基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(三)
目录
- 前言
- 总体设计
-
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
-
- 1. 模型训练
-
- 1)数据集分析
- 2)数据预处理
- 3)模型创建
-
- (1)定义参数
- (2)定义网络数据输入占位符
- (3)定义用户嵌入矩阵
- (4)定义电影嵌入矩阵
- (5)定义电影类型嵌入矩阵
- (6)处理电影名称
- (7) 全连接层
- (8)定义计算图
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目专注于MovieLens数据集,并采用TensorFlow中的2D文本卷积网络模型。它结合了协同过滤算法来计算电影之间的余弦相似度,并通过用户的交互方式,以单击电影的方式,提供两种不同的电影推荐方式。
首先,项目使用MovieLens数据集,这个数据集包含了大量用户对电影的评分和评论。这些数据用于训练协同过滤算法,以便推荐与用户喜好相似的电影。
其次,项目使用TensorFlow中的2D文本卷积网络模型,这个模型可以处理电影的文本描述信息。模型通过学习电影的文本特征,能够更好地理解电影的内容和风格。
当用户与小程序进行交互时,有两种不同的电影推荐方式:
-
协同过滤推荐:基于用户的历史评分和协同过滤算法,系统会推荐与用户喜好相似的电影。这是一种传统的推荐方式,通过分析用户和其他用户的行为来推荐电影。
-
文本卷积网络推荐:用户可以通过点击电影或输入文本描述,以启动文本卷积网络模型。模型会分析电影的文本信息,并推荐与输入的电影或描述相匹配的其他电影。这种方式更注重电影的内容和情节相似性。
综合来看,本项目融合了协同过滤和深度学习技术,为用户提供了两种不同但有效的电影推荐方式。这可以提高用户体验,使他们更容易找到符合他们口味的电影。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
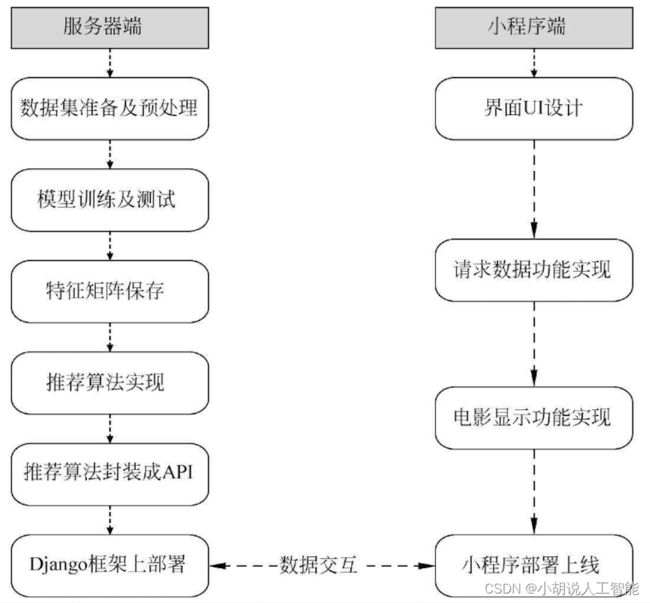
系统流程图
系统流程如图所示。

模型训练流程如图所示。

服务器运行流程如图所示。

运行环境
本部分包括Python环境、TensorFlow环境、 后端服务器、Django和微信小程序环境。
模块实现
本项目包括3个模块:模型训练、后端Django、 前端微信小程序模块,下面分别给出各模块的功能介绍及相关代码。
1. 模型训练
下载数据集,解压到项目目录下的./ml-1m文件夹下。数据集分用户数据users.dat、电影数据movies.dat和评分数据ratings.dat。
1)数据集分析
数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt对数据的描述。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#1_44
2)数据预处理
通过研究数据集中的字段类型,发现有一些是类别字段,将其转成独热编码,但是UserID、MovieID的字段会变稀疏,输入数据的维度急剧膨胀,所以在预处理数据时将这些字段转成数字。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#2_123
3)模型创建
从本地读取数据,相关代码如下:
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(open('preprocess.p', mode='rb'))
加载数据后定义神经网络的模型结构:
(1)定义参数
相关代码如下:
#嵌入矩阵的维度
embed_dim = 32
#用户ID个数
uid_max = max(features.take(0,1)) + 1 #6040
#性别个数
gender_max = max(features.take(2,1)) + 1 #1+1=2
#年龄类别个数
age_max = max(features.take(3,1)) + 1 #6+1=7
#职业个数
job_max = max(features.take(4,1)) + 1 #20+1=21
#电影ID个数
movie_id_max = max(features.take(1,1)) + 1 #3952
#电影类型个数
movie_categories_max = max(genres2int.values()) + 1 #18+1=19
#电影名单词个数
movie_title_max = len(title_set) #5216
#对电影类型嵌入向量做加和操作的标志,考虑过使用mean做平均,但是没实现mean
combiner = "sum"
#电影名长度
sentences_size = title_count #15
#文本卷积滑动窗口,分别滑动2,3, 4, 5个单词
window_sizes = {2, 3, 4, 5}
#文本卷积核数量
filter_num = 8
#电影ID转下标的字典,数据集中电影ID跟下标不一致,例如第5行的数据电影ID不一定是5
movieid2idx = {val[0]:i for i, val in enumerate(movies.values)}
(2)定义网络数据输入占位符
def get_inputs():
#输入占位符
#用户数据输入
uid = tf.placeholder(tf.int32, [None, 1], name="uid")
user_gender = tf.placeholder(tf.int32, [None, 1], name="user_gender")
user_age = tf.placeholder(tf.int32, [None, 1], name="user_age")
user_job = tf.placeholder(tf.int32, [None, 1], name="user_job")
#电影数据输入
movie_id = tf.placeholder(tf.int32, [None, 1], name="movie_id")
