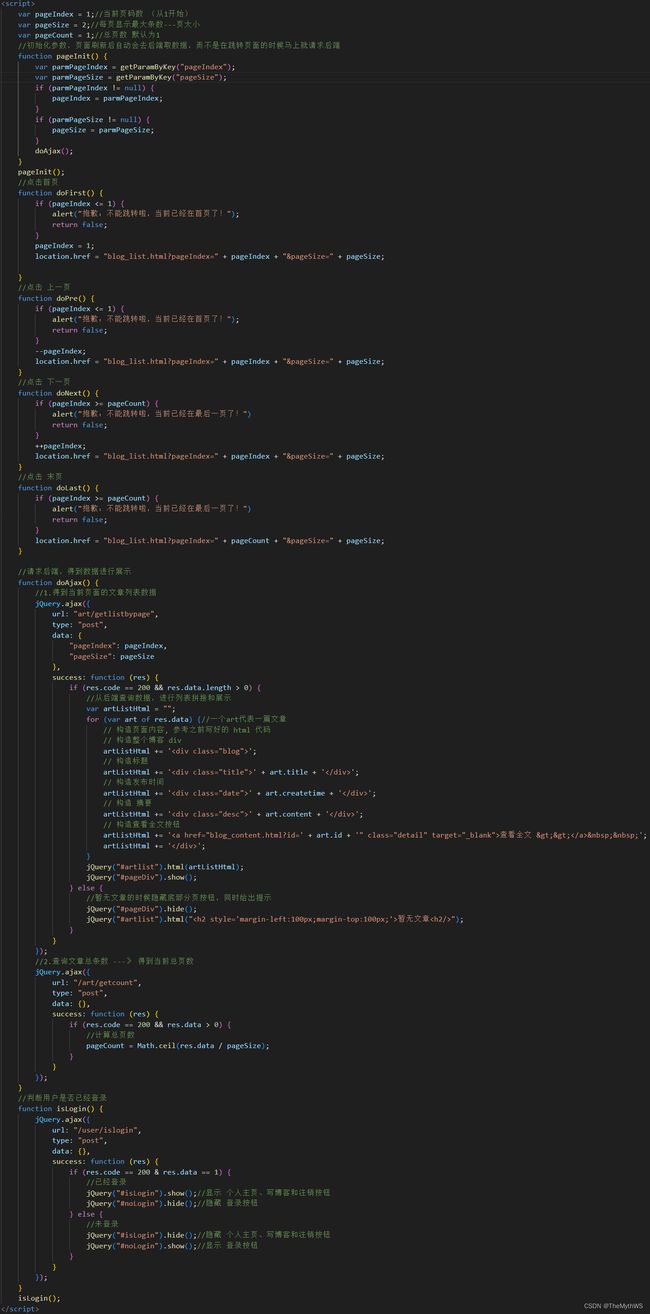
前端给后端传递的参数:
1.pageSize:每页最大显示条数---页大小
2.pageIndex:当前页码数
前端核心代码

 后端
后端
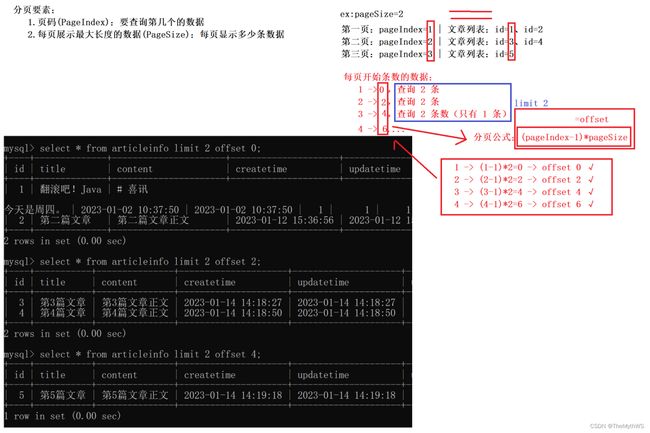
分页公式:
页大小 当前页码数-1 页大小
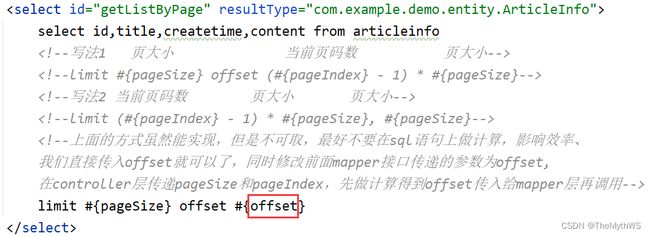
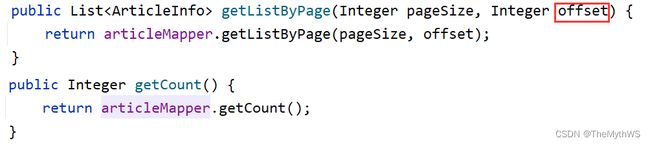
select * from articleinfo limit pageSize offset (pageIndex - 1) * pageSizeoffset = (pageIndex - 1) * pageSize
或者
当前页码数-1 页大小 页大小
select * from articleinfo limit (pageIndex - 1) * pageSize, pageSize
添加拦截器规则
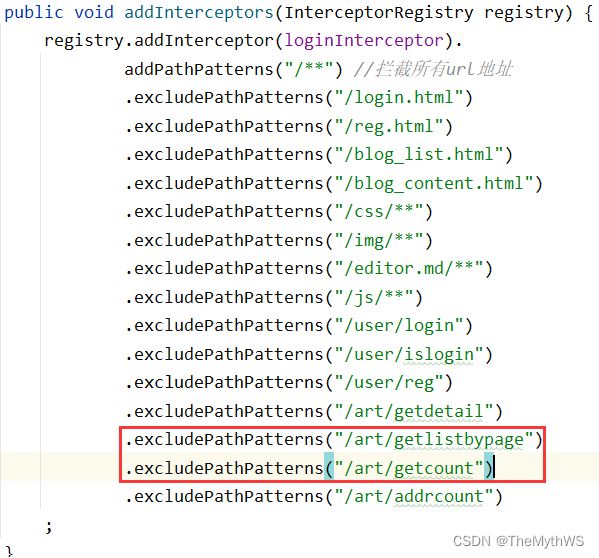
mapper


xml
service
controller


实现密码加盐(增强密码安全性)功能
首先解释下为什么有了md5加密还要进行密码加盐,常规来说我们通常使用md5进行加密,假如我们对"123"---》md5加密---》得到:themyth(固定的值)。
即使md5是不可逆的,但是它可以被穷举,因为在其它语言例如python,c++使用md5加密"123",也是得到一个固定的值,如同上面的themyth,于是我们就可以使用一个固定md5的表(彩虹表)来反推出密码,此时使用md5相当于没有加盐,相当于给程序加了一把带钥匙的锁,显然这种做法是不行的,这个问题点在于对于同一个字符串每次生成的md5密码是一样,是一样的就可以被穷举。解决方案:加盐处理。
