Raft协议图解,缺陷以及优化
结点的状态
每个结点可以有三种状态:Follower,Candidate,Leader。所有的结点都是从Follower状态开始的
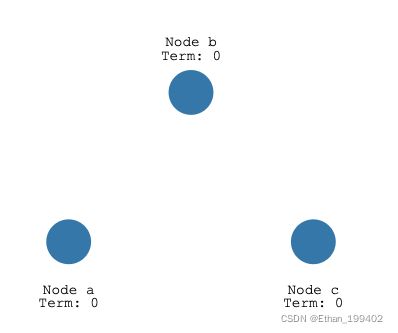
如果followers没有收到leader的RPC消息(心跳超时),则可以转换为candidate,如下图node a,Term表示任期
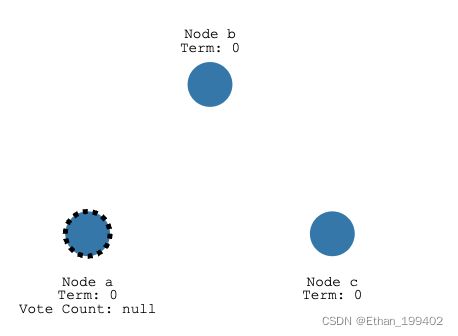
而candidate需要发起投票,其他结点参与投票,回复他们的投票结果,如果这个candidate获得了大部分(过半)的选票,就可以成为leader结点了。这就是Leader Election过程。
选举机制
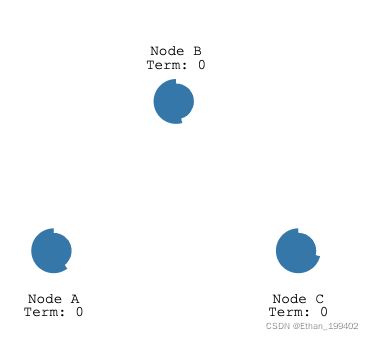
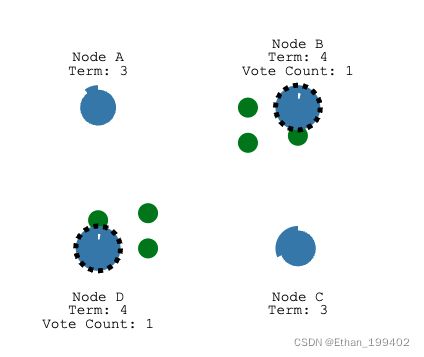
每个节点随机一个选举超时时间,而这个选举超时就是追随者等待成为候选人的时间。上文说到如果followers没有收到leader的RPC消息(心跳超时)并且达到选举超时时间,则可以转换为candidate,但是当不存在leder的时候比如服务刚启动,每一个Follower的选举超时都会随机在 150 毫秒到 300 毫秒之间。如下图,node B的超时时间更短一点
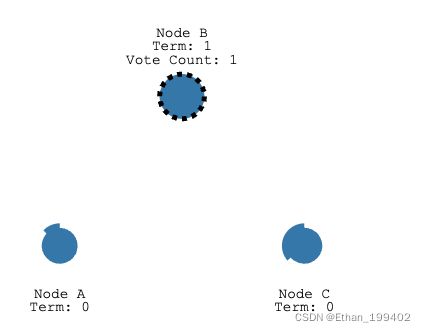
选举超时后,B成为candidate并开始新的选举任期Term为1,首先会投给自己一票,并向其他节点发送请求投票消息
如果接收节点在这个任期内还没有投票(只能投一票),那么它会投票给候选人并重置自己的选举超时,此时所有节点的Term都为1
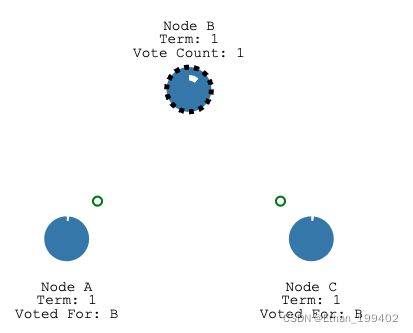
然后node B作为leader指定间隔发送心跳给Follower,Follower只要收到心跳就会重置自己的选举超时
