爬虫获取一个网站内所有子页面的内容
上一篇介绍了如何爬取一个页面内的所有指定内容,本篇讲的是爬去这个网站下所有子页面的所有指定的内容。
可能有人会说需要的内容复制粘贴,或者直接f12获取需要的文件下载地址一个一个下载就行了,但是如下图十几个一级×几十个二级×一百多个疾病×几百个内容=不太想算下去的数量级…一个mp3一兆多的大小,就只算下载所有的mp3的话就已经是t级别的了,手动一个一个下载恐怕得几个月的不听操作,所以需要本篇介绍的多页面爬虫自动获取,好歹几天时间能自动爬完。
确认需求

我们要获取这个网站下每个的一级科室的每个二级科室的每个疾病下的每个问题及对应的医生回答的mp3语音文件和语音内容,点击每个问题得到的页面如下:

从这里就可以获取到我想要的:问题、医生、问题的回答语音mp3文件、语音内容。
首先确认一下思路:遍历每个一级–>遍历每个二级–>遍历每个疾病–>遍历每一页(如下图)–>点击每个内容进去–>获取问题、医生、mp3、内容

以上是大概的获取思路框架,接下来确认保存形式:每个一级为一个文件夹;在每个一级目录下面存放这个一级的所有二级目录;在每个二级下存放所有对应的疾病目录;在每个疾病目录下存放这个疾病下所有的mp3文件,文件名以“医生-问题”的格式保证不重复,每个疾病目录下只有一个txt文件,里面写入本目录下所有mp3的语音内容,为了后续能快速找到对应内容,给每个内容也加一个“医生-问题”格式的标题。如下图所示:


获取对应元素
再次捋一下我们所需要的是:问题、医生、mp3文件、语音内容,接下来开始获取这4个对应的网页元素,需要说明的是我们要获取的不仅只有这四个,这四个只是获取一个页面内容所需的元素,还需要找到每个一级、二级、疾病、下一页(换页)的元素才能自动获取这个网站所有的这4个内容。
这里需要注意,我们找的每个元素需要找的是在页面中唯一的元素,这样才不会出错。比如所有的一级都放在class为“a”的div标签下,但同样的标签有多个,那么可以再往上一层,发现class为“a”的div标签 在 class为“b”的div标签 的标签下,再看一下 class为“b”的div标签 下的 class为“a”的div标签 这样的组合仅有一个,那这个组合才是我们所需要的元素。
一级科室
f12打开开发者模式,点击箭头选择元素:

这里需要做的是如何获取到这个< dd >标签下的所有< a >标签,经过我的筛选发现class为’yslist_dq’的< div >标签下的第一个< dl >标签的所有< a >标签即是所有的一级科室的元素,我们所需要的是a标签内的text文本内容(作为创建目录的目录名)以及标签的href属性值(用来跳转页面到下一个一级科室)。
二级科室

依旧是元素选择箭头点击任意一个二级科室,图片上可以发现class为’yslist_dq’的< div >标签下的第2个< dl >标签的所有< a >标签即是所有的二级科室的元素,选择标签内的文本内容和href属性值。
疾病筛选
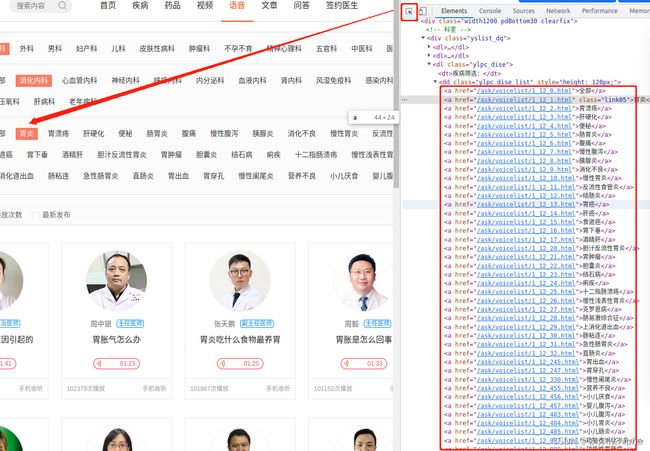
同理可得class为’yslist_dq’的< div >标签下的第3个< dl >标签的所有< a >标签即是所有的疾病筛选的元素,选择文本内容和href属性值。
每个页面
这里的每个页面是获取我们所需要的问题、医生、mp3、语音内容这4个内容的页面。

元素选择箭头(以下开始简称箭头)选择点击任意一个医生头像(一个头像对应一个问题),点击方框内的网址就跳到对应的页面内容中:

那么页面的元素就是a标签的herf属性值,首先获取到这个a标签。
可以看到每个< li >标签为一个头像,这些< li >都在class为“cur05”的< ul >标签下,经验证class为“cur05”的< ul >标签下的< li >标签下的< a >标签为唯一组合,因为每个< li >标签下只有一个< a >标签,所以直接用class为“cur05”的< ul >标签下的所有< a >标签这个组合。
页面内容——问题