加盐处理:
简单来说就是仍然采用md5加密的方式,只是对于同一个字符串每次生成的md5密码都不一样。
为什么可以让每次生成的密码不一样呢?
实现的关键:使用随机数(称之为盐)
生活案例解释:这好比炒菜来一样,我们每个人在炒菜的时候,加盐的含量不可能完全相同,所以菜的咸淡也会不同。
传统加密vs加盐加密:
md5加密流程:
明文密码---》md5(明文密码)---》密码
加盐加密流程:
1)构建期:明文密码+随机盐值
2)md5(明文密码+随机盐值)---》加盐加密之后的密码,数据库此时还不能直接存这个密码,因为这个密码在进行加盐解密是解不出来的。
原因:
1.md5不可逆,2.数据库也没有随机盐值。
同一个字符串每次生成的密码都是不一样的,如何确定这个密码是正确的呢?也就是说这个密码在数据库是1对多的关系,那我们如何判定这个密码就是我们原始的密码呢?由此可见加盐加密流程本身是很简单的,所以我们不能直接存储这个加盐加密之后的密码。解决方案:
为了能够正确的验证密码,所以在进行加盐加密存储时,必须存储以下两个内容:
1.加盐加密之后的密码
2.随机盐值为什么要存随机盐值?
因为md5解密是不可逆的,这里的解密并不是真正意义上的解密,是按照之前加盐加密的流程再去执行一遍,去还原一下它的滚迹,拿还原之后的滚迹和最终的密码进行判断的,如果说它相等说明密码没有问题,反之则有问题。在进行密码还原的过程中是要用到这个随机盐值的。
简单来说解密步骤:md5(明文密码+随机盐值) 和 之前加盐加密之后的密码:之前就已经存在数据库的[md5(明文密码+随机盐值)] 进行对比。
这两个随机盐值必须相同,才能解密成功。随机盐值有什么作用?