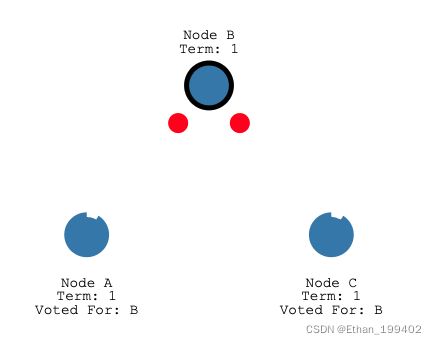
如过某种原因超时时间内都没有收到leader心跳,则该Follower作为candidate发起下一轮选举,Term+1.下图以leder故障为例,心跳超时之后,node A(更短的选举超时时间)先成为candidate并发起投票成为新的leader
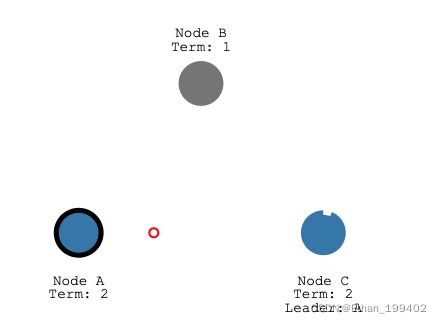
当出现网络分区,因为CDE与AB发生了隔离,CED重新选举E为leader,原来的leaderB则继续领导者A,那么就出现了两个leader B和E,注意此时CDE是处于第二任期的
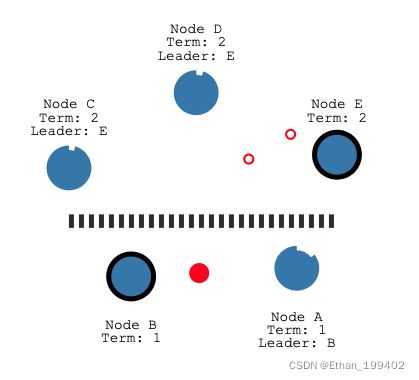
当网络分区修复,节点 B 将看到节点C更高的选举期限并下台成为Follower,统一更新Term为2
选举原则
那么如果保证选举过程的正确性呢?
- 每个节点,对每个任期(trem)只能投出一张票.
- 收到选举请求后,如果该请求的事务日志编号小于自己的机器,那么就不会投票. 保证新的leader拥有更新的数据
- 收到选举请求后,如果该选举编号(term)小于自己的term,那么就不会投票. 旧时代的残党不能上新时代的船
- 当一台机器收到多数投票,代表选举成功成为新的leader.
遵循以上原则还有什么问题呢?
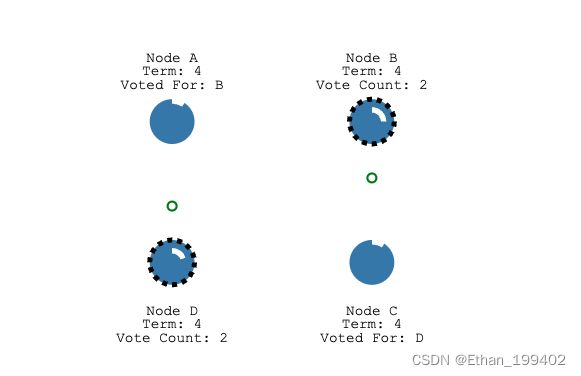
1.因为每个节点每个任期只能投一票,而成为leader的条件是获得多数选票,如果两个节点都开始同一任期的选举
恰好获得了同样的多的选票,并且规定时间内不能再获得更多
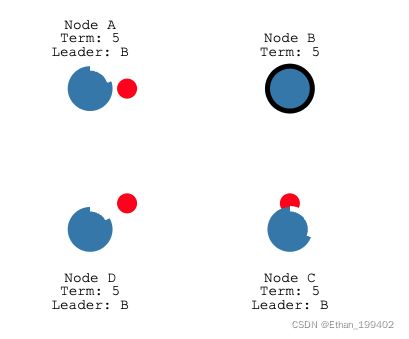
那么选举失败,节点将重置自己的选举超时,作为Follower重新下一轮竞争,直到出现在一个leader为止
2.注意一个点.当集群中一个节点出现网络分区.
