基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(二)
目录
- 前言
- 总体设计
-
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
-
- 1. 数据预处理
- 2. 模型构建
-
- 1)定义模型结构
- 2)优化损失函数
- 3. 模型训练及保存
-
- 1)模型训练
- 2)模型保存
- 相关其它博客
- 工程源代码下载
- 其它资料下载
前言
本项目采用了矩阵分解算法,用于对玩家已游玩的数据进行深入分析。它的目标是从众多游戏中筛选出最适合该玩家的游戏,以实现一种相对精准的游戏推荐系统。
首先,项目会收集并分析玩家已经玩过的游戏数据,包括游戏名称、游戏时长、游戏评分等信息。这些数据构成了一个大型的用户-游戏交互矩阵,其中每一行代表一个玩家,每一列代表一个游戏,矩阵中的值表示玩家与游戏之间的交互情况。
接下来,项目运用矩阵分解算法,将用户-游戏这稀疏矩阵用两个小矩阵——特征-游戏矩阵和用户-特征矩阵,进行近似替代。这个分解过程会将玩家和游戏映射到一个潜在的特征空间,从而能够推断出玩家与游戏之间的潜在关系。
一旦模型训练完成,系统可以根据玩家的游戏历史,预测他们可能喜欢的游戏。这种预测是基于玩家与其他玩家的相似性以及游戏与其他游戏的相似性来实现的。因此,系统可以为每个玩家提供个性化的游戏推荐,考虑到他们的游戏偏好和历史行为。
总的来说,本项目的目标是通过矩阵分解和潜在因子模型,提供一种更为精准的游戏推荐系统。这种个性化推荐可以提高玩家的游戏体验,同时也有助于游戏平台提供更好的游戏推广和增加用户黏性。
总体设计
本部分包括系统整体结构图和系统流程图。
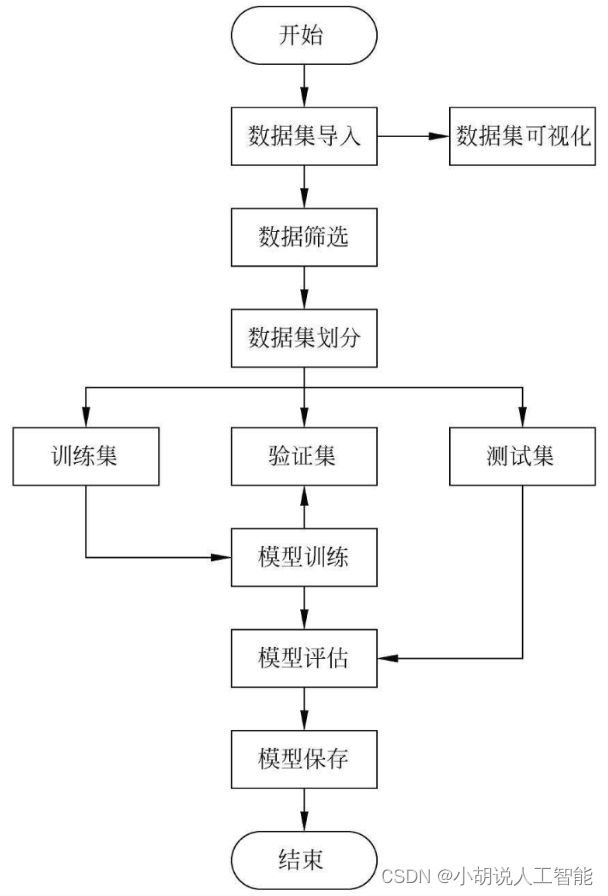
系统整体结构图
系统整体结构如图所示。

系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、TensorFlow环境、 PyQt5环境。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133148686#_38
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型测试,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
数据集来源于Kaggle,链接地址为https://www.kaggle.com/tamber/steam-video-games,此数据集包含了用户的ID、游戏名称、是否购买或游玩、游戏时长,其中:共包含12393名用户,涉及游戏数量5155款。将数据集置于Jupyter工作路径下的steam-video-games文件夹中。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133148686#1__97
2. 模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
1)定义模型结构
使用矩阵分解算法,将用户-游戏这稀疏矩阵用两个小矩阵——特征-游戏矩阵和用户-特征矩阵,进行近似替代。
tf.reset_default_graph()
#偏好矩阵
pref = tf.placeholder(tf.float32, (n_users, n_games))
#游戏时间矩阵
interactions = tf.placeholder(tf.float32, (n_users, n_games))
user_idx = tf.placeholder(tf.int32, (None))
n_features = 30 #隐藏特征个数设置为30
#X矩阵(用户-隐藏特征)表示用户潜在偏好
X = tf.Variable(tf.truncated_normal([n_users, n_features], mean = 0,
stddev = 0.05), dtype = tf.float32, name = 'X')
#Y矩阵(游戏-隐藏特征)表示游戏潜在特征
Y = tf.Variable(tf.truncated_normal([n_games, n_features], mean = 0,
stddev = 0.05), dtype = tf.float32, name = 'Y')
#初始化用户偏差
user_bias = tf.Variable(tf.truncated_normal([n_users, 1], stddev = 0.2))
#将向量连接到用户矩阵
X_plus_bias = tf.concat([X,
user_bias,
tf.ones((n_users, 1), dtype = tf.float32)],
axis = 1)
#初始化游戏偏差
item_bias = tf.Variable(tf.truncated_normal([n_games, 1], stddev = 0.2))
#将向量连接到游戏矩阵
Y_plus_bias = tf.concat([Y,
tf.ones((n_games, 1), dtype = tf.float32),
item_bias],
axis = 1)
#通过矩阵乘积确定结果评分矩阵
pred_pref = tf.matmul(X_plus_bias, Y_plus_bias, transpose_b = True)
#使用游戏时长与alpha参数构造置信度矩阵
conf = 1 + conf_alpha * interactions
2)优化损失函数
L2范数常用于矩阵分解算法的损失函数中。因此,本项目的损失函数也引入了L2范数以避免过拟合现象。使用Adagrad优化器优化模型参数。
相关代码如下:
cost = tf.reduce_sum(tf.multiply(conf, tf.square(tf.subtract(pref, pred_pref))))
l2_sqr = tf.nn.l2_loss(X) + tf.nn.l2_loss(Y) + tf.nn.l2_loss(user_bias) + tf.nn.l2_loss(item_bias)