每一个随机盐值对应了一个彩虹数据库,必须要穷举所有的字符,也就是说加入有N个随机盐值,那么就需要N个不同的彩虹数据库,破解成本比较高。
3)将加盐加密之后的密码 + 随机盐值存储到数据库
如何存储?
第一种方案,数据库增加两个字段来存放这两个值,不安全。
第二种方式,既然这个密码和盐值都是相关的,就可以把它们两个整合到一块,也就是存储到一个字段,因为它们本身就是为了密码服务的。
但是又有新的问题?整合之后如何知道哪个是盐值,哪个又是密码呢?如何区分出来?这个时候就需要我们后端自己约定一个规则来分离盐值和加盐加密之后的密码,只要保证我们加密和解密都是同一个规则就行了。
规则常见的有:分隔符、按位数存储密码等。
ps:分隔符也有个缺点,就是传递明文密码的时候不能有分隔符。
这样做的目的是即使别人已经得到我们的数据库了,但是得不到我们的密码了。
规则:按照一个分隔符"$"来分离盐值和加盐加密之后的密码,那么最终密码一共是
32位(uuid)+32位(md5)+1位(分隔符"$") --- 65位
接下来我们写一个密码工具类
/**
* 密码工具类
* 1、加盐加密
* 2、加盐解密
*/
public class PasswordTools {
/**
* 加密(加盐)
*
* @param password 明文密码
* @return 加盐加密之后的密码
*/
public static String encrypt(String password) {
//1.通过UUID生成随机盐值 ps:UUID是32位
String salt = UUID.randomUUID().toString().replace("-", "");
//2.得到加盐加密之后的密码(md5(明文密码+随机盐值)) ps:md5是32位 StandardCharsets.UTF_8是仅有中文才必须要设置
String finalPassword = DigestUtils.md5DigestAsHex((salt + password).getBytes(StandardCharsets.UTF_8));
//3.合并随机盐值和加盐加密之后的密码,合并规则:分隔符
String dbPassword = salt + "$" + finalPassword;//这里加盐加密之后应该是64位+1位分隔符=65位
return dbPassword;
}
/**
* 验证加盐加密之后的密码
*
* @param password 要验证的密码(明文密码,未加密)结果不一定对
* @param dbPassword 数据库中的盐值加密的密码(salt + $ + 加盐加密密码finalPassword)
* @return
*/
public static Boolean decrypt(String password, String dbPassword) {
boolean result = false;
if (StringUtils.hasLength(password) && StringUtils.hasLength(dbPassword) &&