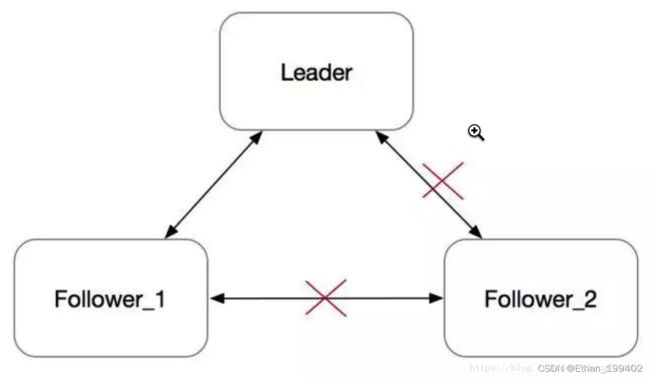
Follower_2在electionTimeout没收到心跳之后,会发起选举,并转为Candidate。每次发起选举时,会把Term加一。由于网络隔离,它既不会被选成Leader,也不会收到Leader的消息,而是会一直不断地发起选举。Term会不断增大。
一段时间之后,这个节点的Term会非常大。在网络恢复之后,这个节点会把它的Term传播到集群的其他节点,导致其他节点更新自己的term,变为Follower。然后触发重新选主,但这个旧的Follower_2节点由于其日志不是最新,并不会成为Leader。整个集群被这个网络隔离过的旧节点扰乱,显然需要避免的。
preVote阶段优化
Raft作者博士论文《CONSENSUS: BRIDGING THEORY AND PRACTICE》的第9.6节 "Preventing disruptions when a server rejoins the cluster"提到了PreVote算法的大概实现思路。
在PreVote算法中,Candidate首先要确认自己能赢得集群中大多数节点的投票,这样才会把自己的term增加,然后发起真正的投票。其他投票节点同意发起选举的条件是(同时满足下面两个条件):
- 没有收到有效领导的心跳,至少有一次选举超时。
- Candidate的日志足够新
日志足够新怎么判断
- Term更大,此时要与Basic Raft算法区分开来,后者会不断增加Term,而前者首先要确认自己能赢得集群中大多数节点的投票,这样才会把自己的term增加
- Term相同raft index更大。
PreVote算法解决了网络分区节点在重新加入时,会中断集群的问题。在PreVote算法中,网络分区节点由于无法获得大部分节点的许可,因此无法增加其Term。然后当它重新加入集群时,它仍然无法递增其Term,因为其他服务器将一直收到来自Leader节点的定期心跳信息。一旦该服务器从领导者接收到心跳,它将返回到Follower状态,Term和Leader一致。
关于超时
1.心跳超时后,Follower 等待自身选举超时后成为 Candidate 身份并发起竞选。raft 使用了一个叫随机选举超时(randomize election timeout)的方式,使每个 server 的超时时间不一样,这样就避免了多个 Candidate 同时发起竞选的问题。
2.竞选也有时限,规定时间内没有获取到足够多的票数或者票数相当,则当前 Leader 竞选失败;
3.心跳超时可以自己配置,看你自己的网络规模和拓扑;选举超时是随机的,150 毫秒到 300 毫秒之间;通常情况下,心跳超时比选举超时长得多,心跳是秒级,选举是毫秒级。
4.Follower 检测到心跳超时后,是在等待自身选举超时后发起竞选的
日志复制
所有的请求都需要先经过leader结点,每一条leader会把它作为一个log entry,添加到节点的日志里,log现在还没有提交,所以不会修改结点的值,而是先给其它的server发AppendEntriesRPC,leader结点会等待直到大部分结点修改了他们的entry,然后log可以被提交了,值也会被修改,然后leader会告诉其他结点entry提交了,其他节点执行相同的操作,这样,所有结点保持了一致性
正常情况:
- client向leader发出一个添加请求
- leader写入appendEntryLog.并标记为uncommit状态.