lambda_c = 0.01
loss = cost + lambda_c * l2_sqr
lr = 0.05
optimize = tf.train.AdagradOptimizer(learning_rate = lr).minimize(loss)
3. 模型训练及保存
由于本项目使用的数据集中,将游戏的DLC (Downloadable Content,后续可下载内容)单独作为另一款游戏列举,因此,在计算准确率时,DLC和游戏本体判定为同一款游戏,同系列的游戏也可以判定为同一款。
相关代码如下:
#精确度计算优化,将游戏本体和DLC合并为同一种游戏
def precision_dlc(recommandations, labels):
#推荐的游戏按单词划分
recommandations_split = []
#实际购买的游戏按单词划分
labels_split = []
for label in labels:
labels_split.append(idx2game[label].split())
for game in recommandations:
recommandations_split.append(idx2game[game].split())
count = 0
for game in recommandations_split:
for label in labels_split:
#当推荐的游戏与实际购买的游戏单词重合度高于阈值判定为同一款游戏
if(len(set(game)&set(label))/min(len(game),len(label))) > 0.2:
count += 1
break
return float(count / len(recommandations))
推荐的游戏方式为,对用户-游戏矩阵进行排序,选取评分最高的5个游戏作为推荐,计算准确率并返回,相关代码如下:
#从预测的列表中挑选最高的k个
def top_k_precision(pred, mat, k, user_idx):
precisions = []
for user in user_idx:
rec = np.argsort(-pred[user, :])
#选取推荐评分最高的k个
top_k = rec[:k]
labels = mat[user, :].nonzero()[0]
#计算推荐与实际的准确率并返回
precision = precision_dlc(top_k, labels)
precisions.append(precision)
return np.mean(precisions)
1)模型训练
相关代码如下:
iterations = 500
#绘图用数据:误差、训练集准确率
fig_loss = np.zeros([iterations])
fig_train_precision = np.zeros([iterations])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(iterations):
sess.run(optimize, feed_dict = {pref: train_matrix,
interactions: user_game_interactions})
if i % 10 == 0:
mod_loss = sess.run(loss, feed_dict = {pref: train_matrix,
interactions: user_game_interactions})
mod_pred = pred_pref.eval()
train_precision = top_k_precision(mod_pred, train_matrix,
k, val_users_idx)
val_precision = top_k_precision(mod_pred, val_matrix,
k, val_users_idx)
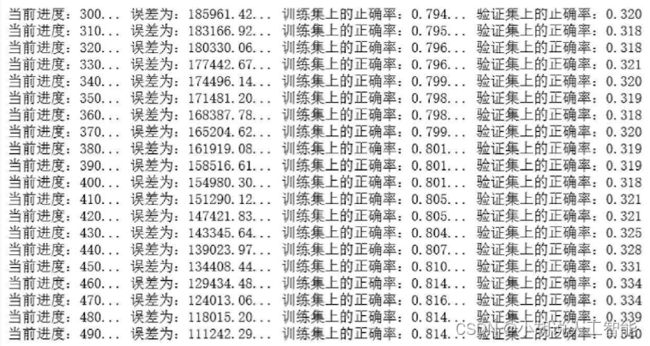
print('当前进度:{}...'.format(i),
'误差为:{:.2f}...'.format(mod_loss),
'训练集上的正确率:{:.3f}...'.format(train_precision),
'验证集上的正确率:{:.3f}'.format(val_precision))
fig_loss[i] = sess.run(loss, feed_dict = {pref: train_matrix,
interactions: user_game_interactions})
fig_train_precision[i] = top_k_precision(mod_pred, train_matrix,
k, val_users_idx)
rec = pred_pref.eval()
test_precision = top_k_precision(rec, test_matrix, k, test_users_idx)
print('\n')
print('模型完成,正确率为:{:.3f}'.format(test_precision))
完成500次训练,每训练10次输出在训练集和验证集上的准确率,如图所示。
2)模型保存
为方便使用模型,需要将训练得到的结果使用Joblib进行保存,相关代码如下:
#将训练得到的评分矩阵保存
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
joblib.dump(pred_pref.eval(), './Save_data/rec.pkl')
模型保存后,可以方便在PyQt 5或其他项目中使用。
相关其它博客
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(一)
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(三)
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。