movie_categories = tf.placeholder(tf.int32, [None, 18], name="movie_categories")
movie_titles = tf.placeholder(tf.int32, [None, 15], name="movie_titles")
#目标评分
targets = tf.placeholder(tf.int32, [None, 1], name="targets")
#学习率
LearningRate = tf.placeholder(tf.float32, name = "LearningRate")
#弃用率
dropout_keep_prob = tf.placeholder(tf.float32, name = "dropout_keep_prob")
return uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, LearningRate, dropout_keep_prob
(3)定义用户嵌入矩阵
在预处理数据时将UserID、MovieID的字段转成数字,当作嵌入矩阵的索引,在网络的第一层使用嵌入层,维度是(N, 32)和(N,16) 其中N是电影总数。
定义用户嵌入矩阵的相关代码如下:
def get_user_embedding(uid, user_gender, user_age, user_job):
#定义User的嵌入矩阵,返回某个userid的嵌入层向量
with tf.name_scope("user_embedding"):
#用户ID嵌入矩阵
uid_embed_matrix = tf.Variable(tf.random_uniform([uid_max, embed_dim], -1, 1), name = "uid_embed_matrix")
uid_embed_layer = tf.nn.embedding_lookup(uid_embed_matrix, uid, name = "uid_embed_layer")
#用户性别嵌入矩阵
gender_embed_matrix = tf.Variable(tf.random_uniform([gender_max, embed_dim // 2], -1, 1), name= "gender_embed_matrix")
gender_embed_layer = tf.nn.embedding_lookup(gender_embed_matrix, user_gender, name = "gender_embed_layer")
#用户年龄嵌入矩阵
age_embed_matrix = tf.Variable(tf.random_uniform([age_max, embed_dim // 2], -1, 1), name="age_embed_matrix")
age_embed_layer = tf.nn.embedding_lookup(age_embed_matrix, user_age, name="age_embed_layer")
#用户职业嵌入矩阵
job_embed_matrix = tf.Variable(tf.random_uniform([job_max, embed_dim // 2], -1, 1), name = "job_embed_matrix")
job_embed_layer = tf.nn.embedding_lookup(job_embed_matrix, user_job, name = "job_embed_layer")
return uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer
(4)定义电影嵌入矩阵
相关代码如下:
def get_movie_id_embed_layer(movie_id):
#定义MovieId的嵌入矩阵,返回某个电影ID的嵌入层向量
with tf.name_scope("movie_embedding"):
movie_id_embed_matrix = tf.Variable(tf.random_uniform([movie_id_max, embed_dim], -1, 1), name = "movie_id_embed_matrix")
movie_id_embed_layer = tf.nn.embedding_lookup(movie_id_embed_matrix, movie_id, name = "movie_id_embed_layer")
return movie_id_embed_layer
(5)定义电影类型嵌入矩阵
有时一个电影有多个类型,从嵌入矩阵索引出来是一个(n,32)的矩阵,这里的a是指某部电影所包含的类型。因为有多个类型,所以要将这个矩阵求和,变成(1,32)的向量。
相关代码如下:
def get_movie_categories_layers(movie_categories):
#电影类型的嵌入矩阵,返回某部电影所有类型向量的和
with tf.name_scope("movie_categories_layers"):
#定义嵌入矩阵
movie_categories_embed_matrix = tf.Variable(tf.random_uniform([movie_categories_max, embed_dim], -1, 1), name = "movie_categories_embed_matrix")
#根据索引选择电影类型向量
movie_categories_embed_layer = tf.nn.embedding_lookup(movie_categories_embed_matrix, movie_categories, name = "movie_categories_embed_layer")
#向量元素相加
if combiner == "sum":
movie_categories_embed_layer = tf.reduce_sum(movie_categories_embed_layer, axis=1, keep_dims=True)
return movie_categories_embed_layer
(6)处理电影名称