- 调用appendEntryRpc,拷贝日志项到follower.
- follower接收到日志项,并append到本机.返回给leader success
- leader收到success后,将日志置为committed状态.并apply到状态机.返回给client success.
同样的如果出现了网络分区(network partitions)呢?
则会出现两个leader的情况,小分区的nodes的日志不会被提交,因为这个分区的leader得不到大部分nodes的回复(相对于整个系统来说),当解决了分区问题,则这个小分区的nodes首先会滚未提交的日志,再重新根据大分区leader的日志来保持一致性。
如果follower没有响应成功呢?
当拷贝到follower,follower没有响应成功时,有可能是没有拷贝过去,也有可能ack丢失了. leader会不断重试,直到满足过半. 当然这时候,client可能会超时.这条日志可能最后会丢失,也可能会committed,客户端需要实现幂等
raft算法的缺陷
Raft 必须“顺序投票”,不允许日志中出现空洞。
- Leader 收到客户端的请求。
- Leader 将请求内容(即 Log Entry)追加(Append)到本地的 Log。
- Leader 将 Log Entry 发送给其他的 Follower。
- Leader 等待 Follower 的结果,如果大多数节点提交了这个 Log,那么这个 Log Entry 就是 Committed Entry,Leader 就可以将它应用(Apply)到本地的状态机。
- Leader 返回客户端提交成功。
- Leader 继续处理下一次请求。
问题是当一连串事务并行执行时,只要有一个事务没有得到超过半数的响应,这时 Leader 必须等待一个明确的失败信号,比如通讯超时,才能结束这次操作,否则就会一直阻塞接下来的事务处理
同样的情况也会发生在 Follower 节点上,第一个 Follower 节点可能由于网络原因没有收到 T2 事务的日志,即使它先收到 T3 的日志,也不会执行 Append 操作,因为这样会使日志出现空洞。
Raft 的顺序投票是一种设计上的权衡,虽然性能有些影响,但是节点间日志比对会非常简单。在两个节点上,只要找到一条日志是一致的,那么在这条日志之前的所有日志就都是一致的。这使得选举出的 Leader 与 Follower 同步数据非常便捷,开放 Follower 读操作也更加容易。要知道,我说的可是保证一致性的 Follower 读操作,它可以有效分流读操作的访问压力。
性能优化方法
缺点:顺序投票,只能串行apply,因此高并发场景下性能差。
- 批操作(Batch)。Leader 缓存多个客户端请求,然后将这一批日志批量发送给 Follower。Batch 的好处是减少的通讯成本。牺牲了写操作的耗时
- 流水线(Pipeline)。Leader 本地增加一个变量(称为 NextIndex),每次发送一个 Batch 后,更新 NextIndex 记录下一个 Batch 的位置,然后不等待 Follower 返回,马上发送下一个 Batch。如果网络出现问题,Leader 重新调整 NextIndex,再次发送 Batch。当然,这个优化策略的前提是网络基本稳定。
- 并行追加日志(Append Log Parallelly)。Leader 将 Batch 发送给 Follower 的同时,并发执行本地的 Append 操作。因为 Append 是磁盘操作,开销相对较大,而标准流程中 Follower 与 Leader 的 Append 是先后执行的,当然耗时更长。改为并行就可以减少部分开销。当然,这时 Committed Entry 的判断规则也要调整。在并行操作下,即使 Leader 没有 Append 成功,只要有半数以上的 Follower 节点 Append 成功,那就依然可以视为一个 Committed Entry,Entry 可以被 Apply。
- 异步应用日志(Asynchronous Apply)。Apply 并不是提交成功的必要条件,任何处于 Committed 状态的 Log Entry 都确保是不会丢失的。Apply 仅仅是为了保证状态能够在下次被正确地读取到,但多数情况下,提交的数据不会马上就被读取。因此,Apply 是可以转为异步执行的,同时读操作配合改造. 这里是牺牲了读取的一致性了
更多异常情况解析
参考:
http://thesecretlivesofdata.com/raft/
https://blog.csdn.net/u012997470/article/details/109966513