dbPassword.length() == 65 && dbPassword.contains("$")) {//参数正确
String[] dbPasswordArr = dbPassword.split("\\$");
//1.得到之前生成的随机盐值
String salt = dbPasswordArr[0];
//2.得到之前数据库加盐加密之后的密码
String finalPassword = dbPasswordArr[1];
//3.使用同样的加密算法和随机盐值生成验证密码的最终加盐加密的密码
//当然下面重新加盐加密这一步可以去重载encrpy,多传入一个salt参数即可,这个salt就是这里取出来的salt,然后返回密码即可。
password = DigestUtils.md5DigestAsHex((salt + password).getBytes(StandardCharsets.UTF_8));
//4.对比验证密码加盐加密之后的密码和数据库之前已经加盐加密的密码
if (password.equals(finalPassword)) {
result = true;
}
}
return result;
}
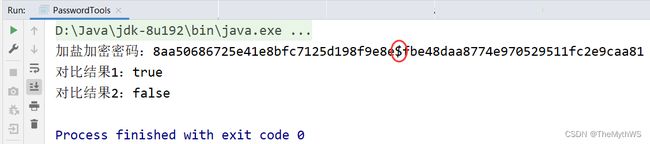
public static void main(String[] args) {
String password = "123";
String dbPassword = PasswordTools.encrypt(password);
System.out.println("加盐加密密码:" + dbPassword);
boolean result = PasswordTools.decrypt("123", dbPassword);
System.out.println("对比结果1:" + result);
boolean result2 = PasswordTools.decrypt("123456", dbPassword);
System.out.println("对比结果2:" + result2);
}
} 
注册用户时候输入密码的时候对用户的密码进行加盐加密:
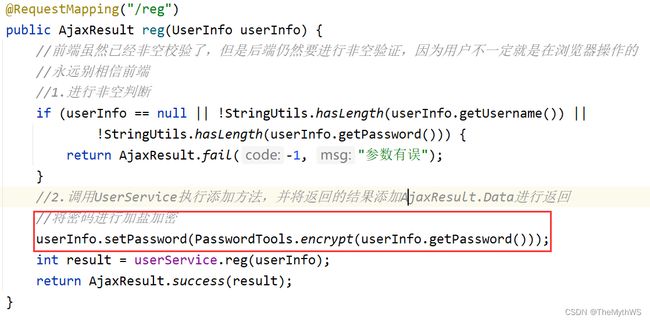
当然我们也可以采用Spring Security加盐,从AOP到拦截器到现在的Spring Security,好比三个时代的产物,AOP自行车、拦截器汽车、Spring Security高铁。
Spring Security是我们以后会经常用的,所以接下来我们使用一下这个框架:
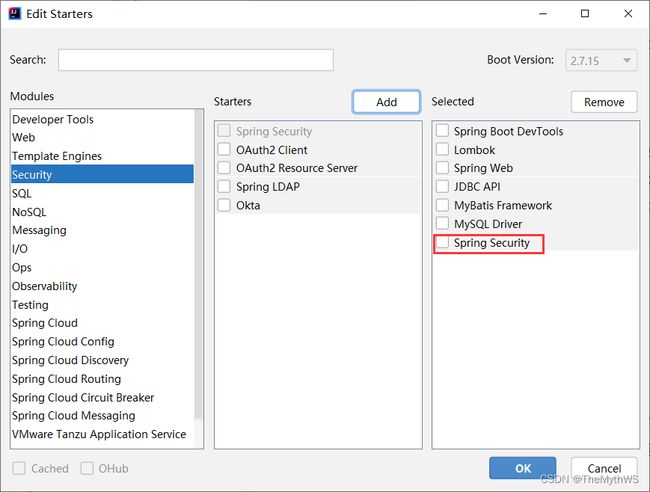
① 添加 Spring Security 框架
方式1:org.springframework.boot spring-boot-starter-security 方式2:
进行测试
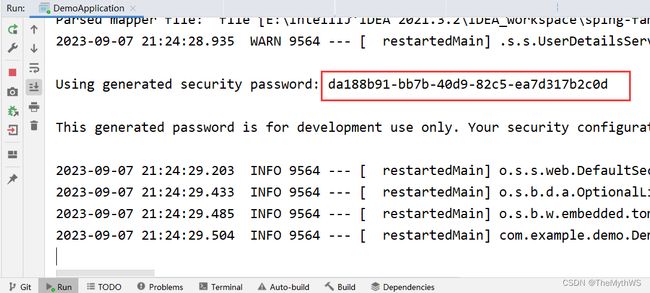
② 关闭 Spring Security 验证
不要去自动注入Spring Security框架(即不要自动加载Spring Security认证了)。