电影名的处理比较特殊,未使用循环神经网络,而是用了文本卷积网络。网络的第一层是词嵌入层, 由每个单词的嵌入向量组成矩阵。第二层使用多个不同尺寸(窗口大小)的卷积核在嵌入矩阵上做卷积,窗口大小指的是每次卷积覆盖几个单词。这里与图像做卷积不同,图像卷积
通常用2X2、3X3、5X5的尺寸,而文本卷积要覆盖整个单词的嵌入向量,尺寸是单词数、向量维度,例如,每次滑动3、4或5个单词。第三层网络是最大池化得到一一个长向量,第四层使用丢弃做正则化,得到电影Title的特征。
相关代码如下:
def get_movie_cnn_layer(movie_titles):
#从嵌入矩阵中得到电影名对应的各单词嵌入向量
with tf.name_scope("movie_embedding"):
movie_title_embed_matrix=tf.Variable(tf.random_uniform([movie_title_max, embed_dim], -1, 1), name = "movie_title_embed_matrix")
movie_title_embed_layer=tf.nn.embedding_lookup(movie_title_embed_matrix, movie_titles, name = "movie_title_embed_layer")
movie_title_embed_layer_expand = tf.expand_dims(movie_title_embed_layer, -1)
#对文本嵌入层使用不同尺寸的卷积核做卷积和最大池化
pool_layer_lst = []
for window_size in window_sizes:
with tf.name_scope("movie_txt_conv_maxpool_{}".format(window_size)):
#权重
filter_weights = tf.Variable(tf.truncated_normal([window_size, embed_dim, 1, filter_num],stddev=0.1),name = "filter_weights")
filter_bias = tf.Variable(tf.constant(0.1, shape=[filter_num]), name="filter_bias")
#卷积层
conv_layer = tf.nn.conv2d(movie_title_embed_layer_expand, filter_weights, [1,1,1,1], padding="VALID", name="conv_layer")
relu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer,filter_bias), name ="relu_layer")
#池化层
maxpool_layer = tf.nn.max_pool(relu_layer, [1,sentences_size - window_size + 1 ,1,1], [1,1,1,1], padding="VALID", name="maxpool_layer")
pool_layer_lst.append(maxpool_layer)
#丢弃层
with tf.name_scope("pool_dropout"):
pool_layer = tf.concat(pool_layer_lst, 3, name ="pool_layer")
max_num = len(window_sizes) * filter_num
pool_layer_flat = tf.reshape(pool_layer , [-1, 1, max_num], name = "pool_layer_flat")
dropout_layer = tf.nn.dropout(pool_layer_flat, dropout_keep_prob, name = "dropout_layer")
return pool_layer_flat, dropout_layer
(7) 全连接层
从嵌入层索引出特征后,传入全连接层,将输出再次传入全连接层,模型结构如图所示,最终分别得到(1,200) 的用户和电影两个特征向量。
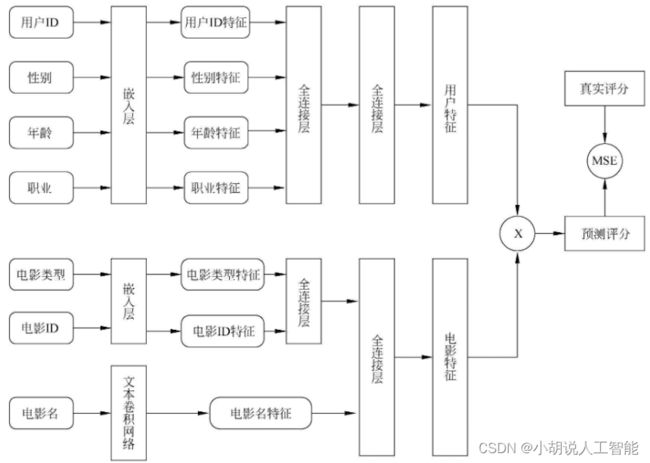
相关代码如下:
#用户嵌入层向量全连接层定义函数
def get_user_feature_layer(uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer):
#用户嵌入层向量全连接
with tf.name_scope("user_fc"):
#第一层全连接
uid_fc_layer = tf.layers.dense(uid_embed_layer, embed_dim, name = "uid_fc_layer", activation=tf.nn.relu)
gender_fc_layer = tf.layers.dense(gender_embed_layer, embed_dim, name = "gender_fc_layer", activation=tf.nn.relu)
age_fc_layer = tf.layers.dense(age_embed_layer, embed_dim, name ="age_fc_layer", activation=tf.nn.relu)
job_fc_layer = tf.layers.dense(job_embed_layer, embed_dim, name = "job_fc_layer", activation=tf.nn.relu)
#第二层全连接
user_combine_layer = tf.concat([uid_fc_layer, gender_fc_layer, age_fc_layer, job_fc_layer], 2) #(?, 1, 128)
user_combine_layer = tf.contrib.layers.fully_connected(user_combine_layer, 200, tf.tanh) #(?, 1, 200)