经验证图片所见的class为“v_title”的< h3 >标签是唯一的元素,则这个h3标签就是问题的元素,我们获取的是标签的文本内容。
页面内容——医生

class为“mgBottom10”的< ul >标签下的< strong >标签的文本内容。
页面内容——mp3文件
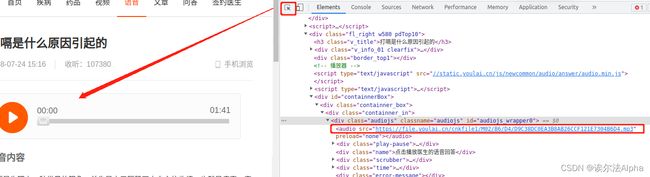
< audio >为唯一的标签,获取其src属性值。
页面内容——语音内容

class为“v_con”的< div >标签下的class为“text”的< div >标签的文本内容。
下一页

class为“pageyl”的< div >标签下的最后一个< li >标签的< a >标签的href属性值。
代码
代码介绍
1.代码的大概思路:就是在上文确认需求中所提到的,获取每个一级的text和href值,用文本创建目录,用href值跳转到遍历到的一级科室页面;同理二级和疾病;然后遍历到第3层的疾病之下,开始获取页面的每个头像对应的href值进行跳转,在跳转的页面中根据上文找到的元素获取我们需要的4个内容;然后点击下一页重复上一步操作,直到没有下一页了。
2.headers本来用的是我自己浏览器中获取到的,但是用一个headers一次性访问上万个页面有时候也会触发反爬机制导致中断,所以我多找几个人要了他们的headers,放入list中,每次跳转页面的时候都从中random选择一个,为了确保有够random随机种子值用当前时间戳。list中的每个headers除了user-agent也可以加入cookies减少中断概率(如第一个headers中的注释所示)。
3.因为一次性访问太多次有可能有时候访问一个页面不给响应,此时使用resolve()函数循环请求该网站,每次循环随机选择headers及延长响应时间。进行跳转页面时都进行捕获异常,只要有异常就调用resolve()。
4.即使做的绕过反爬机制的准备再充足,面对这么庞大的数据爬去也肯定会有各种因素导致的中断,如果爬了几天的数据忽然中断了,再继续只能重头开始的话人真的会崩溃。虽然只是交给机器来操作是机器花了这么久的功夫,但是我们花时间等也是挺废精力的哈哈哈。所以这里也要写一个断点续传的功能,从中断处开始继续爬取(代码中注释明显可一眼找到)。
代码实现
import random
import time
import requests
import os
from bs4 import BeautifulSoup
random.seed(int(time.time()))
def resolve(url, headers_list):
for i in range(5): # 循环去请求网站
headers = random.choice(headers_list)
response = requests.get(url, headers=headers, timeout=20)
if response.status_code == 200:
break
return response
save_root = "/home/alpha/桌面/results"
url = "https://www....."
# headers = {
# "user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
# }
headers_list = [
{
# "Cookie":r"open_link_uuid=283daf44-d04e-49ae-bb47-3b8117d9e71f;utrace=23F72A5EEEB2DAFA0537A35D6848F563;Hm_lvt_8b53bc0f3e59f56a58a92a894280e28d=1693984791;open_link_uuid=47e1a39d-224f-4c45-b1a5-a6bdb84dce5b;Hm_lvt_8bb61372f543ea81f53e93693c2a7531=1694144572;Hm_lpvt_8b53bc0f3e59f56a58a92a894280e28d=1694425881",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.76'
}, {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0'
}, {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0'
}, {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:88.0) Gecko/20100101 Firefox/88.0'
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.202.400 QQBrowser/11.9.5355.400'
}, {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Mobile Safari/537.36'
}
]
headers = random.choice(headers_list)
try:
response = requests.get(url=url, headers=headers)
except:
response = resolve(url, headers_list)
soup = BeautifulSoup(response.text, 'html.parser')
div_yslist_dq = soup.find('div', class_='yslist_dq')
first_dl = div_yslist_dq.find('dl')
a_tags_1 = first_dl.find_all('a')
for a_tag_1 in a_tags_1: # 一级科室
href_1 = a_tag_1.get('href')
title_1 = a_tag_1.text
##############################
# 中断 从断点继续
# if title_1 in ["内科", "外科"]:
# continue
##############################
# print(f'链接地址: {href_1}, 标题: {title_1}')
first_level = os.path.join(save_root, title_1)
if not os.path.exists(first_level):
os.mkdir(first_level)
url = "https://www.youlai.cn" + href_1
headers = random.choice(headers_list)
try:
response = requests.get(url=url, headers=headers)
except:
response = resolve(url, headers_list)
soup = BeautifulSoup(response.text, 'html.parser')
div_yslist_dq = soup.find('div', class_='yslist_dq')
first_dl = div_yslist_dq.findAll('dl')[1]
a_tags_2 = first_dl.find_all('a')
for a_tag_2 in a_tags_2: # 二级科室
href_2 = a_tag_2.get('href')
title_2 = a_tag_2.text
if title_2 == "全部":
continue
##############################
# 中断 从断点继续
# if title_2 in ["消化内科", "心血管内科"]:
# continue
###############################
# print(f'链接地址: {href_2}, 标题: {title_2}')
sec_level = os.path.join(first_level, title_2)
if not os.path.exists(sec_level):
os.mkdir(sec_level)