③ 实现加盐和比对
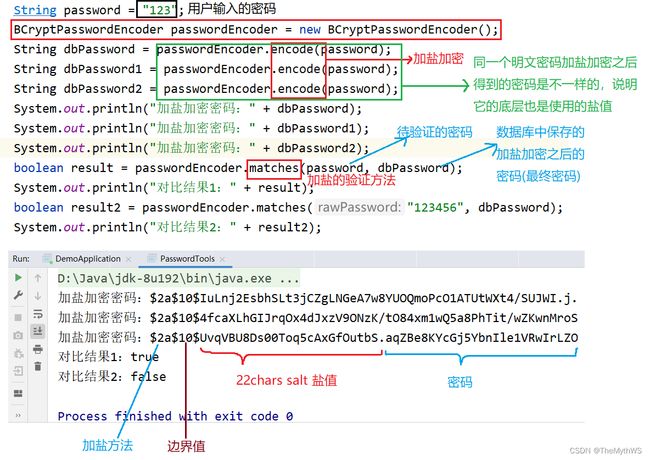
controller测试代码
@RequestMapping("/salt")
public String getSalt() {
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
String password = "123456";
String markPassword = passwordEncoder.encode(password);
System.out.println(markPassword);
System.out.println();
System.out.println(passwordEncoder.encode(password));
System.out.println();
// 参数1:原始密码 / 参数2:已加密密码
System.out.println(passwordEncoder.matches(password, markPassword));
return "hello salt";
}
实现验证码功能
在这里引用了第三方工具类:hutools
在pom.xml中添加依赖:
cn.hutool hutool-all 5.8.16
前端核心代码
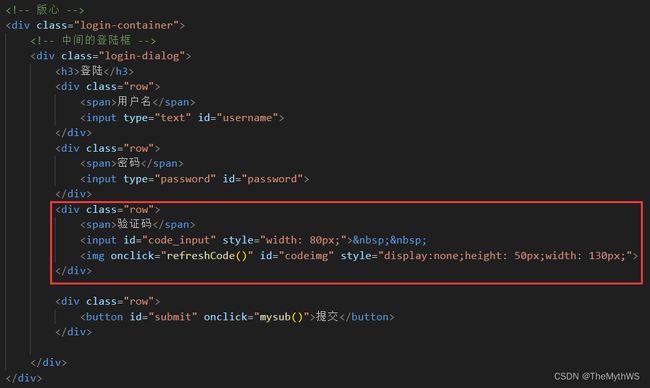
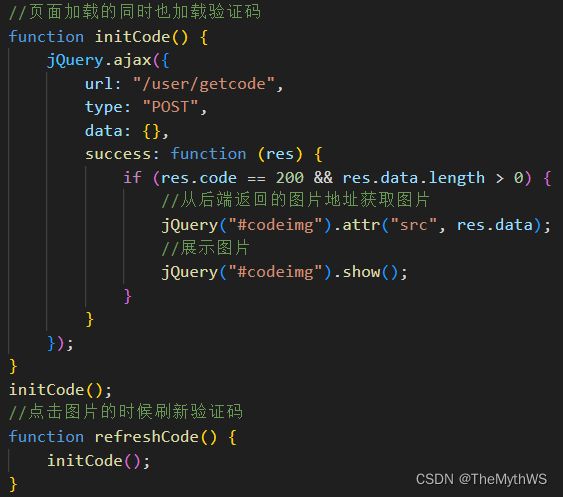
添加拦截器规则
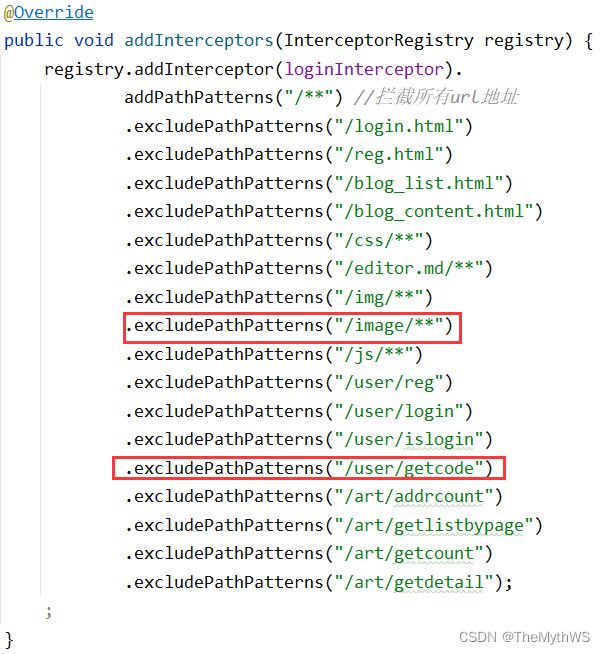
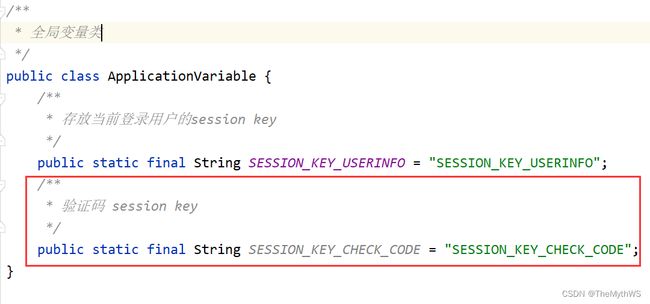
全局变量类新增验证码遍历
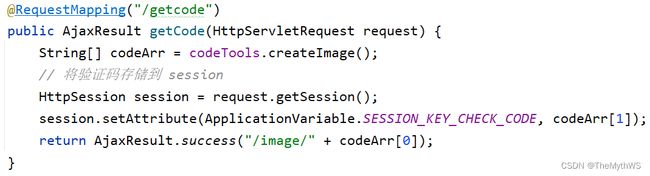
现在多指定几个配置文件,包含生产配置文件和开发配置文件,并将主配置文件暂时指向开发配置文件。
主配置文件appllication.properties
# 配置数据库的连接字符串
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/myblog?characterEncoding=utf8&useSSL=false
spring.datasource.username=root
spring.datasource.password=111111
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 设置 Mybatis 的 xml 保存路径
mybatis.mapper-locations=classpath:mybatis/*Mapper.xml
# 配置打印 MyBatis 执行的 SQL
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
# 配置打印 MyBatis 执行的 SQL
logging.level.com.mybatis.demo=debug