user_combine_layer_flat = tf.reshape(user_combine_layer, [-1, 200])
return user_combine_layer, user_combine_layer_flat
#电影特征全连接层定义函数
def get_movie_feature_layer(movie_id_embed_layer, movie_categories_embed_layer, dropout_layer):
#所有电影特征全连接
with tf.name_scope("movie_fc"):
#第一层全连接
movie_id_fc_layer = tf.layers.dense(movie_id_embed_layer, embed_dim, name = "movie_id_fc_layer", activation=tf.nn.relu)
movie_categories_fc_layer = tf.layers.dense(movie_categories_embed_layer, embed_dim, name = "movie_categories_fc_layer", activation=tf.nn.relu)
#第二层全连接
movie_combine_layer = tf.concat([movie_id_fc_layer, movie_categories_fc_layer, dropout_layer], 2) #(?, 1, 96) movie_combine_layer=tf.contrib.layers.fully_connected(movie_combine_layer,200,tf.tanh)#(?,1, 200)
movie_combine_layer_flat = tf.reshape(movie_combine_layer, [-1, 200])
return movie_combine_layer, movie_combine_layer_flat
(8)定义计算图
目的是训练出用户特征和电影特征,在实现推荐功能时使用。得到这两个特征以后,可以选择任意的方式来拟合评分。对用户特征和电影特征两个(1,200)向量做乘法,将结果与真实评分做回归,采用MSE优化损失。
相关代码如下:
#计算图定义
tf.reset_default_graph()
train_graph = tf.Graph()
with train_graph.as_default():
#获取输入占位符
uid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob = get_inputs()
#获取User的4个嵌入向量
uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer = get_user_embedding(uid, user_gender, user_age, user_job)
#得到用户特征
user_combine_layer, user_combine_layer_flat = get_user_feature_layer(uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer)
#获取电影ID的嵌入向量
movie_id_embed_layer = get_movie_id_embed_layer(movie_id)
#获取电影类型的嵌入向量 movie_categories_embed_layer=get_movie_categories_layers(movie_categories)
#获取电影名的特征向量
pool_layer_flat, dropout_layer = get_movie_cnn_layer(movie_titles)
#得到电影特征
movie_combine_layer, movie_combine_layer_flat = get_movie_feature_layer(movie_id_embed_layer, movie_categories_embed_layer, dropout_layer)
with tf.name_scope("inference"):
#将用户特征和电影特征做矩阵乘法得到一个预测评分
inference = tf.reduce_sum(user_combine_layer_flat * movie_combine_layer_flat, axis=1)
inference = tf.expand_dims(inference, axis=1)
with tf.name_scope("loss"):
#MSE损失,将计算值回归到评分
cost = tf.losses.mean_squared_error(targets, inference )
loss = tf.reduce_mean(cost)
#优化损失
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(lr)
gradients = optimizer.compute_gradients(loss) #代价
train_op=optimizer.apply_gradients(gradients,global_step=global_step)
相关其它博客
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(一)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(二)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(四)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(五)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(六)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(七)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。