# input()
url = "https://www.youlai.cn" + href_2
headers = random.choice(headers_list)
try:
response = requests.get(url=url, headers=headers)
except:
response = resolve(url, headers_list)
soup = BeautifulSoup(response.text, 'html.parser')
div_yslist_dq = soup.find('div', class_='yslist_dq')
first_dl = div_yslist_dq.findAll('dl')[2]
a_tags_3 = first_dl.find_all('a')
for a_tag_3 in a_tags_3: # 疾病筛选
href_3 = a_tag_3.get('href')
title_3 = a_tag_3.text
##############################
# 中断 从断点继续
# if title_3 in ["胃炎", "胃溃疡", "肝硬化", "便秘", "肠胃炎", "腹痛", "慢性腹泻", "胰腺炎", "消化不良", "慢性胃炎", "反流性食管炎"]:
# continue
##############################
if title_3 == "全部":
continue
# print(f'链接地址: {href_3}, 标题: {title_3}')
third_level = os.path.join(sec_level, title_3)
if not os.path.exists(third_level):
os.mkdir(third_level)
# print(href_3)
url = "https://www.youlai.cn" + href_3
headers = random.choice(headers_list)
try:
response = requests.get(url=url, headers=headers)
except:
response = resolve(url, headers_list)
soup = BeautifulSoup(response.text, 'html.parser')
page_num = soup.find('div', class_='pageyl').findAll("li")[-2].text
# print(page_num)
# input()
for page in range(eval(page_num)): # 遍历所有页数
##############################
# 中断 从断点继续
# print(page + 1)
# if title_3 == "结肠炎" and page in [0, 1, 2]:
# page_url = "https://www.youlai.cn" + "/ask/voicelist/1_12_12_0_4.html"
# headers = random.choice(headers_list)
# try:
# response = requests.get(url=page_url, headers=headers)
# except:
# response = resolve(page_url, headers_list)
# soup = BeautifulSoup(response.text, 'html.parser')
# continue
##############################
# 默认在第一页
div_yslist_dq = soup.find('ul', class_='cur05')
a_tags_4 = div_yslist_dq.findAll('a')
for a_tag_4 in a_tags_4: # 遍历每页的所有mp3
href_4 = a_tag_4.get('href')
title_4 = a_tag_4.text
# print(f'链接地址: {href_4}, 标题: {title_4}')
url = "https://www.youlai.cn" + href_4
headers = random.choice(headers_list)
try:
response_4 = requests.get(url=url, headers=headers)
except:
response_4 = resolve(url, headers_list)
soup_4 = BeautifulSoup(response_4.text, 'html.parser')
mp3_tag = soup_4.find('audio')
mp3_path = mp3_tag.get("src").strip()
# while True:
# try:
# print(response_4.status_code)
# print(mp3_tag)
# mp3_path = mp3_tag.get("src").strip()
# break
# except AttributeError:
# print(headers)
# headers = random.choice(headers_list)
# time.sleep(5)
# print(headers)
headers = random.choice(headers_list)
try:
mp3_content = requests.get(url=mp3_path, headers=headers).content
except:
mp3_content = resolve(mp3_path, headers_list)
mp3_title = soup_4.find('h3', class_='v_title').text.strip()
print(mp3_title)
if mp3_title[-1] == "?":
mp3_title = mp3_title[:-1]
doc_name = soup_4.find("ul", class_='mgBottom10').find("strong").text.strip()
with open(third_level + "/" + doc_name + "-" + mp3_title + ".mp3", mode="wb") as f1: # 下载每个mp3文件
f1.write(mp3_content)
print(mp3_path)
mp3_text = soup_4.find('div', class_='v_con').find('div', class_='text').text.strip() + "\n"
with open(third_level + "/" + "content.txt", mode="a") as f2:
mp3_title = doc_name + "-" + mp3_title + "\n"
f2.write(mp3_title)
f2.writelines(mp3_text)
print(mp3_text)
# 点击下一页
next_page = soup.find('div', class_='pageyl').findAll("li")[-1]
next_page_title = next_page.text
print(next_page_title)
if not next_page_title == "下一页":
continue
next_page_href = next_page.find("a").get("href")
print(next_page_href)
page_url = "https://www.youlai.cn" + next_page_href
headers = random.choice(headers_list)
try:
response = requests.get(url=page_url, headers=headers)
except:
response = resolve(page_url, headers_list)
soup = BeautifulSoup(response.text, 'html.parser')
实现效果