# 配置运行环境
spring.profiles.active=dev
开发配置文件application-dev.properties
imgpath=D:\\Work\\image\\
生产环境配置文件application-prod.properties
imgpath=/root/image/
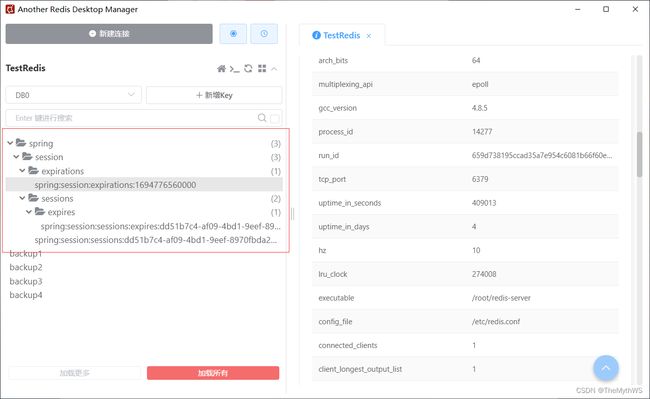
实现将Session存储的用户信息持久化到Redis功能
添加依赖

或者pom.xml
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.session
spring-session-data-redis
在主配置文件中添加redis配置信息
# 设置连接的Redis数据库的索引。默认情况下,索引为0,即连接到默认的数据库。
# 如果设置多个Redis实例,可以通过此项进行区分。
spring.redis.database=0
# 设置连接的Redis服务器的主机名或IP地址
spring.redis.host=x.x.x.x
spring.redis.password=
# 设置连接的Redis服务器的端口号。在此,服务器的端口号为6379,这是Redis默认的端口号,默认的话可以省略不写。
spring.redis.port=6379
# 设置会话存储类型为Redis
spring.session.store-type=redis
# 设置服务器上所有Servlet的会话超时时间为1800秒,即30分钟。
# Spring Boot默认的会话超时时间为30分钟,但在这里,它被明确地设定为1800秒
server.servlet.session.timeout=1800
# 设置Redis的flush mode为'on_save'。flush mode决定了何时将数据写入磁盘。
# 'on_save'意味着每次数据被保存时都会立即写入磁盘,这可以保证数据的持久性,但可能会影响性能。
spring.session.redis.flush-mode=on_save
# 设置Spring Session在Redis中的命名空间为'spring:session'。
# 这是为了防止不同的应用在同一Redis实例中产生数据冲突。每个应用都可以使用不同的命名空间来保存自己的会话数据。
spring.session.redis.namespace=spring:session
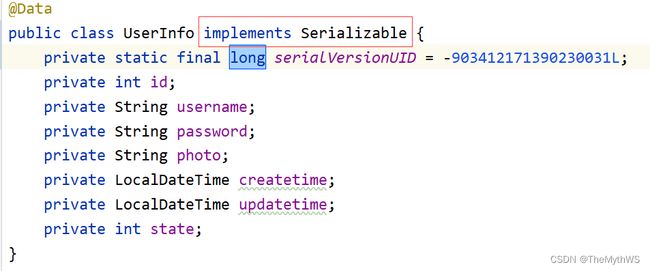
让用户类实现序列化接口,并生成序列版本号
当然本项目还有很多可以扩展的点:
1.文章保存草稿
2.定时发布功能
3.用户多次登录,账号冻结的业务
4.评论功能
5.个人中心:支持修改密码、修改昵称(非登录名)、上传头像等功能
6.找回密码
本项目只是作为一个比较基础的巩固自己学习web开发阶段对知识的实践,当然还有很多不足,请大佬多多指点!!!谢谢
源码地址:https://gitee.com/themyth_ws/sping-family-bucket/tree/master/myblog-ssm